






 文章提出了一种新的IA-YOLO框架,针对恶劣天气条件下的目标检测。该框架使用可微图像处理模块DIP和CNN-PP预测器,以自适应地增强图像,提高YOLOv3的检测性能。DIP模块包括像素滤波器、锐化滤波器和去雾滤波器,旨在恢复图像细节和去除天气影响。通过端到端训练,CNN-PP学习适应性增强策略,以辅助目标检测。
文章提出了一种新的IA-YOLO框架,针对恶劣天气条件下的目标检测。该框架使用可微图像处理模块DIP和CNN-PP预测器,以自适应地增强图像,提高YOLOv3的检测性能。DIP模块包括像素滤波器、锐化滤波器和去雾滤波器,旨在恢复图像细节和去除天气影响。通过端到端训练,CNN-PP学习适应性增强策略,以辅助目标检测。
目录
Image-Adaptive YOLO for Object Detection in Adverse Weather Conditions
Image-Adaptive YOLO for Object Detection in Adverse Weather Conditions
Abstract
面临问题:
基于深度学习的目标检测方法在传统的数据集上取得了很好的效果,但在恶劣天气条件下从低质量的图像中定位目标仍然具有挑战性。现有的方法要么难以平衡图像增强和目标检测的任务,要么往往忽略了对检测有利的潜在信息。
提出方法:
提出一种新的图像自适应YOLO(IA-YOLO)框架 ,其中每个图像都可以自适应地增强以获得更好的检测性能,具体来说,针对YOLO探测器的不利天气条件,提出了一种可微图像处理(DIP)模块,该模块的参数由小卷积神经网络(CNN-PP)预测。
我们以端到端的方式联合学习CNN-PP和YOLOV3,这保证了CNN-PP可以学习适当的倾角来增强图像以弱监督的方式进行检测。
提出的我们提出的IA-YOLO方法可以自适应地处理正常和不利天气条件下的图像。
Introduce
如今方法所面临的问题:
由于输入图像中的域移位,在不利的天气下,由高质量图像训练的一般检测模型往往不能取得满意的结果;如果能根据天气情况对图像进行适当的增强,就可以恢复更多关于原始模糊物体和误判物体的潜在信息;
目前提出了两种方案:
1.使用两个子网络来联合学习可见性增强和目标检测,其中通过共享特征提取层来降低图像退化的影响;
问题:在训练过程中,很难调整参数来平衡检测和恢复之间的权重;
2.利用图像去雾等现有方法对图像进行预处理,淡化天气特定信息的影响;
问题:这些方法中包含了复杂的图像恢复网络,需要在像素级监督下单独训练。 这需要手动标记图像以便恢复。 这个问题也可以看作是一个无监督的领域自适应任务
Proposed Method
提出了一个图像自适应检测框架,通过去除特定天气信息和揭示更多潜在信息。
具体:
提出了一个完全可微的图像处理模块(DIP),其超参数通过一个小型的基于CNN的参数预测期(CNNPP)自适应学习;
CNN-PP根据输入图像的亮度、颜色、色调和天气信息自适应地预测倾角的超参数。
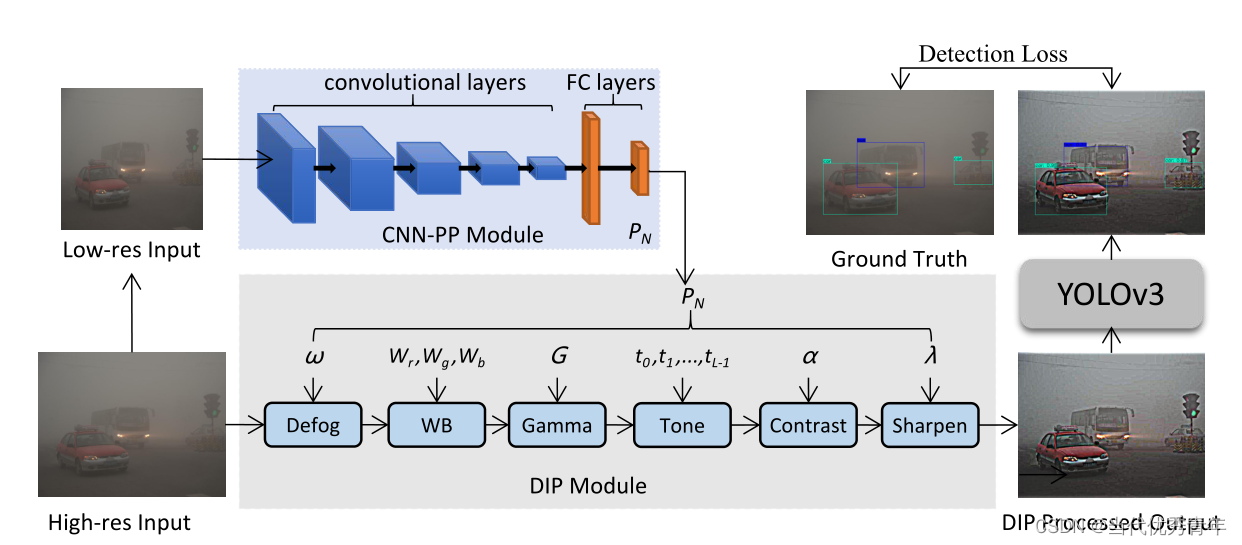
结构:
1.整个管道由基于cnn的参数预测器(CNNPP)
2.可微图像处理模块(DIP)
3.检测网络
-
- 首先将输入图像的大小调整为256 × 256;
- 并将其输入CNN-PP进行DIP参数预测;
- 将DIP模块滤波后的图像作为YOLOv3探测器的输入
Summary:提出了一种带有检测损失的端到端(end-to-end)混合数据训练方案,使CNN-PP能够以弱监督的方式学习适当的DIP来增强图像以进行目标检测;
DIP module
1.图像滤波器的设计应符合可微分性和分辨率独立原则;
2.对于基于梯度的CNN-PP优化,滤波器应该是可微的,以允许反向传播训练网络;
3.由于CNN在处理高分辨率图像时会消耗大量的计算资源(例如4000×3000),因此在本文中,我们从尺寸为256 × 256的下采样低分辨率图像中学习滤波器参数;
4.对原始的图像应用相同的filter;
本文从256×256的低分辨率下采样图像中学习滤波器参数,然后将相同的滤波器应用到原始分辨率的图像中。 因此,这些滤波器需要独立于图像分辨率。
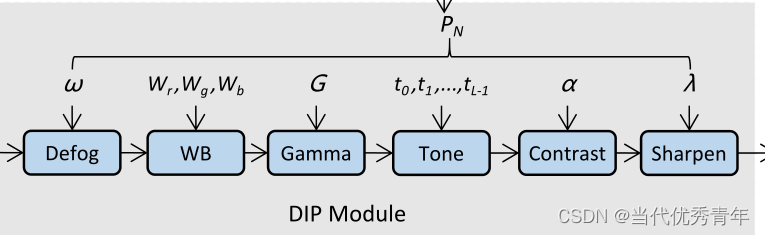
DIP由六个可微filters和可调超参数组成,包括除雾、白平衡(WB)、伽马、对比度、色调和锐化;
WB、Gamma、对比度和色调,可以表示为像素级滤波器;
因此,设计的filters可以分为去雾、像素滤光片和锐化filters。
Pixel-wise Filters
像素滤波器将输入像素值PI=(ri,gi,bi)映射为输出像素值PO=(ro,go,bo),其中(r,g,b)分别表示红、绿、蓝三个颜色通道的值。

WB和Gamma是简单的乘法和幂变换
可微对比度滤波器通过输入参数设置原始图像和万全增强图像之间的线性插值
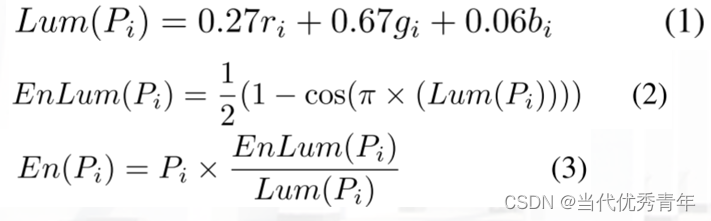
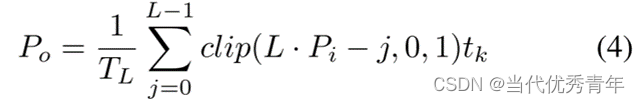
色调filter设计为单调和线性分段函数
Sharpen Filters
图像锐化可以突出图像细节。锐化过程可以描述如下:
这个锐化操作对于x和λ都是可微的。可以通过优化λ来调整锐化程度以获得更好的对象检测性能。
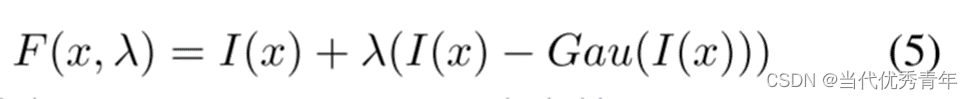
Defog Filter
我们设计了一个具有可学习参数的去雾滤波器。基于大气散射模型,模糊图像生成公式如下
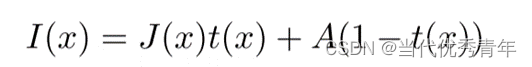
其中I(x)代表模糊图像,J(x)表示场景亮度,A为全球大气光,β表示大气的散射系数,并且d(x)是场景深度, t(x)是介质传输映射(透射率)可表示为:
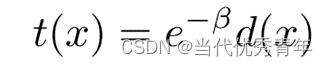
为了恢复清晰图像J(x),关键是要获得大气光A和透射图t(x),为此,我们首先计算雾霾图像I(x)的暗通道图,并选择前1000个最亮的像素。 然后,通过平均雾霾图像I(x)的对应位置的这1000个像素来估计A。
通过上述等式,我们进一步引入一个参数ω来控制除雾程度,可以优化ω。如下所示:

图像自适应处理模块根据每幅输入图像的亮度、颜色、色调和天气信息输出相应的滤波参数,以获得更好的检测性能。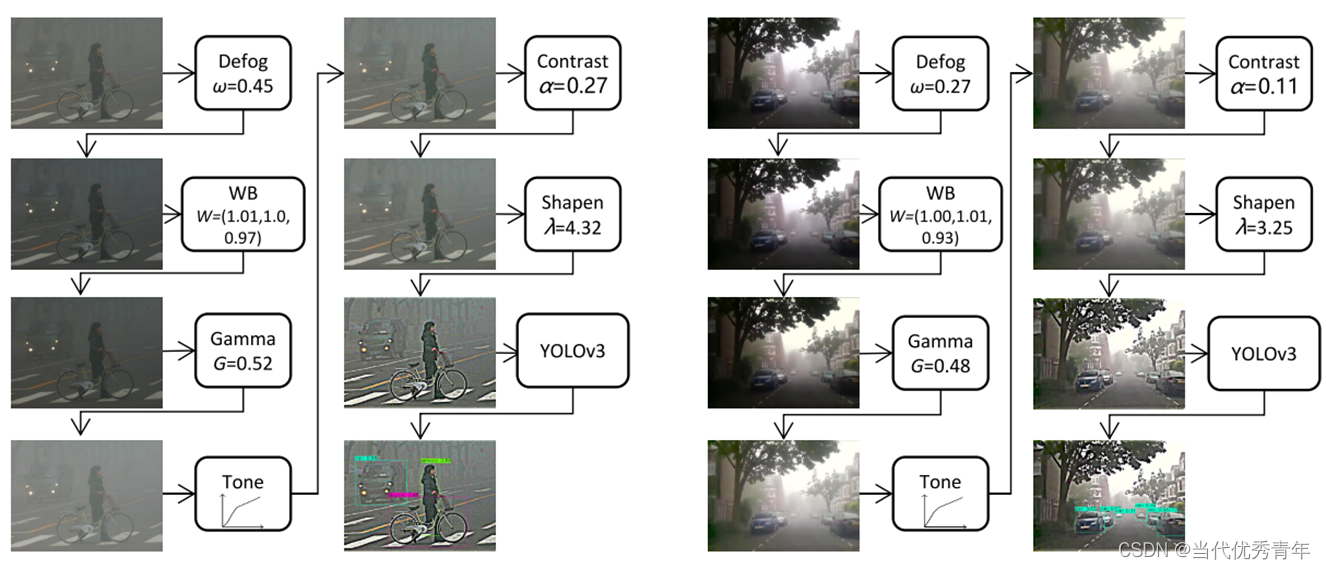
CNN-PP Model
在图像信号处理(ISP)流程中,通常使用一些可调滤波器来进行图像增强,其超参数由人工调节。
- 本文提出用一个小的CNN作为参数预测器来估计超参数;
- 首先输入图像,我们简单地使用双线性插值将其下采样到256×256分辨率。
- CNN-PP网络由五个卷积块和两个全连接层组成,得到一个特征向量;
- 每个卷积块包括步幅为2的3×3卷积层和一个Leaky Relu。
- 全连接层输出DIP模块的超参数。 这五个卷积层的输出通道分别为16、32、32、32和32。
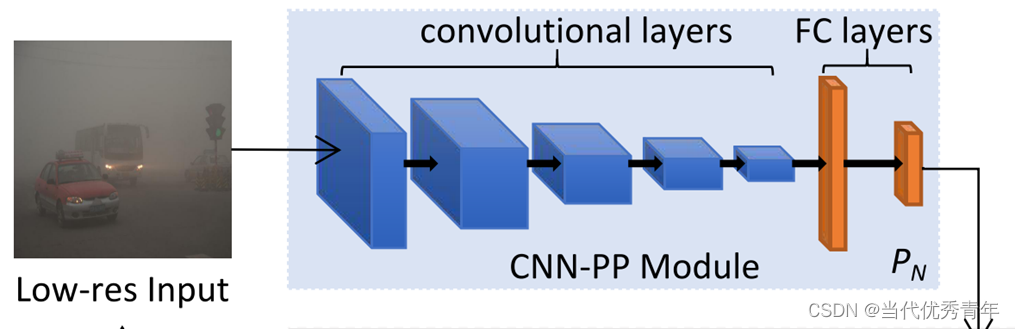

Detection Network Module
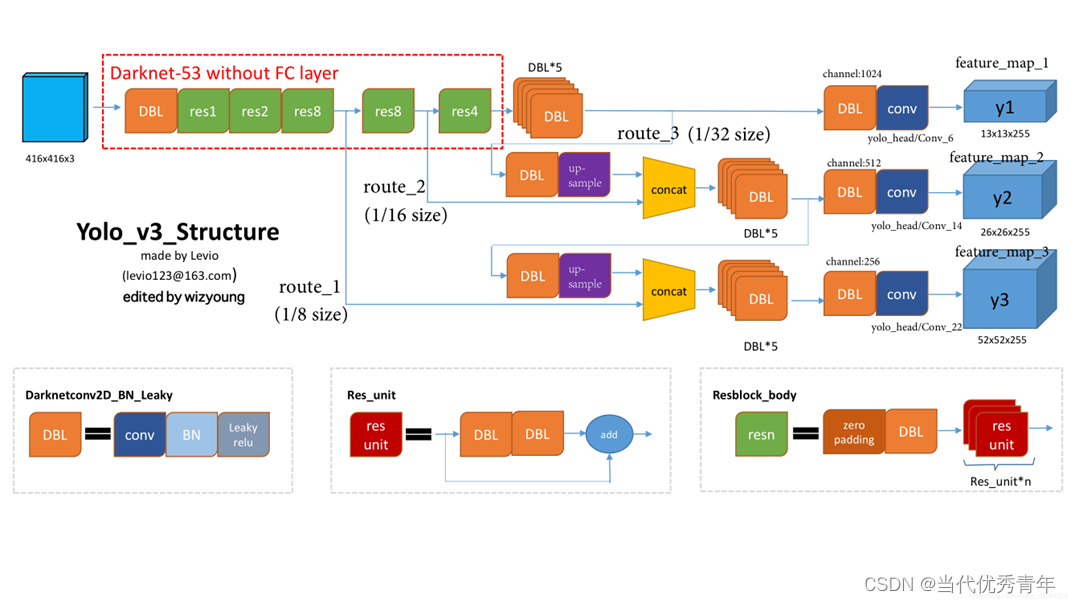
YOLOv3
YOLOv3整个网络结构分为三部分:分别为Darknet-53结构、特征层融合结构、分类检测结构。
特征提取过程:
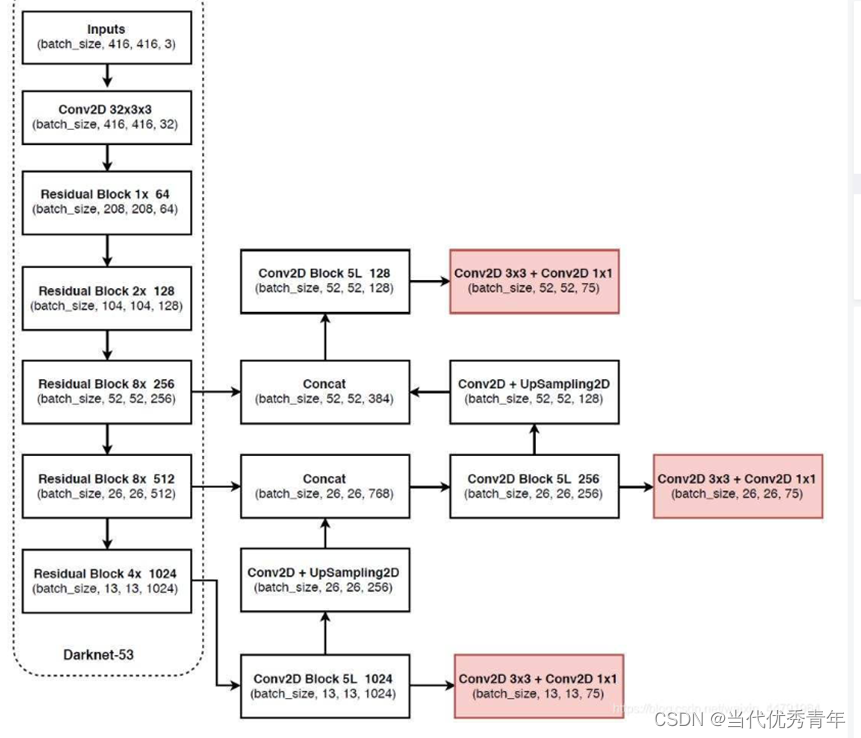
输入原始图像(416x416x3),经过Darknet-53网络后,经过一系列的卷积和残差网络原图像1/8(大小:52×52)、1/16(大小:16×26)、1/32的特征图(即feature map)
特征融合:
有了三个不同尺度的特征图,但是由于这些特征不能充分显示原图中的目标信息,所以进行特征融合以获得更好的效果。由于尺寸不同,需要进行上采样使特征图大小一样后,进行堆叠和融合。
最后得到三个特征图
Darknet-53
具有以下一些特点:
ResNet残差网络
Darknet-53中引入残差网络,目的是便于优化以及缓解梯度消失的问题。
Residual Block(残差模块)包括:两个卷积层、一个shortcut connection (跳跃链接),该层直接跳过卷积层直接将输入添加到输出中,从而使模型可以跳过某些层,从而加速网络的训练和优化。
ResNet是由多个Rseidual Block组成,每个阶段都会有多个Residual Block,阶段之间进行下采样以减小特征图大小。具体操作是将特征图的大小减半,通道数增加,最终输出经过全局平均池化得到向量,用来分类和检测任务;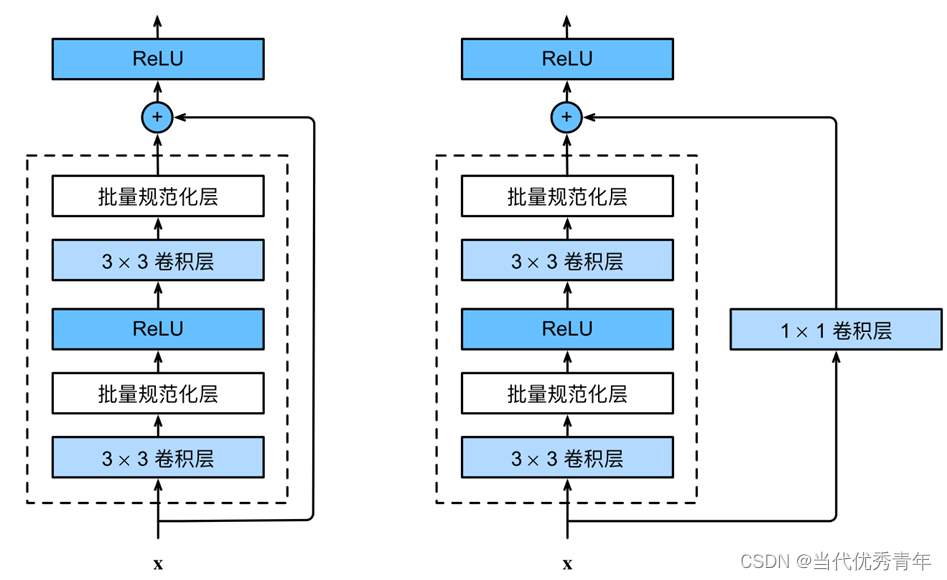
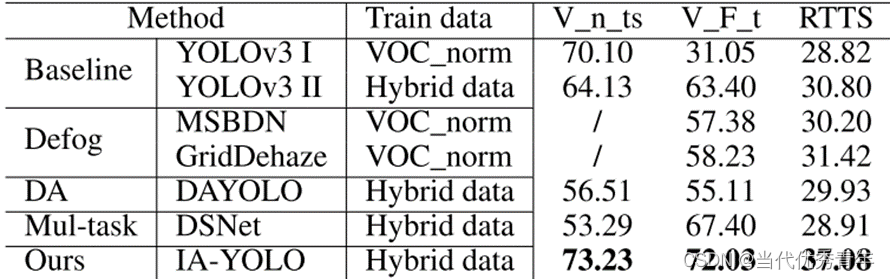
Experiment

















 7896
7896

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









