







题目:
表: Employee
+--------------+---------+ | Column Name | Type | +--------------+---------+ | id | int | | name | varchar | | salary | int | | departmentId | int | +--------------+---------+ Id是该表的主键列。 departmentId是Department表中ID的外键。 该表的每一行都表示员工的ID、姓名和工资。它还包含了他们部门的ID。
表: Department
+-------------+---------+ | Column Name | Type | +-------------+---------+ | id | int | | name | varchar | +-------------+---------+ Id是该表的主键列。 该表的每一行表示部门ID和部门名。
公司的主管们感兴趣的是公司每个部门中谁赚的钱最多。一个部门的 高收入者 是指一个员工的工资在该部门的 不同 工资中 排名前三 。
编写一个SQL查询,找出每个部门中 收入高的员工 。
以 任意顺序 返回结果表。
查询结果格式如下所示。
示例 1:
输入: Employee 表: +----+-------+--------+--------------+ | id | name | salary | departmentId | +----+-------+--------+--------------+ | 1 | Joe | 85000 | 1 | | 2 | Henry | 80000 | 2 | | 3 | Sam | 60000 | 2 | | 4 | Max | 90000 | 1 | | 5 | Janet | 69000 | 1 | | 6 | Randy | 85000 | 1 | | 7 | Will | 70000 | 1 | +----+-------+--------+--------------+ Department 表: +----+-------+ | id | name | +----+-------+ | 1 | IT | | 2 | Sales | +----+-------+ 输出: +------------+----------+--------+ | Department | Employee | Salary | +------------+----------+--------+ | IT | Max | 90000 | | IT | Joe | 85000 | | IT | Randy | 85000 | | IT | Will | 70000 | | Sales | Henry | 80000 | | Sales | Sam | 60000 | +------------+----------+--------+ 解释: 在IT部门: - Max的工资最高 - 兰迪和乔都赚取第二高的独特的薪水 - 威尔的薪水是第三高的 在销售部: - 亨利的工资最高 - 山姆的薪水第二高 - 没有第三高的工资,因为只有两名员工
解题思路:
RANK()
函数为结果集的分区中的每一行分配一个排名。行的等级由一加上前面的等级数指定。意思是排名会跳,因为有并列排名
以下显示了RANK()函数的语法:
RANK() OVER (
PARTITION BY <expression>[{,<expression>...}]
ORDER BY <expression> [ASC|DESC], [{,<expression>...}]
)在这个语法中:
- 首先,
PARTITION BY子句将结果集划分为分区。RANK()功能在分区内执行,并在跨越分区边界时重新初始化。 - 其次,
ORDER BY子句按一个或多个列或表达式对分区内的行进行排序。
DENSE_RANK()排名不会跳,没有间隙
方法:
先给表加上排名,由于不区分并列,所以用DENSE_RANK():并且需要按照部门来分区,即每个部门的排名重新计算
select d.Name as Department, e.Name as Employee, e.Salary as Salary,
dense_rank() over ( partition by DepartmentId order by Salary desc) as rk
from Employee as e, Department as d
where e.DepartmentId = d.Id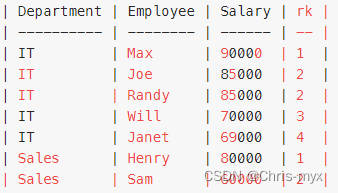
之后再取出每个部门排名前三的
select Department, Employee, Salary
from (
select d.Name as Department, e.Name as Employee, e.Salary as Salary,
dense_rank() over ( partition by DepartmentId order by Salary desc) as rk
from Employee as e, Department as d
where e.DepartmentId = d.Id
) m
where rk <= 3;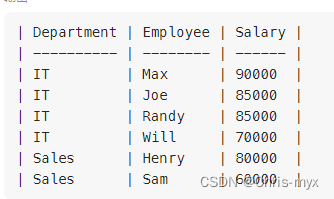

















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









