




目录
HashShuffleManger
普通机制示意图
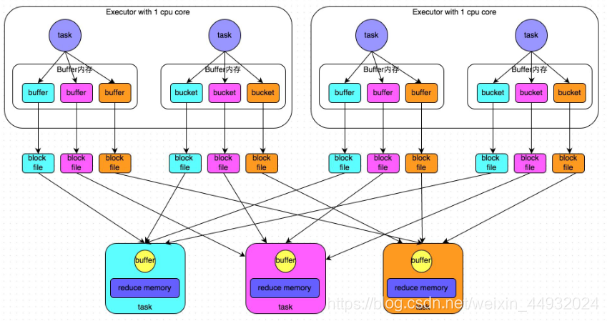
比如:有100个节点(每个节点有一个executor),每个executor有2个cpu core、10个task,那么每个节点会输出10*1000=1万个文件,在map端总共会输出100*10000=100万分文件
- map task的计算结果会根据分区器(默认是hashPartitioner)来决定写入到哪一个磁盘小文件中去。ReduceTask会去Map端拉取相应的磁盘小文件。
- 产生小文件的个数:M(map task的个数)*R(reduce task的个数)
产生的磁盘小文件过多,会导致以下问题:
- 在Shuffle Write过程中会产生很多写磁盘小文件的对象。
- 在Shuffle Read过程中会产生很多读取磁盘小文件的对象。
- 在JVM堆内存中对象过多会造成频繁的gc,gc还无法解决运行所需要的内存 的话,就会OOM。
- 在数据传输过程中会有频繁的网络通信,频繁的网络通信出现通信故障的可能性大大增加,一旦网络通信出
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 727
727

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









