







 本文详细介绍了RabbitMQ的五种消息模型:一对一简单模式、work模式、发布/订阅模式、路由模式(direct模式)和Topic模式。重点讨论了每种模式的概念、工作原理、优缺点以及代码实现,帮助理解如何在不同场景下选择合适的消息模型。
本文详细介绍了RabbitMQ的五种消息模型:一对一简单模式、work模式、发布/订阅模式、路由模式(direct模式)和Topic模式。重点讨论了每种模式的概念、工作原理、优缺点以及代码实现,帮助理解如何在不同场景下选择合适的消息模型。
rabbitMQ提供了6种消息模型,但是第六种其实是RPC(远程过程调用),并不是MQ,所以是5种模式。
其中5种消息模型分为两类:
- 第一种和第二种是点对点
- 第三,四,五种是一对多,都属于订阅模型,只不过是进行路由的方式不同。
- 第六种RPC远程调用也可不算做模式
本文参照网站:https://www.rabbitmq.com/getstarted.html
一,一对一简单模式

-
概念
- 生产者将消息发送到“ hello”队列。使用者从该队列接收消息。
-
图解
-
“ P”是我们的生产者
-
“ C”是我们的消费者
-
中间的框是一个队列-RabbitMQ代表使用者保留的消息缓冲区。
-
-
发送信息
import pika #连接主机 conn = pika.BlockingConnection(pika.ConnectionParameters('localhost')) channel = connection.channel() #发送信息 #如果队列不存在就先创建一个队列 channel.queue_declare(queue = 'hello') #把信息放入指定队列 channel.basic_publish(exchange = ``, routing_key = 'hello', body = “世界你好!” ) print(“ [x]发送'Hello World!'”) connection.close()-
exchange有几种交换类型可用:direct,topic,headers 和fanout。
#比如fanout它只是将接收到的所有消息广播到它知道的所有队列中 channel.exchange_declare(exchange='logs',exchange_type='fanout') #连接默认交换机 #channel.exchange_declare(exchange='',exchange_type='fanout') -
查看服务器上的交换机:sudo rabbitmqctl list_exchanges
- 其中有一些是默认创建的交换机
-
查看队列绑定情况:rabbitmqctl list_bindings
-
创建临时队列:
res = channel.queue_declare(queue = '',Exclusive = True) #Exclusive = True一旦使用者连接关闭,则应删除队列。 -
如果发送失败,可能是磁盘空间不足,默认情况下,rabbitmq需要200MB的可用空间,可以尝试检查代理日志文件以确认并减少限制,rabbitmq.conf配置具体配置可点此处
-
-
接收信息
import pika #连接主机 conn = pika.BlockingConnection(pika.ConnectionParameters('localhost')) channel = connection.channel() #以防没有队列则重新创建 channel.queue_declare(queue = 'hello') #接收消息通过将callback函数订阅到队列来工作 #每当我们收到消息时,Pika库都会调用此callback函数 def callback(ch, method, properties, body): print(" [x] Received %r" % body) #接下来要告诉rabbitMQ这个callback函数应该从hello队列接收消息 channel.basic_consume( queue='hello', on_message_callback=callback, auto_ack=True) print(' [*] Waiting for messages. To exit press CTRL+C') channel.start_consuming()- 队列接收消息过程:
- 通过将callback函数订阅到队列来工作
- 每当我们收到消息时,Pika库都会调用此callback函数
- 接下来要告诉rabbitMQ这个callback函数应该从hello队列接收消息
- 查看RabbitMQ的队列以及队列中有多少条消息:sudo rabbltmqctl list_queues
- 队列接收消息过程:
二,work模式

-
概念
- work模式是一个生产者,一个队列,多个消费者,每个消费者获取到的消息唯一,多个消费者只有一个队列
-
优点及作用
- 一个生产者一个队列多个消费者模式能够并行化工作
- 解决了消息积压问题
-
工作原理
- 默认情况下,RabbitMQ将每个消息按顺序发送给下一个使用者。平均而言,每个消费者都会收到相同数量的消息。这种分发消息的方式称为循环。与三个或更多的工人一起尝试
-
如果工人工作中突然死亡或者断网:
-
如果使用者在不发送确认的情况下死亡(其通道已关闭,连接已关闭或TCP连接丢失),RabbitMQ将了解消息未得到充分处理,并将重新排队发送。确认必须在收到交货的同一通道上发送。如果尝试使用其他通道进行确认将导致通道级协议异常。如果同时有其他消费者在线,它将很快将其重新分发给另一个消费者。这样,就可以确保即使工人偶尔死亡也不会丢失任何消息。如果未进行处理RabbitMQ将消耗越来越多的内存,因为它将无法释放任何未确认的消息。
-
为了调试这种错误可以打印messages_unacknowledged字段:
sudo rabbitmqctl list_queues name messages_ready messages_unacknowledged
-
-
消息及队列持久化
-
解决办法: 将队列和消息都标记为持久性。
-
解决步骤:
-
确保该队列将在RabbitMQ节点重启后继续存在。为此,我们需要将其声明为持久的:
#如果设置持久化之前存在该队列则不起作用 channel.queue_declare(queue='hello', durable=True) -
通过提供值为2的delivery_mode属性将消息标记为持久性
channel.basic_publish(exchange = '', routing_key = “ task_queue”, body = message, properties = pika.BasicProperties( delivery_mode = 2,#使消息持久化 ))-
有关消息持久性的说明
将消息标记为持久性并不能完全保证不会丢失消息。尽管它告诉RabbitMQ将消息保存到磁盘,但是RabbitMQ接受消息但尚未将其保存时,仍有很短的时间。另外,RabbitMQ不会对每条消息都执行fsync(2)-它可能只是保存到缓存中,而没有真正写入磁盘。持久性保证并不强,但是对于我们的简单任务队列而言,这已经绰绰有余了。如果您需要更强有力的保证,则可以使用 发布者确认。
-
-
-
-
任务派遣
-
工作有轻有重一个人忙碌一个工人几乎没有工作,是因为什么?
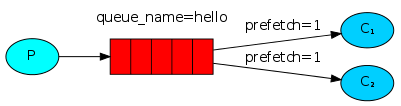
-
因为RabbitMQ在消息进入队列时才调度消息。它不会查看使用者的未确认消息数。它只是盲目地将每第n条消息发送给第n个使用者。
-
解决办法:
#在处理并确认上一条消息之前,不要将新消息发送给工作人员。而是将其分派给不忙的下一个工作程序。 channel.basic_qos(prefetch_count = 1)
-
-
派发任务代码
import pika import sys connection = pika.BlockingConnection( pika.ConnectionParameters(host='localhost')) channel = connection.channel() channel.queue_declare(queue='task_queue', durable=True) message = ' '.join(sys.argv[1:]) or "Hello World!" channel.basic_publish( exchange='', routing_key='task_queue', body=message, properties=pika.BasicProperties( delivery_mode=2, # make message persistent )) print(" [x] Sent %r" % message) connection.close() -
work模式代码
import pika import time connection = pika.BlockingConnection( pika.ConnectionParameters(host='localhost')) channel = connection.channel() channel.queue_declare(queue='task_queue', durable=True) print(' [*] Waiting for messages. To exit press CTRL+C') def callback(ch, method, properties, body): print(" [x] Received %r" % body) time.sleep(body.count(b'.')) print(" [x] Done") ch.basic_ack(delivery_tag=method.delivery_tag) channel.basic_qos(prefetch_count=1) channel.basic_consume(queue='task_queue', on_message_callback=callback) channel.start_consuming()
-
三,发布/订阅模式
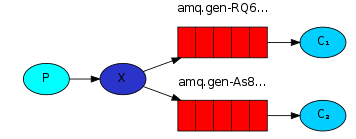
-
概念:
- 和模式二不同的是,模式三是一个生产者、一个交换机、多个队列、多个消费者
-
在模式二中提到过交换机的四种类型
-
direct:
-
所有发送到Direct Exchange的消息被转发到routing_key指定的队列中
-
消息传递时,routing_key必须完全匹配才会被队列接收,否则消息会被抛弃
-
direct模式可以使用RabbitMQ自带的默认交换机,所以不需要将交换机进行任何绑定操作
-
-
topic:
-
使用通配符进行模糊匹配
- 符号“#”匹配一个或多个词
eg:" log.# "能够匹配到‘ log.info.oa ’ - 符号“ * ” 匹配不多不少一个词
eg:“ log.* ”只能匹配到“log.erro”
- 符号“#”匹配一个或多个词
-
-
headers: 不常用,不予介绍
-
fanout : 将接收到的所有消息广播到它知道的所有队列中
- 如果routing_key 有指定也不会生效
-
-
使用步骤
#创建交换机 channel.exchange_declare(exchange='logs',exchange_type='fanout') #创建临时队列 result = channel.queue_declare(queue='', exclusive=True) #绑定队列 channel.queue_bind(exchange='logs',queue=result.method.queue)-
如果要将日志保存到文件,只需打开控制台并键入:
python receive_logs.py> logs_from_rabbit.log
-
-
与第二种work模式区别:
- 第三种发布订阅将消息发布到有名的交换器,而不是无名默认的交换机上
- 第三种需要交换机绑定队列
-
完整代码:
import pika connection = pika.BlockingConnection( pika.ConnectionParameters(host='localhost')) channel = connection.channel() channel.exchange_declare(exchange='logs', exchange_type='fanout') result = channel.queue_declare(queue='', exclusive=True) queue_name = result.method.queue channel.queue_bind(exchange='logs', queue=queue_name) print(' [*] Waiting for logs. To exit press CTRL+C') def callback(ch, method, properties, body): print(" [x] %r" % body) channel.basic_consume( queue=queue_name, on_message_callback=callback, auto_ack=True) channel.start_consuming()
四,路由模式(自称direct模式)
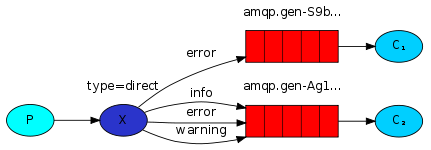
-
概念:
- 交换机连接接队列发送消息需要指定routing_key,所以模式四就是生产者发送消息到交换机并且要指定routing_key,消费者将队列绑定到交换机时需要指定路由key
- 注意:rabbitMQ是可以同时
-
算法
-
背后的路由算法很简单:消息进入他绑定密钥与消息的routing_key完全匹配的队列 。
-
图片说明:
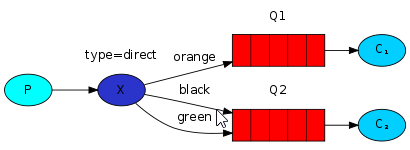
-
在direct模式中,第一个队列由绑定密钥为orange绑定,第二个队列由绑定密钥为black和green绑定
-
如果有消息没有使用存在的绑定密钥的消息将会被丢弃。
-
用相同的绑定密钥可以绑定多个队列
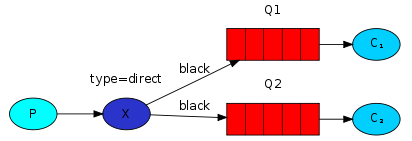
-
-
使用方法:
-
和前三种不同的是交换机的类型要换成direct
channel.exchange_declare(exchange='direct_logs', exchange_type='direct') -
将绑定的其中一个队列为severity,发送消息
channel.basic_publish(exchange='direct_logs', routing_key=severity, body=message) -
接收消息需要创建routing_key绑定
result = channel.queue_declare(queue='', exclusive=True) queue_name = result.method.queue for severity in severities: channel.queue_bind(exchange='direct_logs', queue=queue_name, routing_key=severity)
-
-
完整代码
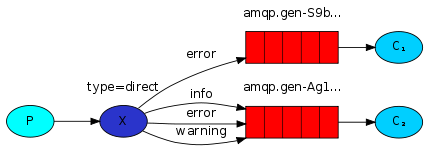
#发送信息 import pika import sys connection = pika.BlockingConnection( pika.ConnectionParameters(host='localhost')) channel = connection.channel() channel.exchange_declare(exchange='direct_logs', exchange_type='direct') severity = sys.argv[1] if len(sys.argv) > 1 else 'info' message = ' '.join(sys.argv[2:]) or 'Hello World!' channel.basic_publish( exchange='direct_logs', routing_key=severity, body=message) print(" [x] Sent %r:%r" % (severity, message)) connection.close() #接收信息 import pika import sys connection = pika.BlockingConnection( pika.ConnectionParameters(host='localhost')) channel = connection.channel() channel.exchange_declare(exchange='direct_logs', exchange_type='direct') result = channel.queue_declare(queue='', exclusive=True) queue_name = result.method.queue severities = sys.argv[1:] if not severities: sys.stderr.write("Usage: %s [info] [warning] [error]\n" % sys.argv[0]) sys.exit(1) for severity in severities: channel.queue_bind( exchange='direct_logs', queue=queue_name, routing_key=severity) print(' [*] Waiting for logs. To exit press CTRL+C') def callback(ch, method, properties, body): print(" [x] %r:%r" % (method.routing_key, body)) channel.basic_consume( queue=queue_name, on_message_callback=callback, auto_ack=True) channel.start_consuming() -
缺点:
- 在我们的日志记录系统中,我们可能不仅要根据严重性订阅日志,还要根据发出日志的源订阅日志;
- 它仍然存在局限性,它不能基于多个条件进行路由。那么就产生了下面第五种模式。
五,Topic模式
-
概念
- topic模式的routing_key使用通配符组成进行模糊匹配
- 符号“#”匹配一个或多个词
- eg:" log.# "能够匹配到‘ log.info.oa ’
- 符号“ * ” 只匹配一个词
- eg:“ log.* ”只能匹配到“log.erro”
- 符号“#”匹配一个或多个词
- topic模式的routing_key使用通配符组成进行模糊匹配
-
示例
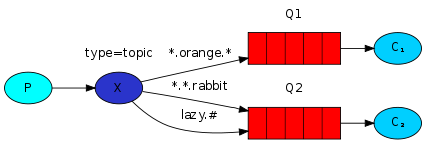
- 使用三个词(两个点)的routing_key 发送消息;
- routing_key设置为“quick.orange.rabbit”的消息将传递到两个队列,消息“ lazy.orange.elephant ”也将发送给他们两个;
- “quick.orange.fox ”只会进入Q1,而“ lazy.brown.fox ”只会进入Q2;
- lazy.pink.rabbit ”将被传递到Q2只有一次,即使两个绑定都匹配;
- “ quick.brown.fox ”与任何绑定都不匹配,因此将被丢弃;
- 如果违反规则只发送一个或者三个以上单词;
- 比如:‘orange’ 和‘quick.orange.male.rabbit’,则不会被匹配
- “ lazy.orange.male.rabbit ”即使有四个单词,也将匹配最后一个绑定,并将其传送到Q2队列。
-
注意:
- 当队列用‘#’绑定时它将接收所有消息,与routing_key无关,此时就像fanout模式一样
- 当绑定中不使用‘*’和‘#’时,主题交换就像direct模式一样。
-
代码示例
#生产者 import pika import sys connection = pika.BlockingConnection( pika.ConnectionParameters(host='localhost')) channel = connection.channel() channel.exchange_declare(exchange='topic_logs', exchange_type='topic') routing_key = sys.argv[1] if len(sys.argv) > 2 else 'anonymous.info' message = ' '.join(sys.argv[2:]) or 'Hello World!' channel.basic_publish( exchange='topic_logs', routing_key=routing_key, body=message) print(" [x] Sent %r:%r" % (routing_key, message)) connection.close() #消费者 receive_logs_topic.py import pika import sys connection = pika.BlockingConnection( pika.ConnectionParameters(host='localhost')) channel = connection.channel() channel.exchange_declare(exchange='topic_logs', exchange_type='topic') result = channel.queue_declare('', exclusive=True) queue_name = result.method.queue binding_keys = sys.argv[1:] if not binding_keys: sys.stderr.write("Usage: %s [binding_key]...\n" % sys.argv[0]) sys.exit(1) for binding_key in binding_keys: channel.queue_bind( exchange='topic_logs', queue=queue_name, routing_key=binding_key) print(' [*] Waiting for logs. To exit press CTRL+C') def callback(ch, method, properties, body): print(" [x] %r:%r" % (method.routing_key, body)) channel.basic_consume( queue=queue_name, on_message_callback=callback, auto_ack=True) channel.start_consuming()- 要接收所有日志运行:python receive_logs_topic.py “#”
- 要从kern接收所有日志:python receive_logs_topic.py “kern.*”
- 如果只想看“critical”日志:python receive_logs_topic.py “*.critical”
- 可以 查看多个日志:python receive_logs_topic.py “kern." ".critical”
- 查看带有routing_key为’kern.critical’的日志类型:python emit_log_topic.py “kern.critical” “A critical kernel error”
六,RPC(远程过程调用)
-
概念
- 有时我们需要在远程计算机上运行功能并且等待结果,这种模式叫做(RPC)远程过程调用
-
使用方法
-
创建一个客户端,并且通过调用call方法去调用我们的服务器,然后实时接收我们服务端处理后返回的结果,显示在控制台。
fibonacci_rpc = FibonacciRpcClient() 结果= fibonacci_rpc.call(4) print(“ fib(4)is%r”%result) #这个方法发送RPC请求并阻塞,直到收到回答为止
-
-
RabbitMQ的RPC模式工作流程
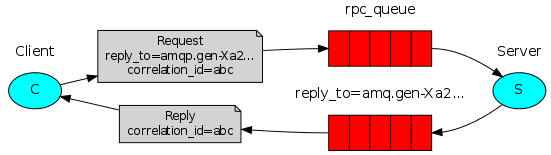
- 生产端和消费端共同约定消费队列和回复队列
- 生产端每次发送消息时指定一个唯一ID,携带回复队列名称和消息发送给消费队列
- 消费者从消费队列获取消息,处理后,将结果和生产端发送过来的唯一ID发送给回复队列
- 生产端从回复队列获取消息和唯一ID,判断ID是否匹配,匹配,则此消息为回复消息。否则就丢弃。
-
RPC缺点
-
rpc调用的方法容易造成系统混乱
-
滥用RPC可能导致无法维护代码
-
-
示例代码
-
rpc_server.py
import pika connection = pika.BlockingConnection( pika.ConnectionParameters(host='localhost')) channel = connection.channel() channel.queue_declare(queue='rpc_queue') def fib(n): if n == 0: return 0 elif n == 1: return 1 else: return fib(n - 1) + fib(n - 2) def on_request(ch, method, props, body): n = int(body) print(" [.] fib(%s)" % n) response = fib(n) ch.basic_publish(exchange='', routing_key=props.reply_to, properties=pika.BasicProperties(correlation_id = \ props.correlation_id), body=str(response)) ch.basic_ack(delivery_tag=method.delivery_tag) #我们可能要运行多个服务器进程。为了将负载平均分配给多个服务器,我们需要设置 prefetch_count设置。 channel.basic_qos(prefetch_count=1) #该回调是RPC服务器的核心。收到请求后执行,完成工作并将响应发送回去 channel.basic_consume(queue='rpc_queue', on_message_callback=on_request) print(" [x] Awaiting RPC requests") channel.start_consuming() -
rpc_client.py
import pika import uuid class FibonacciRpcClient(object): def __init__(self): #我们建立连接,建立频道并声明一个专用的“callback回调队列”以进行答复。 self.connection = pika.BlockingConnection( pika.ConnectionParameters(host='localhost')) self.channel = self.connection.channel() result = self.channel.queue_declare(queue='', exclusive=True) self.callback_queue = result.method.queue #我们订阅“回调”队列,以便我们可以接收RPC响应。 self.channel.basic_consume( queue=self.callback_queue, on_message_callback=self.on_response, auto_ack=True) #对于每个响应消息,它都会检查correlation_id(唯一ID)是否是我们要查找的那个。 def on_response(self, ch, method, props, body): if self.corr_id == props.correlation_id: self.response = body #如果是这样,它将响应保存在self.response中并中断使用循环。 #定义call方法,执行RPC请求 def call(self, n): self.response = None self.corr_id = str(uuid.uuid4()) #生成唯一ID,on_response”回调函数将使用该值来捕获适当的响应。 self.channel.basic_publish( exchange='', routing_key='rpc_queue', #发布具有两个属性的请求消息: reply_to和correlation_id properties=pika.BasicProperties( reply_to=self.callback_queue, correlation_id=self.corr_id, ), body=str(n)) while self.response is None: self.connection.process_data_events() return int(self.response) fibonacci_rpc = FibonacciRpcClient() print(" [x] Requesting fib(30)") #最后,我们将响应返回给用户。 response = fibonacci_rpc.call(30) print(" [.] Got %r" % response) - 如果RPC服务器太慢就运行另一台RPC服务器运行rcp_server.py - 在客户端,RPC只需要发送和接收一条消息,不需要诸如创建队列的调用,所以RPC客户端只需要一个网络往返就可以处理单个RPC请求。 correlation_id=self.corr_id, ), body=str(n)) while self.response is None: self.connection.process_data_events() return int(self.response) fibonacci_rpc = FibonacciRpcClient() print(" [x] Requesting fib(30)") #最后,我们将响应返回给用户。 response = fibonacci_rpc.call(30) print(" [.] Got %r" % response)- 如果RPC服务器太慢就运行另一台RPC服务器运行rcp_server.py
- 在客户端,RPC只需要发送和接收一条消息,不需要诸如创建队列的调用,所以RPC客户端只需要一个网络往返就可以处理单个RPC请求。
-

















 1938
1938

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









