






 该文展示了如何使用Pytorch搭建一个4层的Resnet神经网络,输入为224x224x3的RGB图像,输出为1000类。网络包括layer0至layer4,每个layer由ResBlock组成,涉及卷积、批量归一化和激活函数。最后,网络在CIFAR10数据集上进行训练。
该文展示了如何使用Pytorch搭建一个4层的Resnet神经网络,输入为224x224x3的RGB图像,输出为1000类。网络包括layer0至layer4,每个layer由ResBlock组成,涉及卷积、批量归一化和激活函数。最后,网络在CIFAR10数据集上进行训练。
1.Pytorch搭建4层Resnet神经网络,基本参数如下:
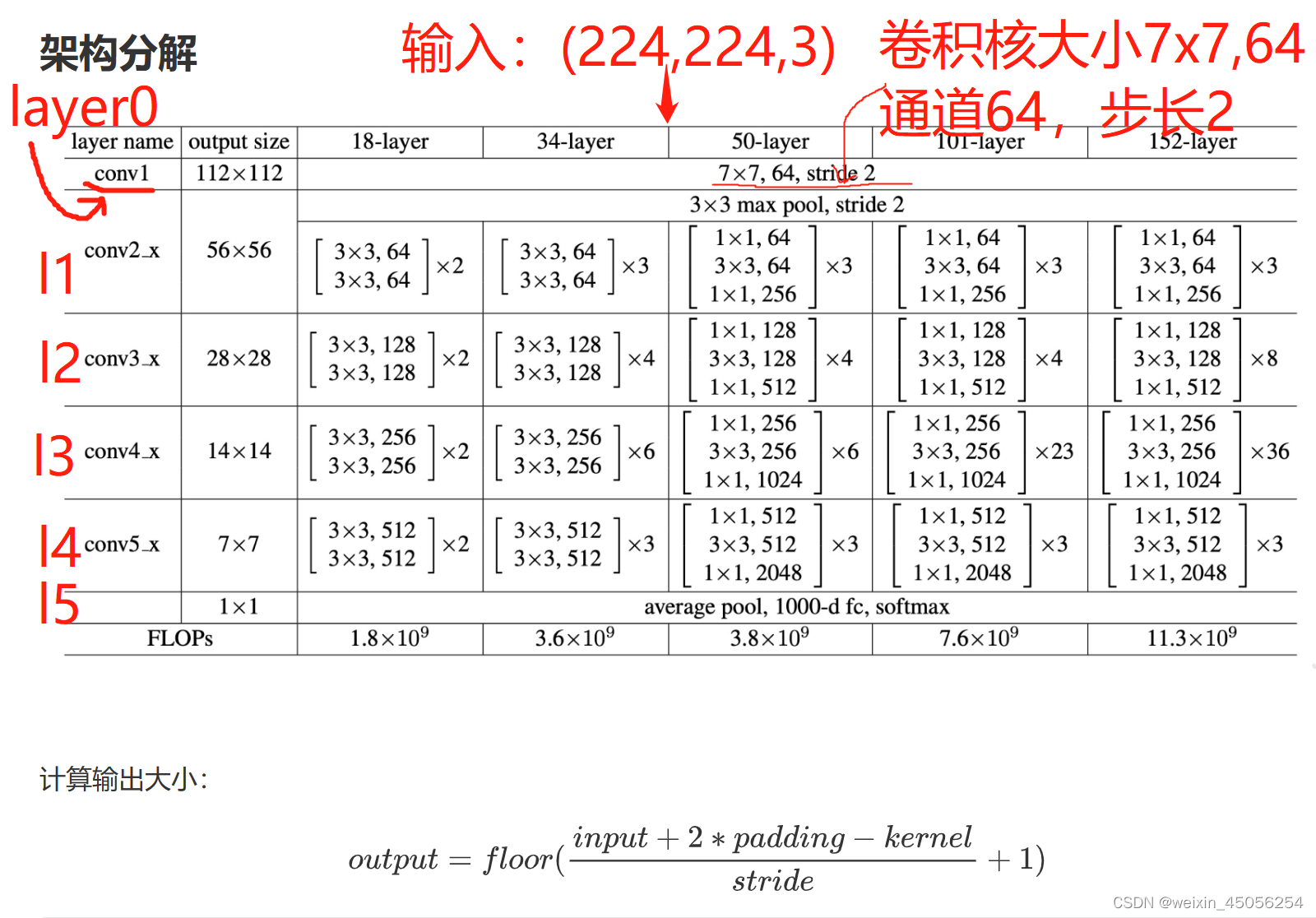
1)一开始的输入大小设置为:(224,224,3)
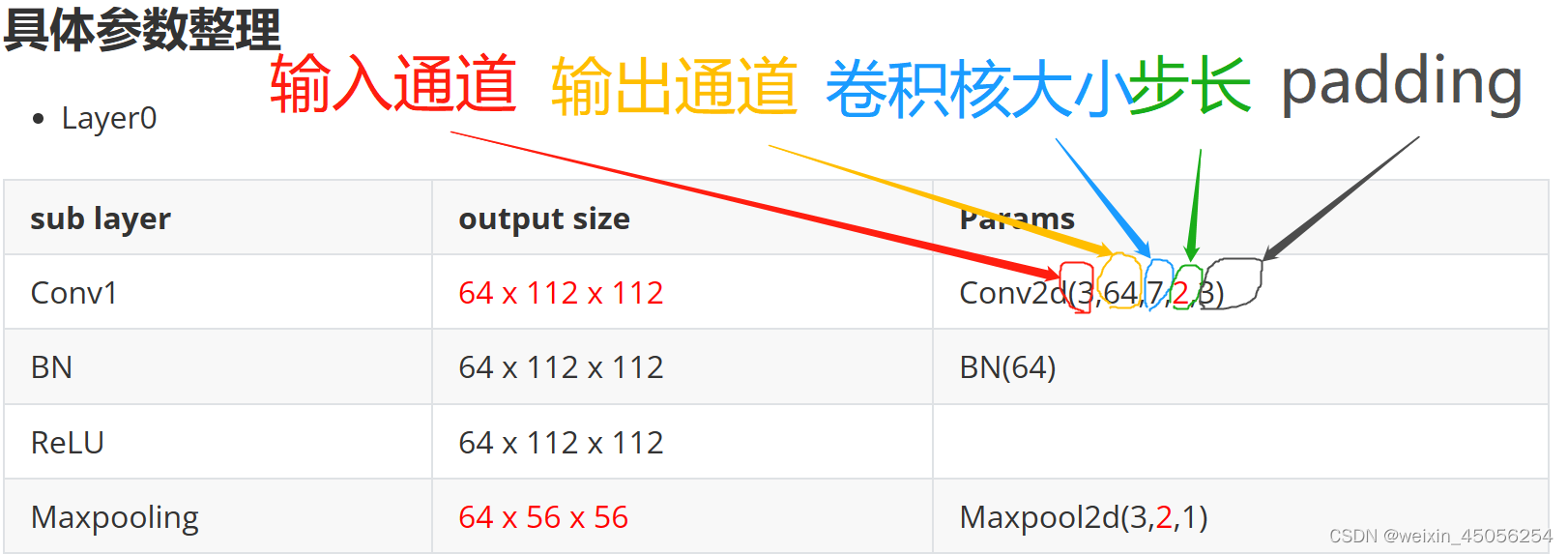
2)layer0层有1层卷积、BN、激活、池化两个部分,卷积核大小为7X7,通道为64,步长为2,池化层大小为 3x3,步长为2;
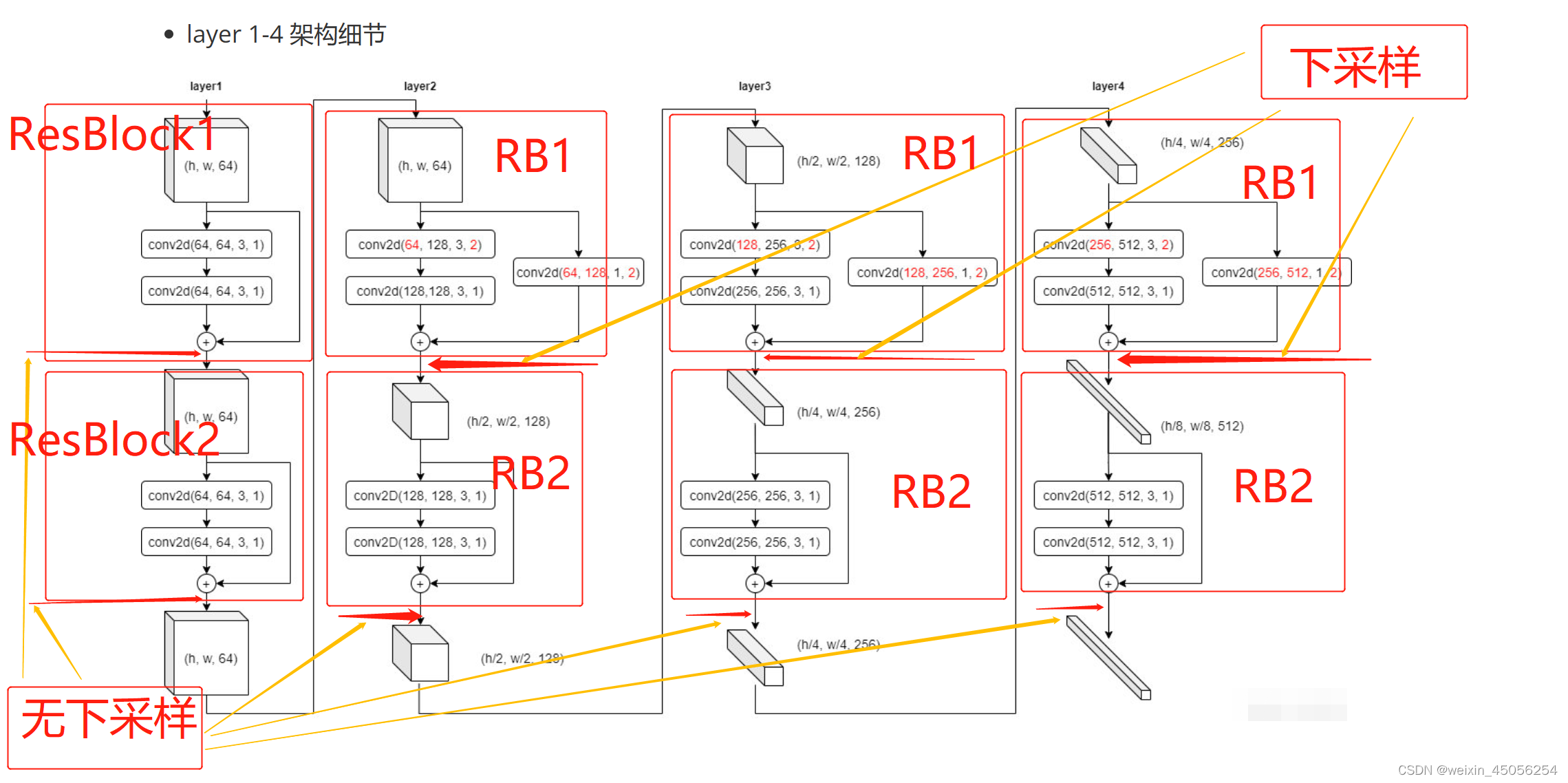
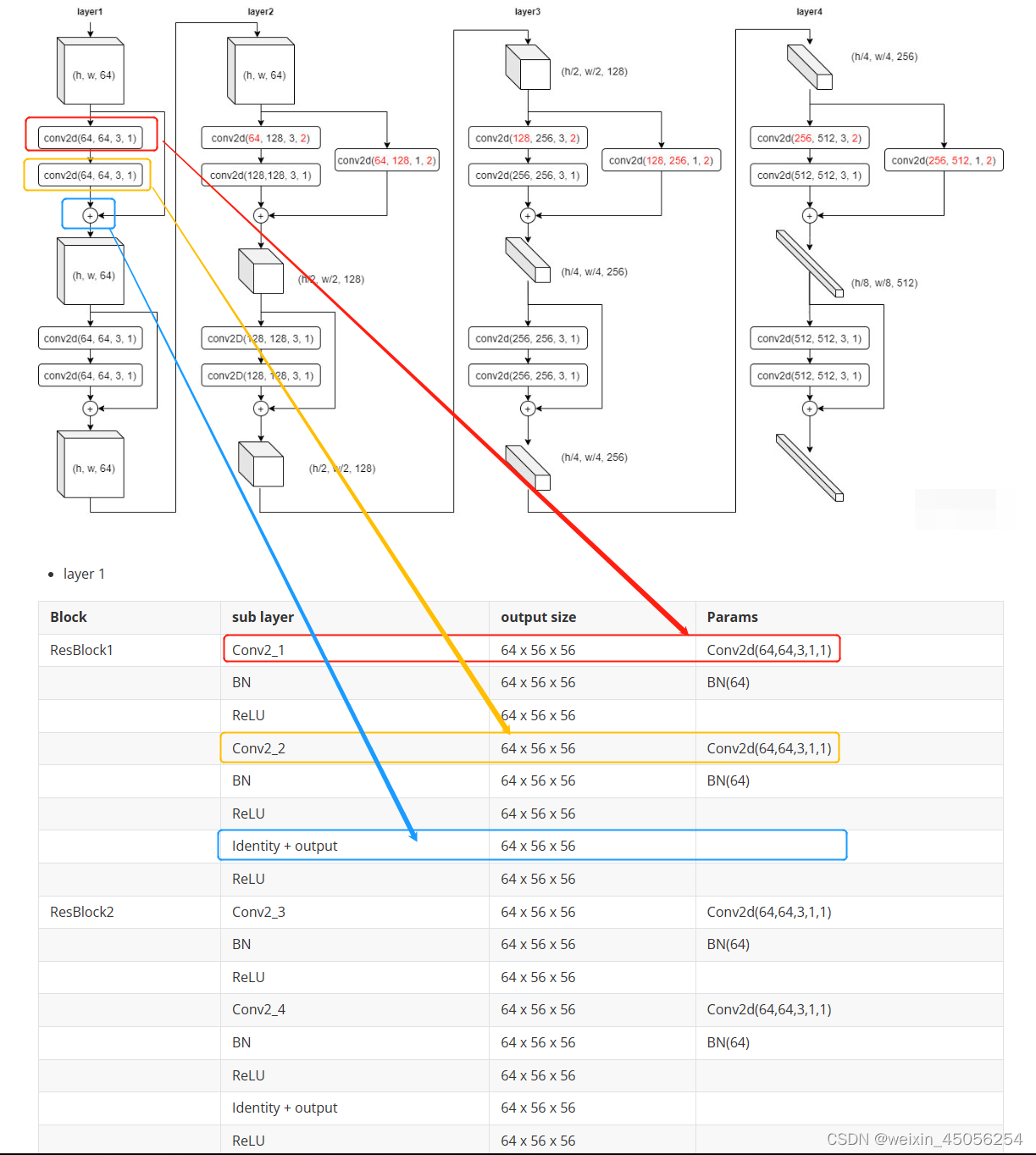
3)layer1-layer4每层都有ResBlock1、ResBlock2,每个模块都经过两次2维卷积,每个模块可能会经历下采样与尺寸通道的变化,具体见layer1-layer4架构细节图ResBlock1、ResBlock2每个模块都会经历卷积、BN算法(解决层数多了后收敛慢的问题)、激活的过程,具体见各层关系对应图
各层对应关系:
import torch
import torch.nn as nn
from torchsummary import summary
import torchvision
import torchvision.transforms as transforms
"""目的:搭建一个4层残差网络:输入:224x224x3 RGB彩图,输出:1000类"""
class Resnet18(nn.Module):
#每个神经网络的构成
def __init__(self,num_classes):
super().__init__()#继承父类的方法,即使定义了def __init__(self,num_classes):也不会覆盖父类的def __init__(self,num_classes)函数
channels_list = [64,128,256,512]#为方便预先定义每层通道数量
#layer 0
self.layer_0 = nn.Sequential(
nn.Conv2d(in_channels=3,out_channels=64,kernel_size=7,stride=2,padding=3),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.MaxPool2d(kernel_size=3,stride=2,padding=1),
)
# layer 1
self.layer_1 = nn.Sequential(
ResBlock(False,channels_list[0],channels_list[0]),#不做下采样
ResBlock(False,channels_list[0],channels_list[0]),#不做下采样
)
# layer 2
self.layer_2 = nn.Sequential(
ResBlock(True,channels_list[0],channels_list[1]),#做下采样
ResBlock(False,channels_list[1],channels_list[1]),#不做下采样
)
# layer 3
self.layer_3 = nn.Sequential(
ResBlock(True,channels_list[1],channels_list[2]),#做下采样
ResBlock(False,channels_list[2],channels_list[2]), #不做下采样
)
# layer 4
self.layer_4 = nn.Sequential(
ResBlock(True,channels_list[2],channels_list[3]),#做下采样
ResBlock(False,channels_list[3],channels_list[3]),#不做下采样
)
#layer 5
self.aap = nn.AdaptiveAvgPool2d((1, 1))# 平均池化
self.flatten = nn.Flatten(start_dim=1)# 拉直
self.fc = nn.Linear(channels_list[3],num_classes)# 全连接层
#每层神经网络之间的链接
def forward(self,x):
x = self.layer_0(x)
x = self.layer_1(x)
x = self.layer_2(x)
x = self.layer_3(x)
x = self.layer_4(x)
x = self.aap(x)
x = self.flatten(x)
x = self.fc(x)
return x
class ResBlock(nn.Module):
def __init__(self,down_sample,in_channels,out_channels):
super().__init__()
if down_sample:
self.conv1 = nn.Conv2d(in_channels,out_channels,3,2,1)
self.bn1 = nn.BatchNorm2d(out_channels)
self.relu1 = nn.ReLU()
self.conv2 = nn.Conv2d(out_channels,out_channels,3,1,1)
self.bn2 = nn.BatchNorm2d(out_channels)
self.relu2 = nn.ReLU()
self.shortcut = nn.Sequential(
nn.Conv2d(in_channels,out_channels,1,2,0),
nn.BatchNorm2d(out_channels))#Sequential不是一个空壳,加了nn.Conv2d、nn.BatchNorm2d规则,所以shortcut接收任何数都是先卷积再BN算法
self.relu3 = nn.ReLU()#一个模块的最终结果也是需要被激活一下的
else:
self.conv1 = nn.Conv2d(in_channels,out_channels,3,1,1)
self.bn1 = nn.BatchNorm2d(out_channels)
self.relu1 = nn.ReLU()
self.conv2 = nn.Conv2d(out_channels,out_channels,3,1,1)
self.bn2 = nn.BatchNorm2d(out_channels)
self.relu2 = nn.ReLU()
self.shortcut = nn.Sequential()#Sequential是一个空壳,没有规则,所以shortcut接收任何数都是没有规则的出去
self.relu3 = nn.ReLU()#一个模块的最终结果也是需要被激活一下的
def forward(self,x):
shortcut = self.shortcut(x)#注意这里做下采样和不做下采样的self.shortcut对x的处理结果是不一样的
#ResBlock的两次卷积
x= self.conv1(x)
x = self.bn1(x)
x = self.relu1(x)
x= self.conv2(x)
x = self.bn2(x)
x = self.relu2(x)
#残差连接
x = x + shortcut
x = self.relu3(x)
return x
resnet18 =Resnet18(10)
#resnet18 =Resnet18(10).to('cuda:0')
"""加载模型"""
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
batch_size = 4
trainset = torchvision.datasets.CIFAR10(root='./1', train=True,
download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=batch_size,
shuffle=True, num_workers=2)
testset = torchvision.datasets.CIFAR10(root='./1', train=False,
download=True, transform=transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=batch_size,
shuffle=False, num_workers=2)
optimizer = torch.optim.SGD(resnet18.parameters(),lr=0.01)# 加载res18模型及res18模型的优化器
criterion = nn.CrossEntropyLoss()#加载res18模型LOSS函数
for epoch in range(2): # loop over the dataset multiple times
running_loss = 0.0
for i, data in enumerate(trainloader, 0):
# get the inputs; data is a list of [inputs, labels]
inputs, labels = data
#inputs.to('cuda:0')
# zero the parameter gradients
optimizer.zero_grad()
# forward + backward + optimize
outputs = resnet18(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
# print statistics
running_loss += loss.item()
print(loss.item())
if i % 2000 == 1999: # print every 2000 mini-batches
print(f'[{epoch + 1}, {i + 1:5d}] loss: {running_loss / 2000:.3f}')
running_loss = 0.0
print('Finished Training')Gitee链接:✉

















 2164
2164

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









