







一,大数据简单介绍
-
大数据的4大特性:
- 数据量巨大:G<T<PB<EB<ZB
- 数据类型多样
- 价值密度低,商业价值高
- 速度要求快,输入输出,计算速度要求快
-
常见的分布式文件存储系统
- GFS(Google File System):擅长处理单个大文件
- HDFS(Hadoop Distributed Filesystem):擅长处理单个大文件
- ClusterFS:集群文件存储系统,去中心化设计,擅长处理单个大文件,流媒体
- TFS(Taobao Filesystem):淘宝开源的文件系统,擅长处理小文件,适用于大规模场景。将原数据存储于关系型数据库或其他高性能存储中,从而维护海量文件元数据。
二,初识Hadoop
-
基本概念:
- Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS。
-
核心组件:
- HDFS(分布式文件系统):解决海量数据存储
- YARN(作业调度和集群资源管理的框架):解决资源任务调度
- MAPREDUCE(分布式运算编程框架):解决海量数据计算
-
HDFS为海量的数据提供了存储
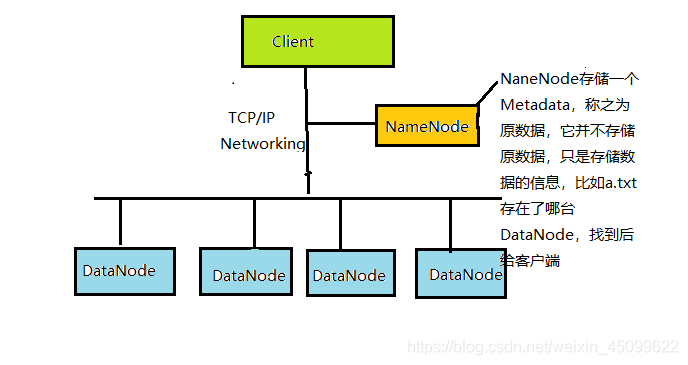
-
HDFS优点
- 高容错性
- 后台可以配置数据自动保存多个副本
- 副本丢失后,自动同步恢复
- 适合批处理
- 移动计算而非移动数据(计算向数据靠拢)
- 数据位置暴露给计算框架
- 注意:批处理不是实时的,会有一定的延迟
- 适合大数据处理
- m每天产生的数据量,GB,TB,甚至PB级数据,一般在TB单位
- 百万规模以上的文件数量
- 可以搭建10K+节点
- 可构建在廉价机器上
- 通过多个副本提高可靠性
- 提供了容错和恢复机制
- 高容错性
-
HDFS缺点
- 低延迟数据访问
- 比如毫秒级延迟
- 低延迟与高吞吐率
- 同一时刻文件的传输量
- 小文件读取
- 占用NameNode大量内存
- 寻找时间超过读取时间
- 比如:存储一个100兆的由1000个小文件组成的文件就不适合,因为NameNode需要管理这1000个小文件的原数据,查找并返回。如果一个100兆的文件通过名称节点去查找会耗费很大内存和时间,不合适。
- 并发写入,文件随机修改
- 一个文件只能有一个写者
- d对文件仅支持append
- 低延迟数据访问
三,MapReduce(分布式计算系统)
-
分为2个阶段:
- map阶段(可以理解是将内容进行分发计算)
- 将原始数据进行过滤操作,以键:值对的方式输出
- reduce阶段(可以理解为map阶段计算的汇总返回)
- map阶段的输出是reduce阶段的输入,reduce阶段对数据处理后输出最终的结果。
- map阶段(可以理解是将内容进行分发计算)
-
MapReduce处理的数据文件保存在HDFS上,并且最终的计算结果同样会保存到HDFS上。
-
MapReduce和HDFS相对孤立又相互联系。
四,YARN(Yet Another Resource Negotiator)
-
组成
- 由一个ResourceManager 和 多个NodeManager组成。ResourceManager运行在主服务器上,NodeManager运行在集群中的从节点上。
-
ResourceManager是什么?
- ResourceManager是集群所有可用资源的仲裁者。是一个单纯的资源控制器和调度器。主要职责是接收应用程序的资源请求并严格控制系统的可用资源。动态的分配资源。
-
NodeManager是什么的?
- NodeManager是集群中每个节点上管理进程,职责是对节点中的资源进行管理并与ReduceManager保持通信,报告节点的各种状态信息。与ReduceManager共同管理整个集群资源,资源包括内存,CPU等,会定期的作总结发给ResourceManager。
- NodeManager会收集负责服务器的CPU,内存等一些硬盘信息,汇报给ResourceManager,ResourceManager进行信息进行资源分配。
-
图片解释
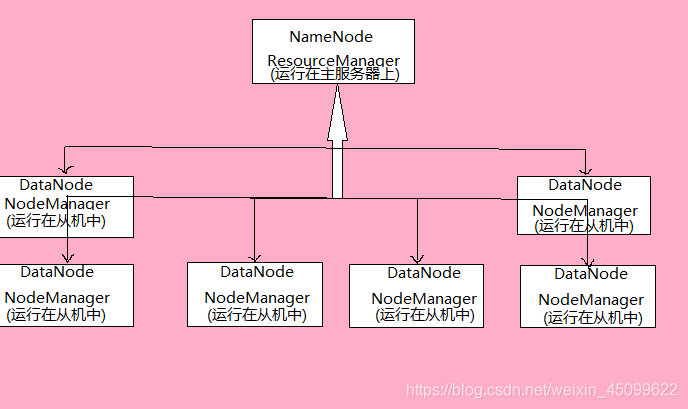
五,生态圈
- HDFS:分布式文件系统
- MAPREDUCE:分布式运算程序开发框架
- HIVE:基于HADOOP的分布式数据仓库,提供基于SQL的查询操作
- HBASE:基于HADOOP的分布式海量数据库(单张表可以有上亿行)
- ZOOLEEPER:分布式协调服务基础组件
- Mahout:基于MapReduce/spark/flink等分布式运算框架的机器学习算法库
- OOZIE:工作流调度框架
- Sqoop:数据导入导出工具(比如用于mysql和HDFS之间)
- FLUME:日志数据采集框架(用于收集用户日志)
- IMPALA:基于hive的实时sql查询分析
六,国内外应用
-
国外:
- Yahoo,Facebook,IBM等公司都大量使用Hadoop集群来支撑业务
- 比如:
- Yahoo的Hadoop应用在支持广告系统,用户行为分析,支持web 搜索等。
- Facebook主要使用Hadoop存储内部日志与多维数据,并以此作为报告,分析和机器学习的数据源。
-
国内:
- BAT互联网大厂
- 比如:
- Ali云梯(2014年国内做大的Hadoop集群),百度的日志分析平台,推荐引擎系统等。
- 金融行业:个人征信分析
- 证券行业:投资模型分析
- 交通行业:车辆,路况监控分析
- 电信行业:用户上网行为分析
国内做大的Hadoop集群),百度的日志分析平台,推荐引擎系统等。
- 金融行业:个人征信分析
- 证券行业:投资模型分析
- 交通行业:车辆,路况监控分析
- 电信行业:用户上网行为分析

















 1925
1925

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









