







 本文详细介绍了Python中列表和字典的基本操作方法,包括列表的扩展、追加、删除及排序等功能,同时深入探讨了字典的创建、更新、查询及删除等关键操作。
本文详细介绍了Python中列表和字典的基本操作方法,包括列表的扩展、追加、删除及排序等功能,同时深入探讨了字典的创建、更新、查询及删除等关键操作。









a = list(range(5))
print(a)
a.extend(['hahaha', '233', [55, 33]]) # 追加一个列表,会把列表拆开(只拆一层,嵌套列表不拆)
print(a)
# 追加一个元组,会把元组拆开
a.extend((5e3, 'alice'))
print(a)
# 追加一个字符串,会把字符串拆成单个字符
a.extend('bob考试不及格')
print(a)
# 用extend追加一个整数,会报错
# a.extend(8)
# print(a)

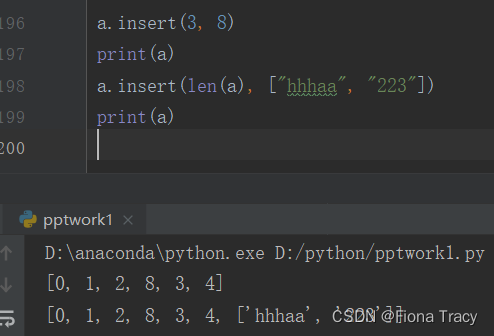

del a
print(a)

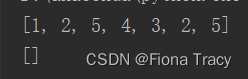
a=[1,2,2,5,4,3,2,5]
a.remove(2)
print(a)
a.clear()
print(a)

A = [[2.4, 3.5, 1.6], [3.14, 22, 33], 'hhh']
A[13:14] = [5, 6] # 下标为13的地方,如果不存在,直接在末尾加入
print(A)

A = [[2.4, 3.5, 1.6], [3.14, 22, 33], 'hhh', 12, 34, 2, 2, 4, 5, 6]
A[1] = "222" # 使用单个索引,可以对单独的列表元素直接赋值
print(A)
A[13:14] = [5, 6] # 不存在的元素赋值,就变成了插入操作。
print(A) # 下标为13的地方,如果不存在,直接在末尾加入
A[1:10] = [] # 对已经存在的元素赋值为空,就变成了删除操作
print(A) # 把下标1后面到下标9范围内的换成等号右边的值


b = [1, 2, 3, 4, 2, 2, 5, 2, 7]
print(b.count(2)) # 计算2有多少个
print(b.index(2)) # 只统计第一次出现的位置
print(b.index(2, 6, 7)) # index(x,start,stop),在start~stop-1的范围内找第一次出现的下标,没有会报错

b = [1, 2, 3, 4, 2, 2, 2, 5, 2, 7]
print(b.pop())
print(b.pop())
print(b.append(55)) #append之后返回None
print(b)

a = [1, 2, 3, 5, 3, 2, 3, 5, 8]
print(a.reverse()) # reverse的返回值是None
print(a)
print(a.sort()) # sort函数的返回值是None
print(a)
a.sort(reverse=True)
print(a)

这代码真能跑!!??
key1 = math.sin
a.sort(key=key1)
print(a)
b = ["python", 'ruby', 'c', 'c++', 'swift']
b.sort(key=len, reverse=True)
print(b)

函数本身也可以赋值给变量,即:变量可以指向函数
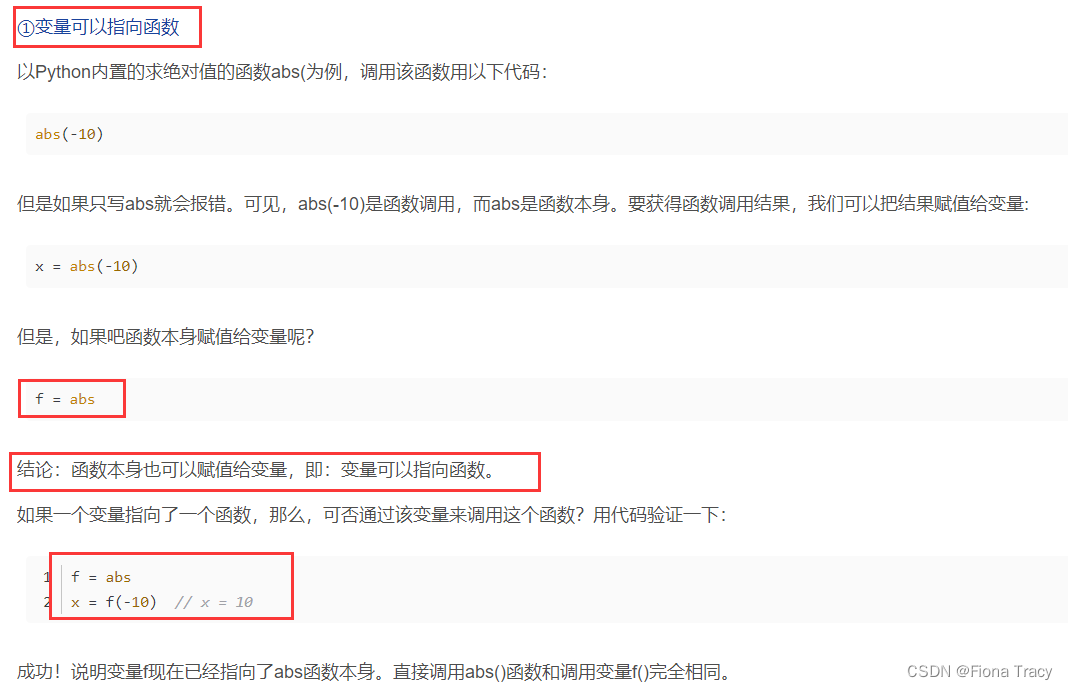



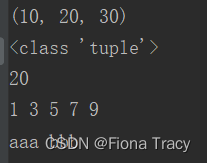
# 序列封包
vals = 10, 20, 30
print(vals)
print(type(vals))
print(vals[1])
# 序列解包:元组
t = tuple(range(1, 10, 2))
a, b, c, d, e = t
print(a, b, c, d, e)
# 序列解包:列表
t = ['aaa', 'bbb']
s1, s2 = t
print(s1, s2)

# 可以只解包部分变量,剩下的继续使用另一个列表保存.
# 变量之前加上*,就表示这个变量其实是一个列表,解包后容纳不了的对象都放在这个变量里
# begin保存前面的所有元素,end保存最后一个元素
*begin, end = range(10) #*begin分前9个,留一个值还有分配给end
print(begin, end)
# first和last保存第一个和最后一个元素,middle保存中间的所有元素
first, *middle, last = range(10)
print(first, middle, last)
# 如果两个变量都加了*呢?会报错
# *a, *b, c = range(10)

# 传入一个列表
mylist = [["张三", 80], ['李四', 92], ['Alice', 85]]
mylist = dict(mylist)
print(mylist)
# 传入一个元组
mytuple = (('王妈', 85), ('春假', 7))
mytuple = dict(mytuple)
print(mytuple)
# 使用关键字参数,注意关键字不能使用表达式
# 例如在下面的例子中,人名不加引号才是正确的
mydict = dict(王麻子=96, 张三=68)
print(mydict)

mydict = dict(张三=99, 历史=5000)
print(mydict)
mydict['川建国'] = 45 # 不存在直接添加
print(mydict)
print('张三' in mydict)
print("王麻子" not in mydict)
# 用方括号访问value,key在访问时带引号
print(mydict["张三"])
del mydict['张三']
print(mydict)
print(mydict.get("张三")) # 不存在的key,get返回None
print(mydict.get('川建国')) # 访问key都要带引号

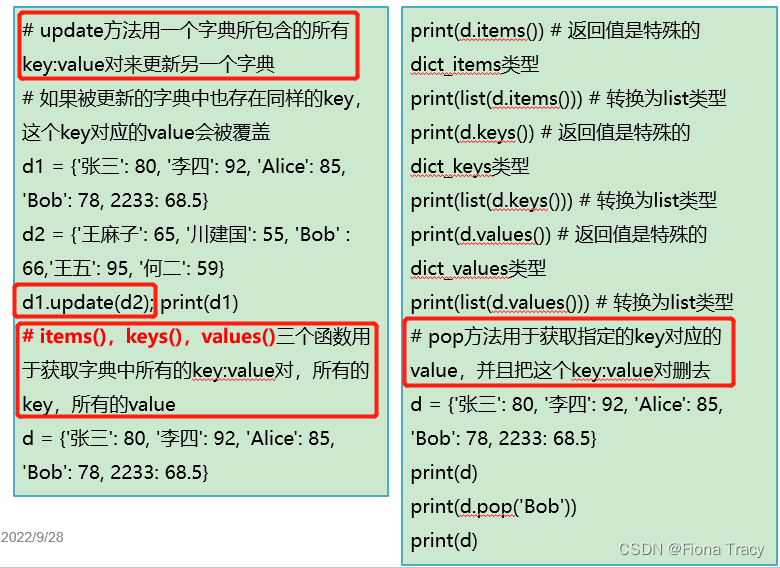
# update方法用一个字典所包含的所有key:value对来更新另一个字典
# 如果被更新的字典中也存在同样的key,这个key对应的value不会被覆盖,还是原来的
d1 = {'张三': 80, '李四': 92, 'Alice': 85, 'Bob': 1111, 2233: 68.5}
d2 = {'王麻子': 65, '川建国': 55, 'Bob': 66, '王五': 95, '何二': 59}
d1.update(d2)
print(d1)

# items(),keys(),values()三个函数用于获取字典中所有的key:value对,所有的key,所有的value
# python字典的items方法返回一个可迭代对象,类型是dict_items,通常用于for循环语句,以元组的形式对字典中的元素进行遍历。
d = {'张三': 80, '李四': 92, 'Alice': 85, 'Bob': 78, 2233: 68.5}
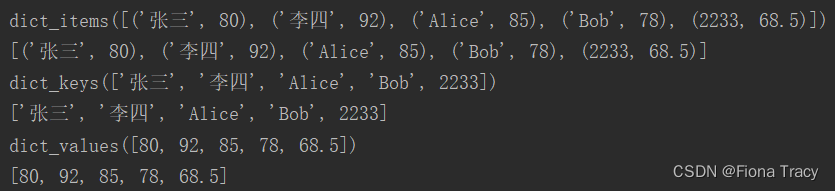
print(d.items()) # 返回值是特殊的dict_items类型
print(list(d.items())) # 转换为list类型
print(d.keys()) # 返回值是特殊的dict_keys类型
print(list(d.keys())) # 转换为list类型
print(d.values()) # 返回值是特殊的dict_values类型
print(list(d.values())) # 转换为list类型
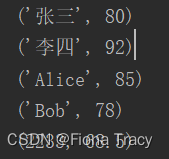
- items()方法返回一个可迭代对象,使用for循环遍历这个可迭代对象时,得到的是一个元组,元组内包含key和 value
d = {'张三': 80, '李四': 92, 'Alice': 85, 'Bob': 78, 2233: 68.5}
for i in d.items():
print(i)
dict = {'老大':'15岁',
'老二':'14岁',
'老三':'2岁',
}
print(dict.items())
for key,values in dict.items():
print(key + '已经' + values + '了')

# pop方法用于获取指定的key对应的value,并且把这个key:value对删去
d = {'张三': 80, '李四': 92, 'Alice': 85, 'Bob': 78, 2233: 68.5}
print(d)
print(d.pop('Bob'))
print(d)


















 185
185

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









