









如果service层中某个方法需要用到事务,且需要加分布式锁,则一般事务在内层,锁在外层,
避免出现已经解锁了但是事务还没提交,从而出现优惠券超领的情况
所以一般都是事务在service层中添加,但是分布式锁在controller层中添加
@ApiOperation("领取优惠券")
@GetMapping("/add/promotion/{coupon_id}")
public JsonData addPromotionCoupon(
@ApiParam(value = "优惠券id",required = true)
@PathVariable("coupon_id") long couponId){
LoginUser loginUser = LoginInterceptor.threadLocal.get();
// 通过控制key来控制锁的粒度,key里面加上userid后将锁粒度缩小到每个用户
String lockKey = "lock:coupon:"+couponId+":"+loginUser.getId();
RLock rlock = redissonClient.getLock(lockKey);
// 多个线程进入会阻塞,等待锁释放
rlock.lock();
// 调用 service中的方法含有事务,需要将事务放在锁里面
try {
JsonData jsonData = couponService.addCoupon(couponId, CouponCategoryEnum.PROMOTION);
return JsonData.buildSuccess(jsonData);
}finally {
rlock.unlock();
log.info("解锁成功");
}
}
缓存
1、springcache缓存框架
框架提供了注解的方式来实现缓存。在提供事务的回滚的同时,缓存也自动回滚。
核心是:一个是Cache接口,缓存操作的api,一个是cachemanage管理各类缓存,有多个缓存缓存框架的实现。
使用:
1、在conmoon项目里面添加依赖
<!--springcache 依赖包-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-cache</artifactId>
</dependency>
2、在主配置文件里面配置缓存类型 (spring的下一级)
cache:
type: redis
3、启动类开启缓存可用
@EnableCaching
4、定义序列化器 放在common的config里面
/**
* 缓存的序列化器
*/
@Configuration
@EnableCaching
public class CustomRedisCacheManager extends CachingConfigurerSupport {
@Bean
public RedisCacheConfiguration redisCacheConfiguration(){
Jackson2JsonRedisSerializer<Object>
jackson2JsonRedisSerializer = new
Jackson2JsonRedisSerializer<>(Object.class);
RedisCacheConfiguration configuration
=
RedisCacheConfiguration.defaultCacheConfig();
configuration = configuration.serializeValuesWith(
RedisSerializationContext.SerializationPair
// TODO Duration.ofMinutes(1)是指定缓存的过期时间
.fromSerializer(jackson2JsonRedisSerializer)).entryTtl(Duration.ofMinutes(1));
return configuration;
}
}
5、cache中常用的几个注解
@CachePut // 应用到写数据的方法上,如新增、修改方法,调用方法时会自动把响应的数据放入缓存中
@CacheEvict // 情况对应的缓存
@Cacheable // 读取的数据放到缓存里面
@Caching //组合上面的三个注解进行使用
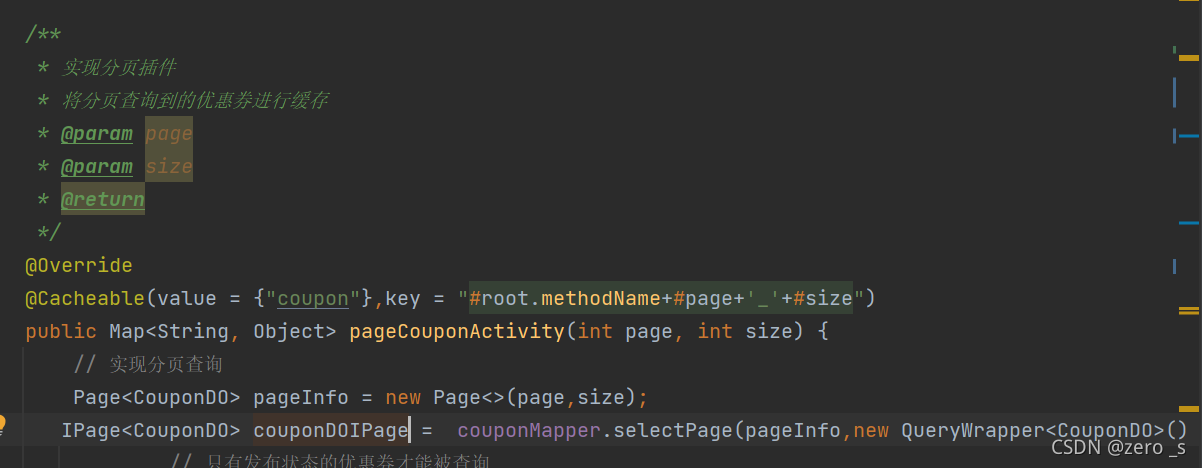
@Cacheable(value = {"coupon"},key = "#root.methodName+#page+'_'+#size")
其中key是通过获取方法中的参数来设置key,key里面拼接字符串需要用单引号
缓存的使用
缓存和数据库是一定会有不一致的,这一点无法避免。因此是不是用缓存,需要看业务是否能接受短暂的不一致出现。因此只能是基于base理论达到最终的一致性。
微服务只读接口使用了缓存:
使用缓存一般需要在内网进行压测,暂停其他高负载进程,这样可以避免带宽受限的影响。
压测结果:基于内网压测,在4核8G的设备中,(对于链路不长的接口)比如商品列表、优惠券列表、个人中心 这些只读情况下的接口,单机qps可以达到2~3万;
其他的写接口:下单接口,Tps在100~400之间;支持rancher自动化扩容,对突发流量支持扩容,恢复正常后是会缩容。不能无限扩容的原因,商品、用户、优惠券这些微服务可以水平扩容,但是数据库不能水平扩容,优化的方式是可以实现一个读写分离,一主一从的架构,来实现数据库的优化。
下单接口涉及到优惠券、商品库存、发货地、优惠券抵扣、支付、上下游依赖这些内容,可以利用线程池或者异步的操作进行优化,但是整体性能还是有限。
注册接口:一般是1000,如果对这个服务部署了集群,也可达到上万。
登录、收藏、加购物车(走redis缓存),在1万左右,这些服务都支持自动化扩容和监控的思想,实现自动化扩容是Nginx的通过监控PV、RT、UV这些指标,然后采集这部分日志,然后输送到监控平台,监控平台通过同比、环比会触发扩容或者缩容,让rancher调度扩容和缩容的服务。(文档574页)



















 950
950

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











