







- https://proceedings.neurips.cc/paper_files/paper/2023/file/602e1a5de9c47df34cae39353a7f5bb1-Paper-Conference.pdf
- https://github.com/salesforce/LAVIS/tree/main/projects/blip-diffusion
- 问题引入
- 针对subject driven image generation的任务,首先根据BLIP2的训练方法训练一个multimodal encoder将subject image映射到和text对齐的representation,也就是输入subject image+category text,输出text -aligned subject representation,之后将该represenation和prompt embedding混合来完成subject driven的生成;
- 本方法可以不需要test time finetuning这个步骤,但是也可以针对特定subject进行微调;
- methods
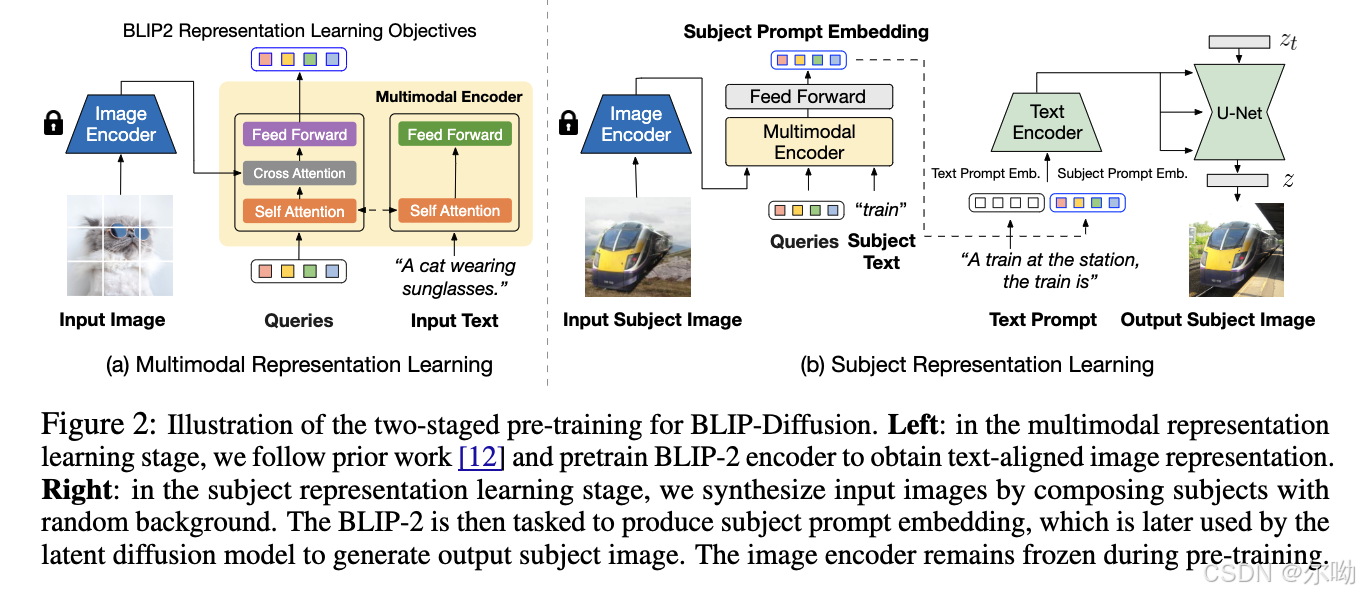
- Multimodal Representation Learning with BLIP-2:预训练模型得到text aligned image representation,这阶段的模型使用了blip-2中的两个模块,一个是image encoder,另一个是multimodal encoder,multimodal encoder输入可学习的query,在self attn层和text信息融合,在cross attn和image信息相融合,输出的结果就是text aligned image representation,损失函数也继承了BLIP-2,分别是image-text contrastive learning (ITC) loss + mage-grounded text generation (ITG) loss + image-text matching (ITM) loss,训练的数据采用的是generic的image-text成对数据;
- Subject Representation Learning stage:第二个pretraining stage,也就是将multimodal encoder得到的representation输入到两层MLP得到的结果和text embedding相拼接,之后作为T2I模型的条件,此时还有一个问题就是multimodal中图片输入含有较多背景,影响生成结果和text的align情况,所以此处的解决办法是合成数据(subject提取出来加上随机背景)来作为encoder的输入;


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









