







实验目的
- 设计、编制、调试一个词法分析子程序-识别单词,加深对词法分析原理的理解。
- 了解,学习词法分析器自动生成器Flex。
实验原理
-
词法分析程序的基本任务是从字符串表示的源程序中识别出具有独立意义的单词符号,其基本思想是根据扫描到单词符号的第一个字符的种类,拼出相应的单词符号。
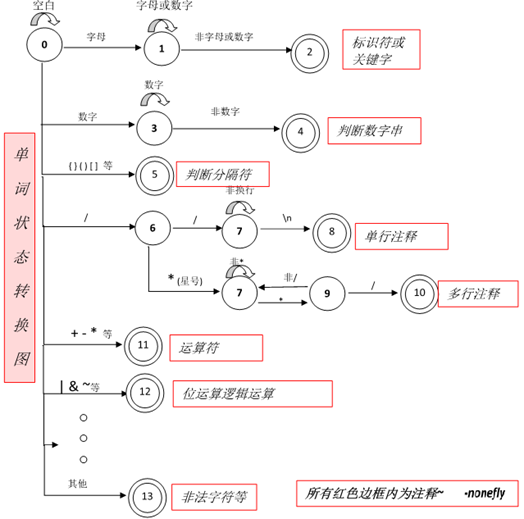
-
单词的描述称为模式(Lexical Pattern),模式一般用正规表达式进行精确描述。Flex通过读取一个有规定格式的文本文件,输出一个如下所示的C语言源程序。

-
Flex源文件结构:
%{ /*包含模式宏定义和C语言的说明信息*/
Declarations (optional)
%}
%% /*转换识别*/
Rules
%% /*规则动作部分所需的辅助过程的C代码*/
User functions (optional)
- 常用的正则表达式:
[0-9] 字符集:0|1|2|3|4|5|6|7|8|9
^ 字符集的补集,需要是字符集中第一个字符
. 匹配“换行符”之外的任何字符
x? x可重复0次或1次
x+ x需重复至少1次
x{n,m} x需重复最少n次,最多m次
^x 表示每行的最开始,即匹配x,且x为该行第一个字符
x$ 表示每行的最末尾,即匹配x,且x为该行最后一个字符
"x" 表示x本身,即使x为特殊符号
{name} 用前面已经定义的正则表达式替换
- Flex全局变量:
yytext, char*,指向所识别的字符串
yyleng, int,所识别字符串的长度
yylval, YYSTYPE,缺省类型是int,用来保存词法符号的属性
ECHO 显示所识别的串
实验内容
- 以sample.txt作为输入文件,用C语言编写程序,需要完成:
(1)识别程序中所有的整数、浮点数及字符串常量;
(2)识别程序中所有的符号、标识符及关键字;
(3)将所编写程序命名为【man_lex.c】。 - 学习所提供资料中的简单Flex源程序,试着修改其中的规则及代码,再运行。
- 用Flex完成任务1,并将所编写Flex源文件命名为【auto_lex.l】。
- 所有文件都以utf-8进行统一编码保存。
实验器材
visual studio 2017
Notepad++,flex 2.5.4.1
实验步骤
一、C语言编写词法分析器
-
待分析的语言词法:
(1)关键字:50个关键字。
(2)运算符和界符:* / + - = 等; ( ) : > >= < <= 等。
(3)其他单词是标识符和常数。
(4)空格由空白字符(\n \t \0)组成,词法分析阶段通常被忽略。 -
单词符号的编码:
| 单词符号 | 单词类别 | 单词属性 |
|---|---|---|
| 关键字、运算符和界符 | 直接表示 | |
| 标识符 | $SYMBOL | 字符串 |
| 字符串常量 | $STRING | 字符串 |
| 整数常量 | $INT | 整数 |
| 浮点数常量 | $FLOAT | 浮点数 |
| 非法字符 | $ILLEGAL | -1 |
- 程序源代码:
#include <stdio.h>
#include <stdbool.h>
#include <string.h>
#include <stdlib.h>
/*
* 输入文件:sample.txt
* 输出结果:(单词类别,单词属性)
* 要求:①识别标识符或关键字 ②识别符号 ③识别字符串常量 ④识别整数常量或浮点数常量
* 思路:从文件中逐个读取字符,根据状态转换图输出多分支结果。
*/
//将会用到的变量
char token[20]; //用来存放已读入的字符序列
char ch; //用来存放最新读入的字符
//将会用到的函数
bool letter();
bool digit();
void concat();
bool keyword();
//核心函数
void LexAnalyze(FILE* fp);
int main()
{
//读取文件内容,并返回文件指针fp,fp指向文件的第一个字符
FILE* fp;
if ((fp = fopen("sample.txt", "r")) == NULL) {
printf("The file can not open!");
return 0;
}
printf("词法分析结果如下:\n");
char ch;
do {
ch = fgetc(fp); //获取字符,指针fp自动指向下一个字符
if (ch == ' ' || ch == '\t' || ch == '\n') { } //忽略空格,空白,换行的情况
else {
fseek(fp, -1, 1); //回退一个字节开始识别单词流
LexAnalyze(fp); //词法分析
}
} while (!feof(fp)); //文件结尾结束
//关闭文件
fclose(fp);
return 0;
}
//词法分析
void LexAnalyze(FILE* fp)
{
memset(token, '\0', sizeof(token)); //置token为空串
ch = fgetc(fp);
/*
* 完成要求①
* 识别标识符或关键字
*/
if (letter(ch)) {
do {
concat();
ch = fgetc(fp);
} while (letter() || digit()); //当前字符为字母或数字
fseek(fp, -1, 1); //回退
if (keyword())
printf(" %s\n", token); //关键字
else
printf(" $SYMBOL %s\n", token); //标识符
return 0;
}
/*
* 完成要求④
* 识别整数常量或浮点数常量
*/
else if (digit(ch)) {
do {
concat();
ch = fgetc(fp);
} while (digit()); //当前字符为数字
if (ch == '.') {
do {
concat();
ch = fgetc(fp);
} while (digit()); //当前字符为数字
printf(" $FLOAT %s\n", token); //浮点数
}
else {
fseek(fp, -1, 1); //回退
printf(" $INT %s\n", token); //整数
}
}
/*
* 完成要求③
* 识别字符串常量
*/
else if (ch == '"') {
do {
ch = fgetc(fp);
concat();
} while (ch != '"');
printf(" $STRING %s\n", token); //字符串
}
/*
* 完成要求②
* 识别符号
*/
switch (ch) {
case '+':
ch = fgetc(fp);
switch (ch) {
case '+':
printf(" ++\n"); break; //++
case '=':
printf(" +=\n"); break; //+=
default:
printf(" +\n"); //+
fseek(fp, -1, 1); break;
}
break;
case '-':
ch = fgetc(fp);
switch (ch) {
case '-':
printf(" --\n"); break; //--
case '=':
printf(" -=\n"); break; //-=
default:
printf(" -\n"); //-
fseek(fp, -1, 1); break;
}
break;
case '*':
printf(" *\n"); break; //*
case '/':
ch = fgetc(fp);
switch (ch) {
case '/':
while (ch != '\n')
ch = fgetc(fp); //注释
break;
default:
printf(" /\n"); ///
fseek(fp, -1, 1); break;
}
break;
case '<':
ch = fgetc(fp);
if (ch == '=')
printf(" <=\n"); //<=
else {
printf(" <\n"); //<
fseek(fp, -1, 1);
}
break;
case '>':
ch = fgetc(fp);
if (ch == '=')
printf(" >=\n"); //>=
else {
printf(" >\n"); //>
fseek(fp, -1, 1);
}
break;
case '=':
ch = fgetc(fp);
if (ch == '=')
printf(" ==\n"); //==
else {
printf(" =\n"); //=
fseek(fp, -1, 1);
}
break;
case '!':
ch = fgetc(fp);
if (ch == '=')
printf(" !=\n"); //!=
else {
printf(" !\n"); //!
fseek(fp, -1, 1);
}
break;
case '&':
ch = fgetc(fp);
if (ch == '&')
printf(" &&\n"); //&&
else {
printf("wrong: '&' is illeagal.");
exit(-1);
}
break;
case '|':
ch = fgetc(fp);
if (ch == '|')
printf(" ||\n"); //||
else {
printf("wrong: '|' is illeagal.");
exit(-1);
}
break;
case '.':
printf(" .\n"); break; //.
case ',':
printf(" ,\n"); break; //,
case ';':
printf(" ;\n"); break; //;
case ':':
printf(" :\n"); break; //:
case '[':
printf(" [\n"); break; //[
case ']':
printf(" ]\n"); break; //]
case '{':
printf(" {\n"); break; //{
case '}':
printf(" }\n"); break; //}
case '(':
printf(" (\n"); break; //(
case ')':
printf(" )\n"); break; //)
}
}
//如果ch是字母,返回true,否则返回false
bool letter()
{
if (ch >= 'a' && ch <= 'z' || ch >= 'A' && ch <= 'Z')
return true;
else
return false;
}
//如果ch是数字,返回true,否则返回false
bool digit()
{
if (ch >= '0' && ch <= '9')
return true;
else
return false;
}
//连接字符串,把ch中的字符连接到token数组的末尾
void concat()
{
char c[] = { ch,'\0' };
strcat(token, c);
}
//如果token是关键字,返回true,否则返回false
bool keyword()
{
//定义关键字
char *key[50] = {
"abstract", "assert", "boolean", "break", "byte", "case", "catch", "char",
"class", "const", "continue", "default", "do", "double", "else", "enum", "extends", "final", "fianlly",
"float", "for", "goto", "if", "implements", "import", "instanceof", "int", "interface", "long", "native",
"new", "package", "private", "protected", "public", "return", "short", "static", "strictfp", "super",
"switch", "synchronized", "this", "throw", "throws", "transient", "try", "void", "volatile", "while" };
int i;
for (i = 0; i < 50; i++)
{
if ((strcmp(token, key[i])) == 0)
return true;
}
return false;
}
二、学习词法分析器Flex,并编写Flex源程序
- 程序源代码:
%{
#include <math.h>
#include <stdlib.h>
#include <stdio.h>
%}
DIGIT [0-9]
ID [a-zA-Z][a-zA-Z0-9|_]*
NOTE [^\n]*
STRING [^"]*
%%
[ |\t|\n]+ { /* ignore whitespace */ }
"//"{NOTE} { /* ignore whitespace */ }
["]{STRING}["] {printf("$STRING: %s\n",yytext);}
{DIGIT}+ {printf("$INT: %s(%d)\n",yytext,atoi(yytext));}
{DIGIT}+"."{DIGIT}+ {printf("$FLOAT: %s(%g)\n",yytext,atof(yytext));}
"abstract"|"assert"|"boolean"|"break"|"byte"|"case"|"catch"|"char" {printf("$KEYWORD: \n");}
"class"|"const"|"continue"|"default"|"do"|"double"|"else"|"enum"|"extends"|"final"|"fianlly" {printf("$KEYWORD: \n");}
"float"|"for"|"goto"|"if"|"implements"|"import"|"instanceof"|"int"|"interface"|"long"|"native" {printf("$KEYWORD: \n");}
"new"|"package"|"private"|"protected"|"public"|"return"|"short"|"static"|"strictfp"|"super" {printf("$KEYWORD: \n");}
"switch"|"synchronized"|"this"|"hrow"|"throws"|"transient"|"try"|"void"|"volatile"|"while" {printf("$KEYWORD: \n");}
{ID} {printf("$SYMBOL: %s\n",yytext);}
"++"|"--"|"+="|"-="|"*="|"/="|"!="|"<="|">="|"==" {printf("$OPERATOR: %s\n",yytext);}
"+"|"-"|"*"|"/"|"&&"|"||"|"!"|"="|"<"|">" {printf("$OPERATOR: %s\n",yytext);}
"."|","|";"|":"|"["|"]"|"{"|"}"|"("|")" {printf("$DELIMITER: %s\n",yytext);}
%%
int main(int argc,char **argv)
{
++argv;
--argc;
if(argc>0) yyin=fopen(argv[0],"r");
else yyin=stdin;
yylex();
return 0;
}
int yywrap()
{
return 1;
}
- 生成源代码和编译运行
flex auto_lex.l
gcc -g lex.yy.c -o auto_lex
实验结果
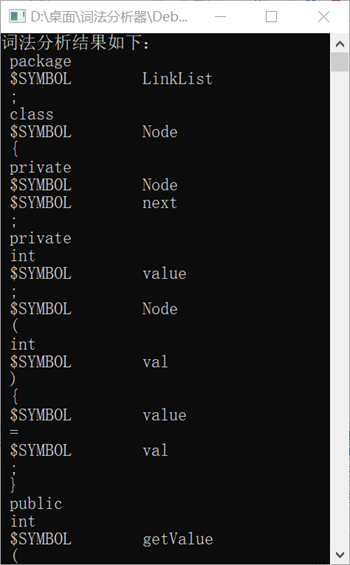
一、C语言编写词法分析器
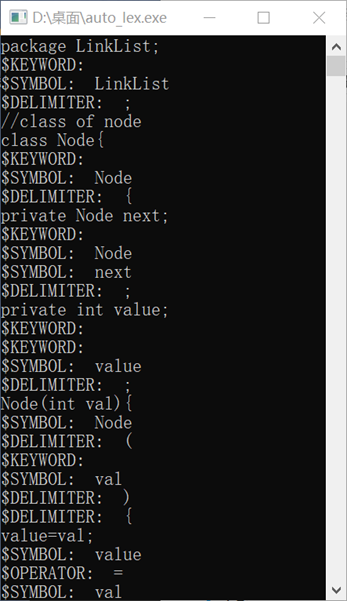
二、学习词法分析器Flex,并编写Flex源程序
编译技术实验:


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









