






libxml2库使用xpath解析带命名空间的xml文件
前言
由于项目需求需要解析一些xml文件,于是开始接触libxml2相关知识。但是在解析带命名空间的xml文件时,折腾了很久。查阅网上资料,也很少有详细说明解析方法的,因此在此处做记录,希望能帮助到有相同困境的人。
ps:环境搭建看这篇文章Linux libxml2源码编译教程
预备知识
libxml2的测试xml文件
我使用的测试xml文件如下:
<?xml version='1.0' encoding="UTF-8"?>
<bookstore xmlns="urn:newbooks-schema">
<book genre="novel" style="hardcover">
<title>The Handmaid's Tale</title>
<author>
<first-name>Margaret</first-name>
<last-name>Atwood</last-name>
</author>
<price>19.95</price>
</book>
<book genre="novel" style="other">
<title>The Poisonwood Bible</title>
<author>
<first-name>Barbara</first-name>
<last-name>Kingsolver</last-name>
</author>
<price>11.99</price>
</book>
</bookstore>
libxml2中重要的结构体
- xml节点结构体定义,构建了一个树和链表混合的数据结构,同一级别的xml节点使用链表链接,xml节点的子节点使用二叉树链接:
struct _xmlNode { void * _private : application data xmlElementType type : type number, must be second ! const xmlChar * name : the name of the node, or the entity struct _xmlNode * children : parent->childs link struct _xmlNode * last : last child link struct _xmlNode * parent : child->parent link struct _xmlNode * next : next sibling link struct _xmlNode * prev : previous sibling link struct _xmlDoc * doc : the containing document End of common part xmlNs * ns : pointer to the associated namespace xmlChar * content : the content struct _xmlAttr * properties : properties list xmlNs * nsDef : namespace definitions on this node void * psvi : for type/PSVI information unsigned short line : line number unsigned short extra : extra data for XPath/XSLT } xmlNode; - xml节点类型定义,我目前用的比较多的主要是
XML_ELEMENT_NODE和XML_TEXT_NODE,text节点的context中包含element节点的数据内容,attribute节点是干嘛的目前还不清楚。。。enum xmlElementType { XML_ELEMENT_NODE = 1 XML_ATTRIBUTE_NODE = 2 XML_TEXT_NODE = 3 XML_CDATA_SECTION_NODE = 4 XML_ENTITY_REF_NODE = 5 XML_ENTITY_NODE = 6 /* unused */ XML_PI_NODE = 7 XML_COMMENT_NODE = 8 XML_DOCUMENT_NODE = 9 XML_DOCUMENT_TYPE_NODE = 10 /* unused */ XML_DOCUMENT_FRAG_NODE = 11 XML_NOTATION_NODE = 12 /* unused */ XML_HTML_DOCUMENT_NODE = 13 XML_DTD_NODE = 14 XML_ELEMENT_DECL = 15 XML_ATTRIBUTE_DECL = 16 XML_ENTITY_DECL = 17 XML_NAMESPACE_DECL = 18 XML_XINCLUDE_START = 19 XML_XINCLUDE_END = 20 /* XML_DOCB_DOCUMENT_NODE= 21 removed */ };
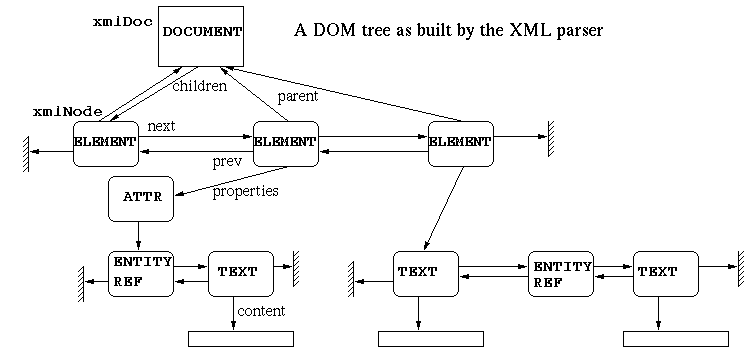
libxml2解析xml文件后的数据结构
原本打算自己画的,结果看官网的时候发现官方已经提供很详细的说明,更多信息查看官网吧,仅把结构体图搬运过来,此处是原文链接
正文
不能使用xpath定位带命名空间的xml文件原因
- 在加载xml文件时,未将注册对应的xmlns和prefix
- 在载入xml生成上下文的时候,需要给定一个命名空间,在后续使用xpath查询的时候,使用这个命名空间查询。
- 注册xmlns和prefix后,在使用xpath查询时,未指定对应的xmlns ,请参照官方例程
/libxml2-master/example/xpath1.c
此处仅截取注册xmlns函数,其关键函数是xmlXPathRegisterNs(),其余部分都是解析输入的nsList,得到对应的namespace和prefix(就是你对命名空间的简称):/** * register_namespaces: * @xpathCtx: the pointer to an XPath context. * @nsList: the list of known namespaces in * "<prefix1>=<href1> <prefix2>=href2> ..." format. * * Registers namespaces from @nsList in @xpathCtx. * * Returns 0 on success and a negative value otherwise. */ int register_namespaces(xmlXPathContextPtr xpathCtx, const xmlChar* nsList) { xmlChar* nsListDup; xmlChar* prefix; xmlChar* href; xmlChar* next; assert(xpathCtx); assert(nsList); nsListDup = xmlStrdup(nsList); if(nsListDup == NULL) { fprintf(stderr, "Error: unable to strdup namespaces list\n"); return(-1); } next = nsListDup; while(next != NULL) { /* skip spaces */ while((*next) == ' ') next++; if((*next) == '\0') break; /* find prefix */ prefix = next; next = (xmlChar*)xmlStrchr(next, '='); if(next == NULL) { fprintf(stderr,"Error: invalid namespaces list format\n"); xmlFree(nsListDup); return(-1); } *(next++) = '\0'; /* find href */ href = next; next = (xmlChar*)xmlStrchr(next, ' '); if(next != NULL) { *(next++) = '\0'; } /* do register namespace */ if(xmlXPathRegisterNs(xpathCtx, prefix, href) != 0) { fprintf(stderr,"Error: unable to register NS with prefix=\"%s\" and href=\"%s\"\n", prefix, href); xmlFree(nsListDup); return(-1); } } xmlFree(nsListDup); return(0); }
编码验证
-
编译测试代码:
gcc -Wall -g ./xpath1.c -o ./xpath1 -lxml2

-
运行测试
- 不带prefix的xpath查询:
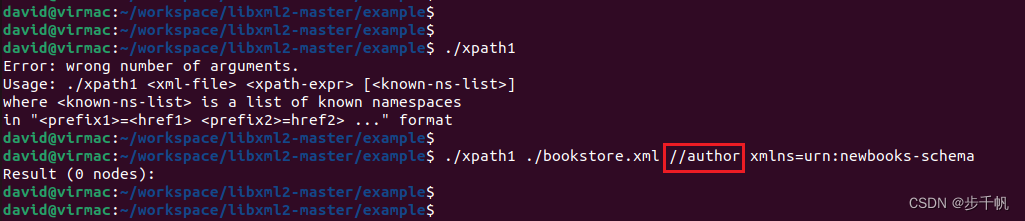
- 带prefix的xpath查询:

- 不带prefix的xpath查询:
- 示例中的xmlns是我随便起的命名空间简称
xmlns=urn:newbooks-schema是将xml文件中的urn:newbooks-schema命名空间,自定义为xmlns,这样我们后续就可以使用这个简化后的xmlns做查询了- 当你使用xpath定位带命名空间的xml文件时,xpath的每个表达式都需要指定prefix:

拓展例程
如何递归打印xmlNode信息
在官方例程中,只提示找到了xpath标定的节点,但是并未打印出具体节点的内容。因此根据解析后的xmlNode数据组织方式(树和链表的混合结构),在原有例程上进行一定修改,支持递归打印元素节点中所有元素数值,其核心函数是xmlNodeGetContent()和xmlChildElementCount():
/**
* parsing_node_data
* @notes Pass in an xmlNodePtr,
* recursively parse all its child nodes , and output the values
* contained in each element node
*/
void printf_table(int recursive_depth)
{
for(int i=0; i< recursive_depth ; i++)
{
printf("\t");
}
}
/*Tree-linking Table traversal*/
void parsing_node_data(xmlNodePtr node)
{
static int recursive_depth=1;
if(xmlChildElementCount(node) >0 )
{
printf("Tree traversal: current Node %s is element Node, have %ld subNode \n ",
node->name , xmlChildElementCount(node));
/*get cur node's children node */
xmlNodePtr child_node = node->children;
recursive_depth++;
parsing_node_data(child_node);
}
else
{
int j = 0;
while( j < xmlChildElementCount(node->parent) )
{
//printf("Get my parent elementCount %ld \n", xmlChildElementCount(node->parent));
if(xmlChildElementCount(node) > 0 )
{
printf("Link traversal: current Node %s is element Node, have %ld subNode \n",
node->name , xmlChildElementCount(node));
/*get cur node's children node */
xmlNodePtr child_node = node->children;
recursive_depth++;
parsing_node_data(child_node);
j++;
}
else
{
xmlChar * result_string=NULL;
if(node->type == XML_ELEMENT_NODE)
{
result_string = xmlNodeGetContent(node);
printf_table(recursive_depth);
printf("Node %d , name %s , value %s \n" , j , node->name
, result_string );
j++;
}
}
if(node->next == NULL)
break;
else
node = node->next;
}
recursive_depth--;
}
}
在例程print_xpath_nodes()中函数添加parsing_node_data():
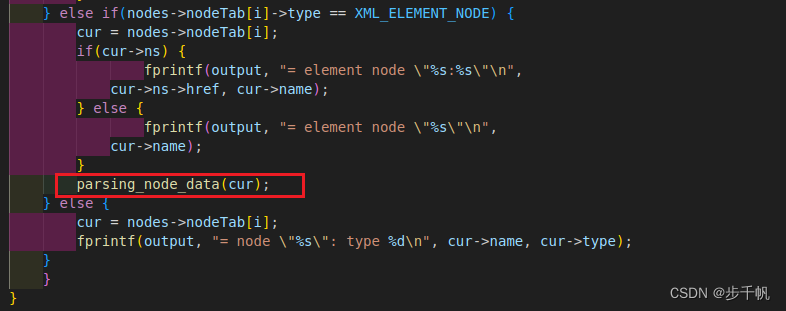
再次编译运行,结果如下,每个元素节点名称和包含的内容都被打印出来了:

如何修改xml文件中某项数据并保存
-
查找到对应xml元素节点,并设置该xml元素节点数据
if(!xmlStrcmp(node->name , BAD_CAST"first-name")) { printf("Get Target info Node Order %d \n",j); printf("Before data %s \t",result_string); xmlNodeSetContent(node , BAD_CAST"hello-word"); printf("After data %s \n",xmlNodeGetContent(node)); }此处插入代码:
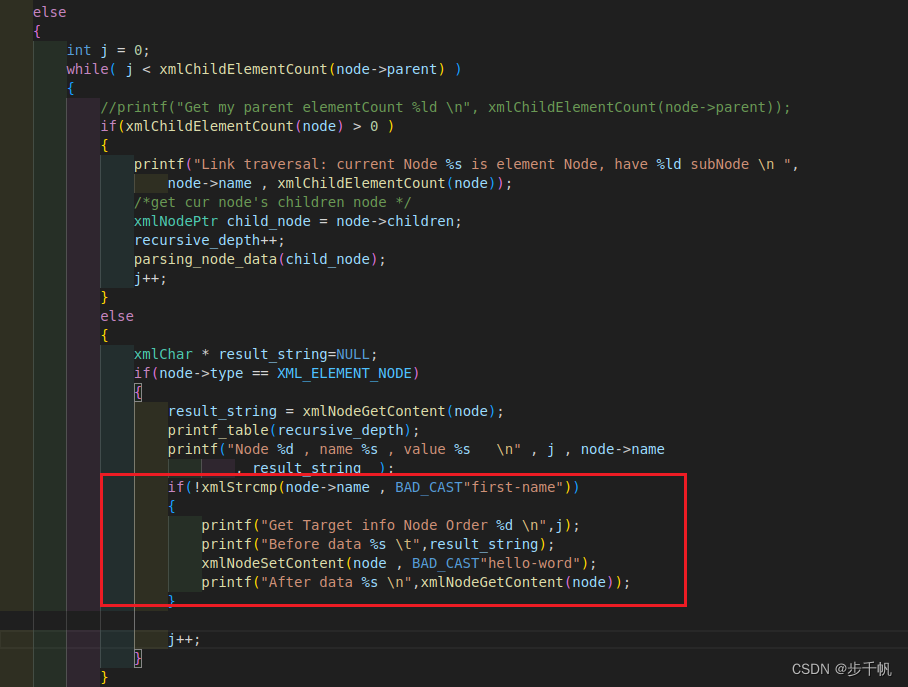
测试结果如下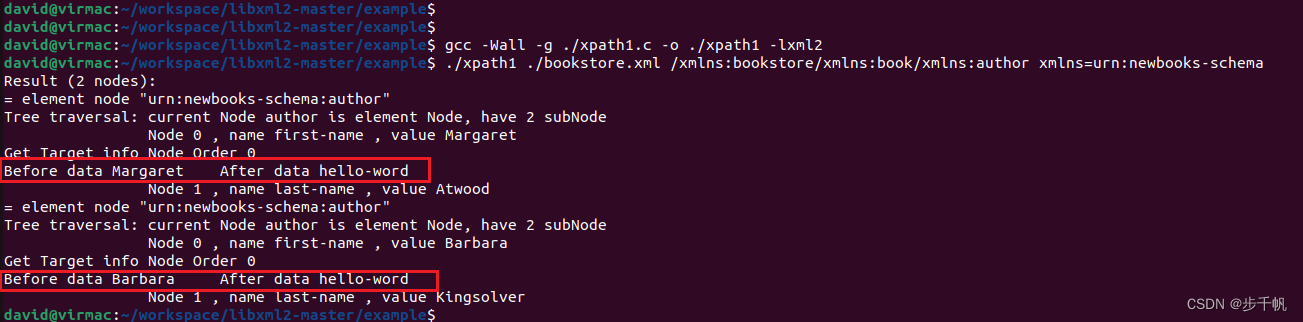
-
以覆盖文件的形式保存对该xml元素节点的修改
xmlSaveFile(filename,doc);在xpath1.c
execute_xpath_expression()函数中添加此函数
再次编译运行:
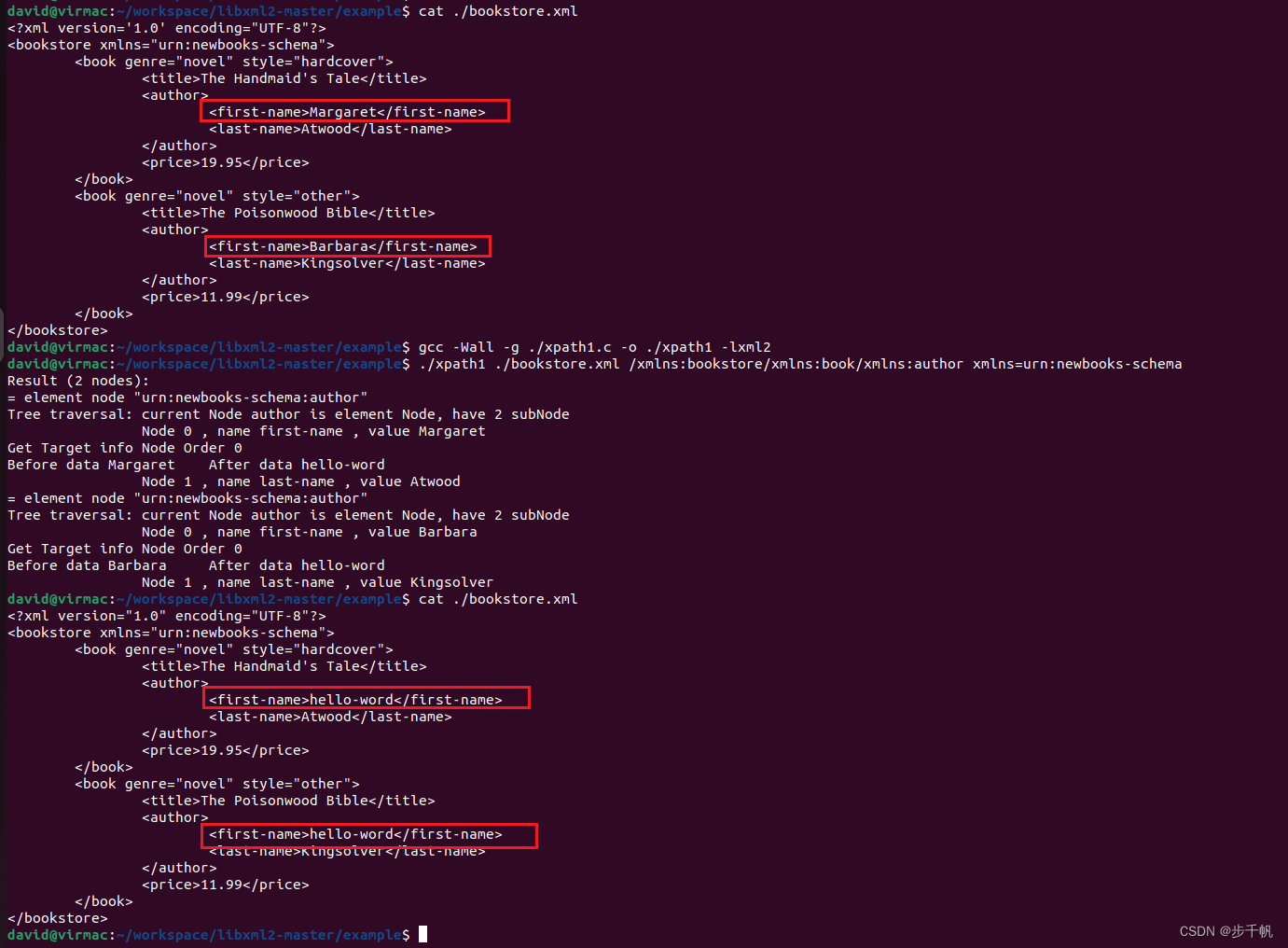
可以看到保存成功


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









