







 本文介绍了如何配置Linux Redis以允许远程访问,包括解除bind限制、关闭保护模式、启用守护进程以及防火墙设置。接着,详细讨论了使用redis-py库进行连接,包括普通连接、连接池、管道和发布订阅操作。通过管道实现批量命令执行,提升读写效率,并展示了发布订阅模式在消息传输中的应用。
本文介绍了如何配置Linux Redis以允许远程访问,包括解除bind限制、关闭保护模式、启用守护进程以及防火墙设置。接着,详细讨论了使用redis-py库进行连接,包括普通连接、连接池、管道和发布订阅操作。通过管道实现批量命令执行,提升读写效率,并展示了发布订阅模式在消息传输中的应用。
一,准备远程访问工作
-
Redis开启远程访问
- 将bind 127.0.0.1注释
- protected-mode 改为no
- daemonize 改为yes
-
将Linux防火墙关掉(如下常用命根据情况参考)
- 关闭防火墙命令:systemctl stop firewalld.service
- 开启防火墙:systemctl start firewalld.service
- 关闭开机自启动:systemctl disable firewalld.service
- 开启开机启动:systemctl enable firewalld.service
-
如果关闭防火墙不好使则用如下方法
-
安装iptables
-
yum install iptables-services
-
开放端口 vim /etc/sysconfig/iptables
-A INPUT -m state --state NEW -m tcp -p tcp dport 80 -j ACCEPT #开放端口 -A INPUT -m state --state NEW -m tcp -p tcp dport 6379 -j ACCEPT #开放端口 -A INPUT -m state --state NEW -m tcp -p tcp dport 3306 -j ACCEPT #开放端口 -I INPUT -s 113.106.93.110 -p tcp --dport 8089 -j DROP #禁止指定IP访问 8089 -I INPUT -s 113.106.93.110 -p tcp --dport 8080 -j ACCEPT #开放固定ipIP访问 8080 -
执行 /etc/init.d/iptables restart 命令将iptables服务重启
-
执行/etc/rc.d/init.d/iptables save
-
二,Redis的API使用
redis-py的API的使用可以分类为:
- 连接方式
- 普通连接
- 连接池
- 操作
- String/Hash/List/Set/Sort Set操作
- 管道
- 发布订阅
-
连接方式
-
普通连接
#确保安装redis第三方模块 #pip3 install redis #yum install redis import redis #普通连接,此种连接是连接一次就断了,耗资源,端口默认6379,可以不用写 conn = redis.StrictRedis(host="192.168.124.129",port=6379,password="") conn.set("key1","value1",ex=5) #ex代表seconds px代表ms conn.set('usr','root') val = conn.get("key12") usr_name = conn.get('usr').decode('utf8) #print(val) -
连接池
#连接池 redis-py使用ConnectionPool管理对一个redis server的所有连接,避免每次建立,减少多次连接带来的消耗。默认每个redis实例都会维护一个自己的连接池。可以直接建立一个连接池,然后作为参数redis,这样就可以实现多个redis实例共享一个连接池。 #当程序创建数据源实例时,系统会一次性创建多个数据库连接,并把这些数据库连接保存在连接池中,当程序需要进行数据库访问时,无需重新新建数据库连接,而是从连接池中取出一个空闲的数据库连接 #调用完成之后,该链接将会返还给连接池,供其他连接请求调用,这样将减少大量redis连接的执行时间 #默认设置的值和取得的值都是bytes类型,如果想成为str类型,可以添加decode_response = True import redis pool = redis.ConnectionPool(host="192.168.124.129",password="",decode_response = True) #实现一个连接池 conn = redis.StrictRedis(connection_pool=pool) conn.lpush("key3",23,446,67567,3242) print(conn.lpop("key3")) -
sentinel集群连接并操作(哨兵机制)
from redis.sentinel import Sentinel #sentinel的地址和端口号 sentinel = Sentinel([('localhost', 26380)], socket_timeout=0.1) #测试,获取以下主库和从库的信息 sentinel.discover_master('mymaster') sentinel.discover_slaves('mymaster') #配置读写分离,写节点 master = sentinel.master_for('mymaster', socket_timeout=0.1,password="123") #读节点 slave = sentinel.slave_for('mymaster', socket_timeout=0.1,password="123") #读写分离测试 master.set('oldboy', '123') print(slave.get('oldboy')) -
python连接redis cluster集群测试
from rediscluster import StrictRedisCluster startup_nodes = [{"host": "127.0.0.1", "port": "7000"},{"host": "127.0.0.1", "port": "7001"},{"host": "127.0.0.1", "port": "7002"}] rc = StrictRedisCluster(startup_nodes=startup_nodes, decode_responses=True) rc.set("foo0000", "bar0000") print(rc.get("foo0000"))
-
-
管道(详讲)
-
redis-py默认在执行每次请求都会创建(连接池申请连接)和断开(归还连接池)一次连接操作,如果想要在一次请求中指定多个命令,则可以使用pipline实现一次请求指定多个命令,并且默认情况下pipline是原子性操作。
-
管道是redis的子类,它支持在一个请求中款冲多个命令到服务器
-
管道使redis的读写速度更加的快速。秒级取值1000+的数据。
-
经过线上实测,利用pipeline取值3500条数据,大约需要900ms,如果配合线程or协程来使用,每秒返回1W数据是没有问题的,基本能满足大部分业务。
-
pipe = con.pipeline(transaction=False) #集群模式下管道不开启原子性 #pipeline(transaction=True)管道开启原子的(失败一个全部失败),返回一个新的管道对象,该对象可以将多个命令排队稍后执行。可以减少客户端与服务端的开销,但是如果组装过大会占用网络阻塞。 #可以缓冲多个命令,也可以写在一起 pipe.set('hello',"redis").sadd("faz",'sdf').incr("num").execute() print(r.get('name'))
-
-
发布订阅(详讲)
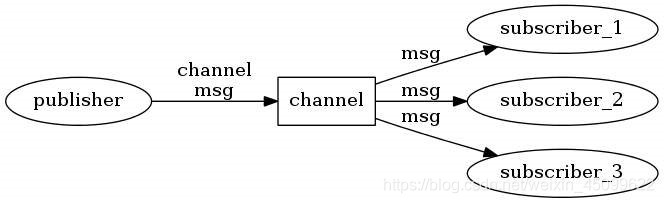
- Redis 发布订阅(pub/sub)是一种消息通信模式:发送者(pub)发送消息,订阅者(sub)接收消息。
- Redis 客户端可以订阅任意数量的频道。
- Redis提供了发布订阅功能,可以用于消息的传输,Redis的发布订阅机制包括三个部分,发布者,订阅者和Channel。
- 发布者和订阅者都是Redis客户端,Channel则为Redis服务器端,发布者将消息发送到某个的频道,订阅了这个频道的订阅者就能接收到这条消息。Redis的这种发布订阅机制与基于主题的发布订阅类似,Channel相当于主题。

















 3104
3104

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









