







- 清华Ð&字节&UTD
- https://github.com/Zj-BinXia/DiffIR
问题引入
- IR任务和image synthesis任务不同点是IR任务本身有一个很强的低质量图片作为先验,所以可以不完全遵循图片生成的范式,本文主要在compact的IPR空间进行DM;
- 本文提出的模型分为三个部分,1)CPEN(compact IR prior extraction network)来得到IPR(IR prior representation),这个作为回归模型的指导信息;2)DIRformer回归模型,类比为decoder;3)DM来通过LQ图片得到IPR
- 训练分为两个stage,首先第一个stage训练CPEN和DIRformer,此时CPEN输入的是高质量图片;第二个stage使用的IPR是DM得到的;
methods
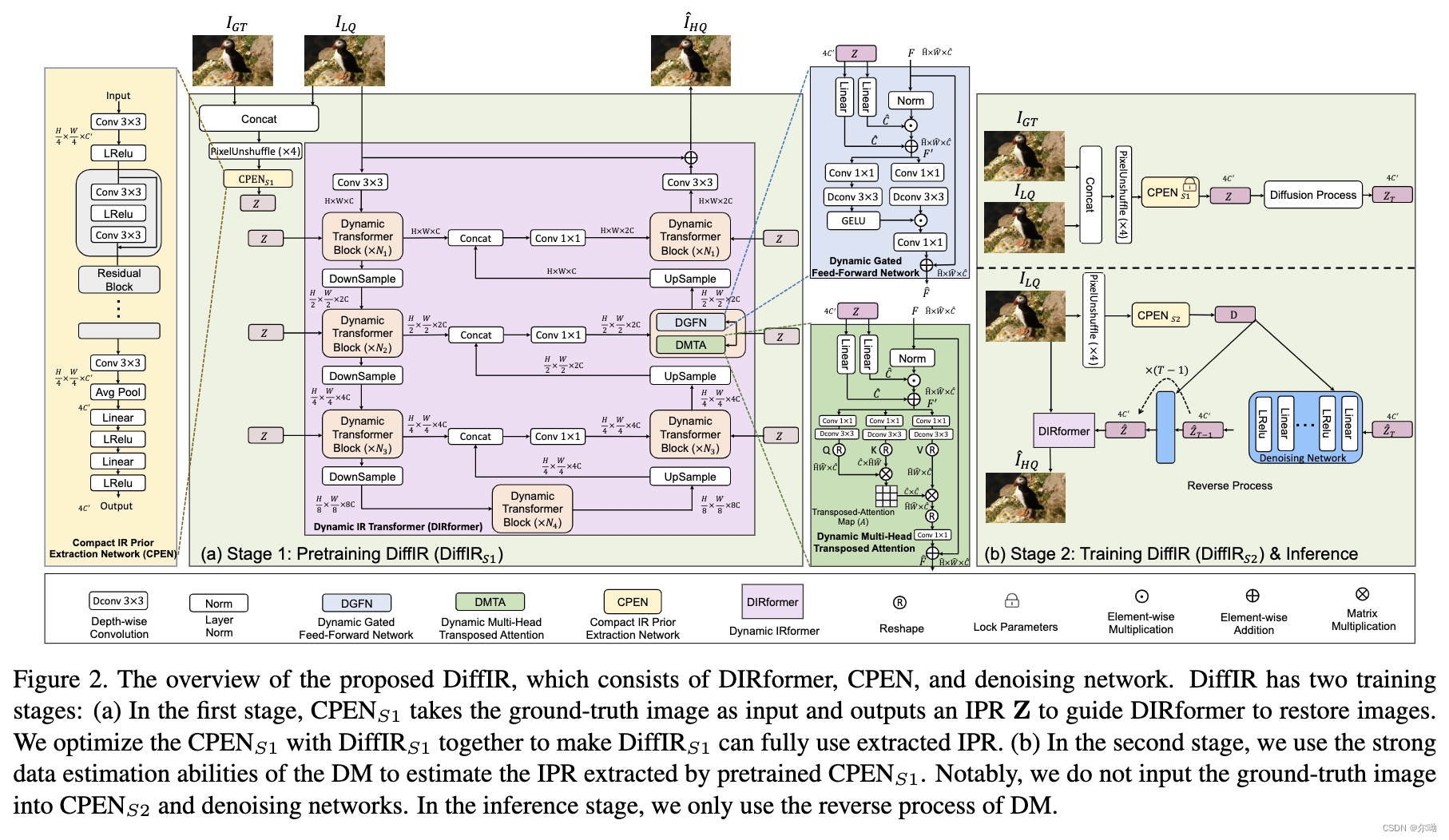
- stage1: 训练CPEN和DIRformer,首先将gt和LQ concat到一起,然后经过pixelunshuffle得到CPEN的输入,输出IPR
Z
=
C
P
E
N
S
1
(
P
i
x
e
l
U
n
s
h
u
f
f
l
e
(
C
o
n
c
a
t
(
I
G
T
,
I
L
Q
)
)
)
,
Z
∈
R
4
C
′
Z = CPEN_{S1}(PixelUnshuffle(Concat(I_{GT},I_{LQ}))),Z\in\mathbb{R}^{4C'}
Z=CPENS1(PixelUnshuffle(Concat(IGT,ILQ))),Z∈R4C′,之后IPR被送到DIRformer的DGFN和DMTA模块,第一阶段训练的损失是GT和生成HQ的L1损失,超分和inpainting任务还有erceptual loss and adversarial
loss; - DMTA的操作 F ′ = W l 1 Z ⊙ N o r m ( F ) + W l 2 Z F' = W_l^1Z\odot Norm(F) + W_l^2 Z F′=Wl1Z⊙Norm(F)+Wl2Z,其中 W l W_l Wl是linear层, F , F ′ F,F' F,F′分别是输入和输出的feature map, Q = W d Q W c Q F ′ , K = W d K W c K F ′ , V = W d V W c V F ′ Q = W_d^QW_c^QF',K=W_d^KW_c^KF',V = W_d^VW_c^VF' Q=WdQWcQF′,K=WdKWcKF′,V=WdVWcVF′,其中 W d W_d Wd是depthwise卷积, W c W_c Wc是pointwise卷积,之后被reshape成 Q ^ ∈ R H ^ W ^ × C ^ , K ^ ∈ R C ^ × H ^ W ^ , V ^ ∈ R H ^ W ^ × C ^ \widehat{Q}\in\mathbb{R}^{\widehat{H}\widehat{W}\times\widehat{C}},\widehat{K}\in\mathbb{R}^{\widehat{C}\times\widehat{H}\widehat{W}},\widehat{V}\in\mathbb{R}^{\widehat{H}\widehat{W}\times\widehat{C}} Q ∈RH W ×C ,K ∈RC ×H W ,V ∈RH W ×C ,最后 F ^ = W c V ^ ⋅ S o f t m a x ( K ^ ⋅ Q ^ / γ ) + F \widehat{F}=W_c\widehat{V}\cdot Softmax(\widehat{K}\cdot \widehat{Q}/\gamma)+F F =WcV ⋅Softmax(K ⋅Q /γ)+F;
- DGFN的操作: F ^ = G E L U ( W d 1 W c 1 F ′ ) ⊙ W d 2 W c 2 F ′ + F \widehat{F}=GELU(W_d^1W_c^1F')\odot W^2_dW_c^2F' + F F =GELU(Wd1Wc1F′)⊙Wd2Wc2F′+F;
- stage2:同时训练三个部分,首先使用 C P E N S 1 CPEN_{S1} CPENS1得到 Z Z Z,之后经过diffusion process得到 Z T ∈ R 4 C ′ Z_T\in\mathbb{R}^{4C'} ZT∈R4C′, C P E N S 2 CPEN_{S2} CPENS2得到 D = C P E N S 2 ( P i x e l U n s h u f f l e ( I L Q ) ) D = CPEN_{S2}(PixelUnshuffle(I_{LQ})) D=CPENS2(PixelUnshuffle(ILQ)),之后进行DM,以D为条件,进行去噪t-1次得到 Z ^ \widehat{Z} Z ,和 C P E N S 1 CPEN_{S1} CPENS1得到的 Z Z Z计算损失 L d i f f = 1 4 C ′ ∑ i = 1 4 C ′ ∣ Z ^ ( i ) − Z ( i ) ∣ L_{diff} = \frac{1}{4C'}\sum_{i = 1}^{4C'}|\widehat{Z}(i) - Z(i)| Ldiff=4C′1∑i=14C′∣Z (i)−Z(i)∣,这损失和stage1的损失在一起计算总损失;

















 2238
2238

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









