







多任务的三种形式:多线程、多进程、协程
可迭代对象 >> 迭代器 >> 生成器 >> yiled >> yiled多任务 >> grennlet >> gevent 协程、多任务
CPU(中央处理器)
cpu通过操作系统调度运行一些软件,各种软件的代码本身在硬盘里,cpu在运行时,会首先把代码加载到内存里,加载到内存里之后,cpu开始执行,执行完之后写回到硬盘(只有先序列化,才能持久化)
程序:代码指令集合
进程(程序的执行过程):一堆代码跑起来,一个软件跑起来了,这个时候叫一个进程
多线程是一个进程中多个并行执行的任务
程序和进程,一个是静态的一个是动态的;一个QQ软件,没有运行,文件存储在电脑里,这时候就是程序。但是,双击exe驱动后,QQ软件开始运行,这时候就是一个进程
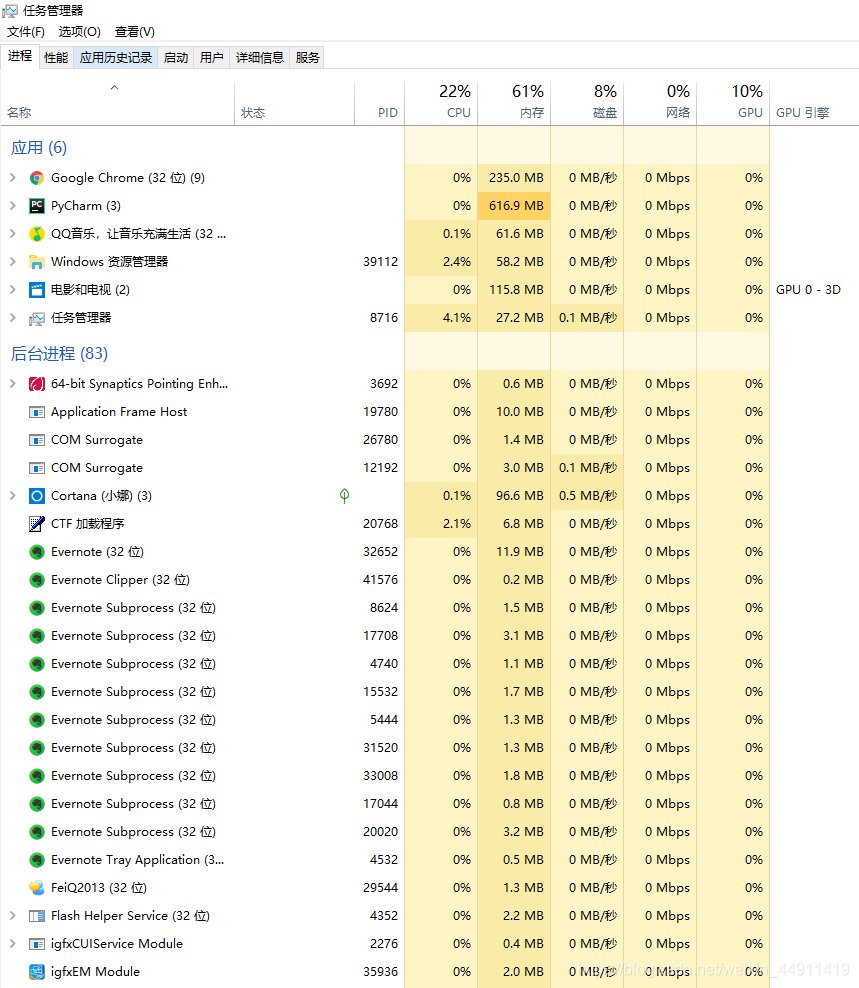
电脑任务管理器里就可以查看进程,PID 是进程ID
线程(指令执行的最小单位):在同一个进程内,还有多个任务并行执行,这叫多线程,比如在腾讯视频这个软件运行的时候,我们调视频音量的同时,视频的进度条不会暂停,画面和声音同时执行。多个任务一起并发进行
进程包含线程,线程是进程里面的一个东西
多任务
想要多个任务同时执行,而不是先执行完一个任务,再去执行另一个,那么就要用到 threading 模块
先看看单任务是什么样:
import time
def sing():
for i in range(3):
print('---在唱歌---')
time.sleep(1)
def dance():
for i in range(3):
print('***在跳舞***')
time.sleep(1)
def main():
sing()
dance()
if __name__ == '__main__':
main()
单任务的原因是:python是解释型语言,是从上到下执行的

再来看看多任务是什么样子:
import time
import threading
def sing():
for i in range(3):
print('---在唱歌---')
time.sleep(1)
def dance():
for i in range(3):
print('***在跳舞***')
time.sleep(1)
def main():
t1 = threading.Thread(target=sing) # 参数指定一个任务;线程A
t2 = threading.Thread(target=dance) # 线程B
t1.start()
t2.start()
# 两个子线程的执行先后顺序 由操作系统决定的,
# 所以先“唱歌”还是先“跳舞”由操作系统决定,而是按照顺序执行的
if __name__ == '__main__':
main() # 多任务的表现形式

看似多任务:同时进行
- 并发:假的多任务,两个任务来回切换执行,看起来是多任务,CPU来回切换
- 并行:这才是真正的多任务,两个任务同时在执行,几个CPU同时工作,不需要来回切换
python中的多线程是并发,是假的多任务
写个比赛:
import threading
import time
def run(name):
for i in range(1,5):
print(name,"跑了%s米" %i)
time.sleep(1)
p1 = threading.Thread(target=run,args=("小王",))
p2 = threading.Thread(target=run,args=("小张",))
p3 = threading.Thread(target=run,args=("小李",))
p1.start()
p2.start()
p3.start()

上面三个人领先都是随机的
这三个线程在执行着同一个代码;
一个仓库(叫list,三个线程执行同一段代码往仓库放东西 —> +1,四个线程执行同一段代码从仓库往外拿东西 —> -1)
import threading, time
list = []
def cun(name):
list.append("方便面")
print(name, "存了一袋方便面,仓库剩余:", len(list))
def qu(name):
if len(list) == 0: # 如果仓库没货了
time.sleep(1) # 判断仓库里的值为0就休眠等一会儿,等仓库来货了再取走
else:
list.pop()
print(name, "取了一袋方便面,仓库剩余:", len(list))
p1 = threading.Thread(target=cun, args=("p1",))
p2 = threading.Thread(target=cun, args=("p2",))
p3 = threading.Thread(target=cun, args=("p3",))
p4 = threading.Thread(target=qu, args=("p4",))
p5 = threading.Thread(target=qu, args=("p5",))
p6 = threading.Thread(target=qu, args=("p6",))
p7 = threading.Thread(target=qu, args=("p7",))
p1.start()
p2.start()
p3.start()
p4.start()
p5.start()
p6.start()
p7.start()

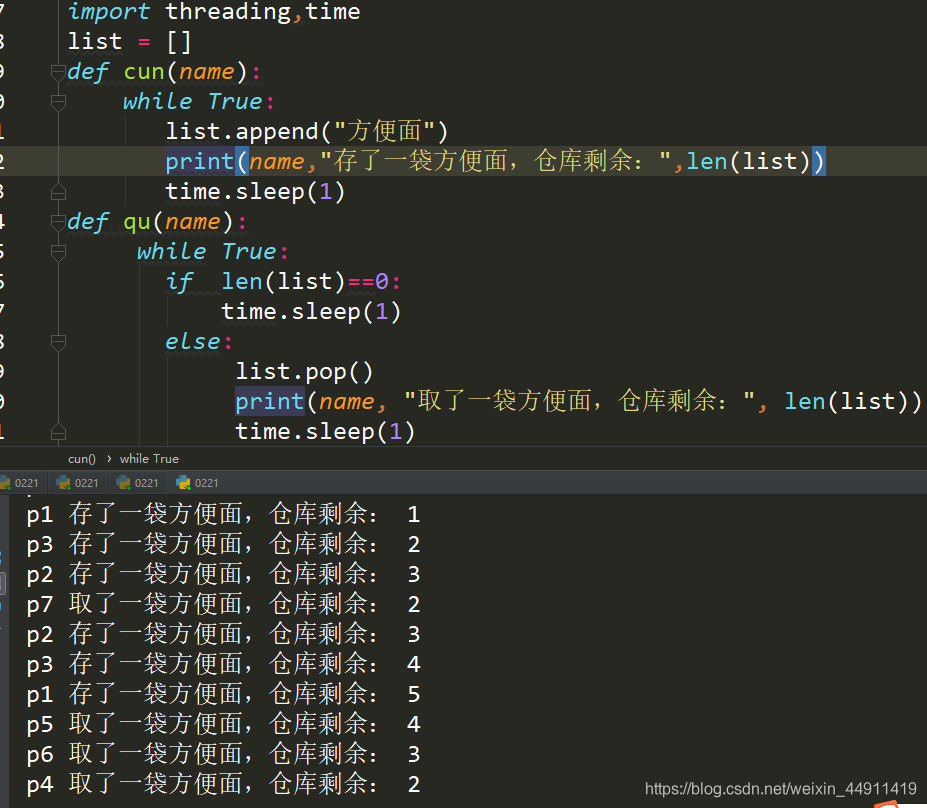
下面实现一个动态的三个线程存货、四个线程取货是什么样子:
import threading,time
list = []
def cun(name):
while True:
list.append("方便面")
print(name,"存了一袋方便面,仓库剩余:",len(list))
time.sleep(1)
def qu(name):
while True:
if len(list)==0:
time.sleep(1)
else:
list.pop()
print(name, "取了一袋方便面,仓库剩余:", len(list))
time.sleep(1)
p1 = threading.Thread(target=cun,args=("p1",))
p2 = threading.Thread(target=cun,args=("p2",))
p3 = threading.Thread(target=cun,args=("p3",))
p4 = threading.Thread(target=qu,args=("p4",))
p5 = threading.Thread(target=qu,args=("p5",))
p6 = threading.Thread(target=qu,args=("p6",))
p7 = threading.Thread(target=qu,args=("p7",))
p1.start()
p2.start()
p3.start()
p4.start()
p5.start()
p6.start()
p7.start()
import threading,time
list = [] # 这里用列表相当于 仓库
for i in range(10):
list.append("薯条")
def qu(name):
while len(list)>0:
time.sleep(0.1)
list.pop()
print(name,"取了一份薯条,剩余:",len(list))
t1 = threading.Thread(target=qu,args=("t1",)) #定义 3个 线程
t2 = threading.Thread(target=qu,args=("t2",))
t3 = threading.Thread(target=qu,args=("t3",))
t1.start()
t2.start()
t3.start()
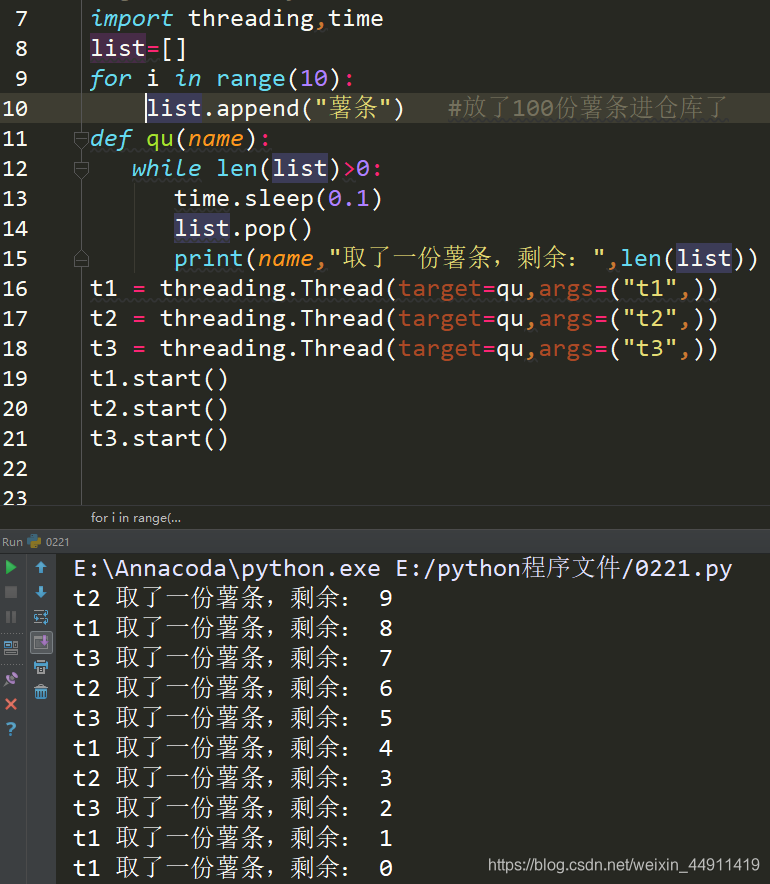
薯条取完之后开始报错:(出现了高并发的问题)
查看线程数量:
import time
import threading
def sing():
for i in range(3):
print('---在唱歌---')
time.sleep(1)
def dance():
for i in range(3):
print('***在跳舞***')
time.sleep(1)
def main():
t1 = threading.Thread(target=sing) # 参数指定一个任务;子线程A
t2 = threading.Thread(target=dance) # 子线程B
t1.start() # 子线程B启动 可以去执行代码
t2.start() # 子线程B启动 此时此刻 三个线程
while True:
data = threading.enumerate()
num = len(data) # 根据列表的长度来看此时有多少个线程
print('此时此刻线程的数量为',num)
print(data)
time.sleep(1)
if num <= 1: # 证明子线程执行完毕,死掉了,只剩下一个主线程
break
if __name__ == '__main__':
main() # 主线程 最后进行一个等待,然后一起结束


小结:
-
并发(假的多任务):指的是任务数多余CPU核数,通过操作系统的各种任务调度算法,实现用多个任务“一起”执行(实际上总有一些任务不在执行,因为切换任务的速度相当快,看上去一起执行而已)
-
并行(真的多任务):指的是任务数小于等于CPU核数,即任务真的是一起执行的
-
使用 threading模块 里面的 Thread类 创建出实例对象,然后通过 start() 方法 真的去产生一个新的线程
-
解释器中来执行代码的叫做 主线程
-
通过 start()方法 创建出来的叫做 子线程
-
主线程会等待子线程全部结束之后才会结束
-
当调用 Thread 的时候,不会创建线程,当调用 Thread 创建出来的实例对象的 start() 方法 的时候才会创建线程以及让这个线程开始运行
-
查看当前线程:利用 threading 里面的 enumerate() 函数就能返回一个列表,当前的线程作为单个元素存放在列表之中
想让子线程执行多个函数,怎么办:
可以让多个函数存在于类当中,让子线程去指定类
import threading
import time
# 如果想让子线程可以去一个类里面执行代码
class diyThread(threading.Thread): # 继承threading模块里面的Thread类
# 固定的语法格式
def run(self):
for i in range(3):
print('我在类里面')
time.sleep(1)
# 去打印当前的线程数量,以此来证明子线程可以执行到类里面
print('当前的线程数量为:',len(threading.enumerate()))
if __name__ == '__main__':
# 创建出子线程
# threading.Thread() # 指定执行函数代码的
t1 = diyThread() # 创建出子线程对象
# 启动子线程 让它去指定的地方执行代码
t1.start() # 会去到创建是哪个类,就去哪个类里面去执行
time.sleep(4) # 主线程4秒钟等待完毕,子线程已经死掉了
print('当前的线程数量为:',len(threading.enumerate()))

线程安全
-----> 像上面的问题,如果想让线程安全,可以在**‘取’方法**(那加锁 ,这个安不安全说的是数据的安不安全,一个面包放在仓库里,一群很久没吃饭的人没有秩序的冲进仓库抢面包,这时候面包是不安全的
====> 同步(一群抢面包的人,排好队一个抢完了下一个),速度慢
非线程安全(也有叫:线程不安全) ====> 异步(一群抢面包的人同时抢,各抢各的),速度快
多个线程操作同一个对象时,才会出现线程安全和非线程安全
具体写工程的时候,到底是选择快还是慢,看需求!
另一种实现线程的方式(类 面向对象):
继承方式实现多线程
import threading
class MyThread(threading.Thread):
def __init__(self):
threading.Thread.__init__(self) # 相当于创建了一个Thread对象
def run(self): # 重写方法是因为要覆盖,方法不一样
for i in range(100): # 这里面没有目标方法,把目标方法的内容写到run方法里就ok了
print(i)
t1 = MyThread() # 创建一个对象
t2 = MyThread() # 再创建一个对象
t1.start()
t2.start()
创建自己的类MyThread,继承Thread类
函数的方式执行 是直接调用方法执行目标函数,继承的方式执行 是把目标函数放到子类的方法里>
多线程共享全局变量
在一个进程内的所有线程共享全局变量,很方便在多个线程间共享数据
缺点就是,线程是对全局变量随意修改可能造成多线程之间对全局变量的混乱(即 线程非安全)
先来复习一下全局变量:
num1 = 1
def demo1():
# 升级全局变量
global num1 # 局部变量 >>升级>> 全局变量
num1 += 1 # 定义完全局变量之后,是可以在局部自己进行修改的
print('在demo1中,num1的值为:',num1)
def demo2():
print('在demo2中,num1的值为:',num1)
def main():
demo1() # 先修改 再打印 2
demo2() # 打印修改过后的值 2
if __name__ == '__main__':
main()
子线程B中打印的是被子线程A修改过的后的全局变量
证明了多线程之间是可以共享全局变量

单线程:只有一个主线程去执行代码,,
多线程传参:
import threading,time
list = [1,2,3] # 全局变量,并且列表也是个可变类型,不需要通过global去指定为全局变量进行操作
def demo1(i): # 传参,后面的args=(4,)这个元组,就是来传的
list.append(i)
print('在demo1中,list的值为:',list)
def demo2():
print('在demo2中,list的值为:',list)
def main():
# 创建两个子线程,分别去执行 demo1函数 和 demo2函数
# target是用来指定将来子线程去哪里执行代码
# args是传参的
t1 = threading.Thread(target=demo1,args=(4,)) # 子线程A去修改全局变量
t2 = threading.Thread(target=demo2) # 子线程B去打印全局变量 是否为修改过后的值
t1.start() # 列表list追加数据 4 >> [1,2,3,4]
time.sleep(0.1)
t2.start() # 同样也为 [1,2,3,4]
if __name__ == '__main__':
main()

多线程共享全局变量的意义,比如说应用在爬虫中:
1、爬取数据
2、清洗数据
3、数据保存
这样三个线程(多线程)共享全局变量,就可以很高效率
多线程资源竞争问题
资源竞争问题的前提是,多个线程操作同一个资源
import threading
num = 0 # 全局变量,不可变类型
def demo1():
global num
num += 1
print('demo1中,num的值为:',num)
def demo2():
global num
num += 1
print('demo2中,num的值为:',num)
def main():
t1 = threading.Thread(target=demo1)
t2 = threading.Thread(target=demo2)
t1.start()
t2.start()
if __name__ == '__main__':
main()

demo1中的num值为 1,是因为,在demo1函数中进行了全局变量num的自加;demo2中的num值为2,是因为,在demo2函数中进行了全局变量num的自加
由此,子线程A 和 子线程B 都对全局变量num进行了操作
但是,只有数据够大,才能显示出多线程竞争资源的弊端,,误差太大,,资源竞争的效果也就越来越明显了
import threading,time
num = 0
def demo1(a):
global num
for i in range(a):
num += 1
print('demo1中,num的值为:',num)
def demo2(a):
global num
for i in range(a):
num += 1
print('demo2中,num的值为:',num)
def main():
num1 = 1000000
t1 = threading.Thread(target=demo1,args=(num1,))
t2 = threading.Thread(target=demo2,args=(num1,))
t1.start()
t2.start()
time.sleep(3)
print('在主线程main中,num的值为:',num)
if __name__ == '__main__':
main()

出现上面的问题,需要明确一个知识点:
多线程是假的多任务,只是一个并发现象,其实是一个CPU在处理,来回切换而已
但是由于CPU切换的出错,可能存在把全局变量同一个值重复的赋值,最后程序运行出的值和我们预测的不一致

同步异步概念
同步 >> 两个人 有规律地进行一件事,你说一句话,我再接一句话,不能插嘴;左脚抬起来,左脚到地上的时候,右脚才抬起来,右脚到地上的时候,左脚才抬起来…
异步 >> 左脚抬起来,还没落地,右脚就要抬起来了,没有规律,没有先后顺序,跌倒…
真正需要去解决的问题,是资源竞争,多线程共享全局变量,不会导致在关键时候被强行切换,从而导致了问题(不能说A在上厕所的时候,B也强行进入。。。)
但是,可以在A出厕所前,上锁,这样B就不能随便进了
互斥锁的应用:买火车票
全局变量:只剩一张火车票了
多个线程:1、可以去柜台购买;2、网络购票
在小明完成付款的一系列步骤中,全局变量(票)是上锁的,彻底完成付款之后,全局变量释放锁;如果没有锁的机制,那可能在小明把钱付出去的过程中票被被人买走了,结果小明钱已经付了,这就很崩溃;
如果小明买票付款的过程中反悔了,那么这个票的锁就释放掉,就又有票了。
所以只在买票人付款的过程中,才进行上锁
线程锁,又叫 互斥锁
lock.acquire() 、 lock.release()
互斥锁为资源引入一个状态:锁定/非锁定
某个线程要更改共享数据时,先将其锁定,此时资源的状态为“锁定”,其他线程不能更改,直到该线程释放资源,将资源的状态变为“非锁定”,其它的线程才能再次锁定该资源。
互斥锁保证了每次只有一个线程进行写入操作,从而保证了多个线程情况下数据的正确性
threading 模块中定义了 Lock类,可以方便的处理锁
import threading,time
num1 = 0
def demo1(a):
global num1
for i in range(a):
lock1.acquire() # 锁住它,不让他在执行的时候被强行切换任务
num1 += 1
# 开锁,执行完了关键的部分之后,就允许CPU切换任务了
lock1.release()
print('demo1中,num1的值为:',num1)
def demo2(a):
global num1
for i in range(a):
lock1.acquire() # 上锁
num1 += 1 # 锁住它,不让它在执行的时候被强行切换任务
lock1.release() # 开锁
print('demo2中,num1的值为:',num1)
lock1 = threading.Lock() # 创建一把锁的对象
def main():
num2 = 1000000
t1 = threading.Thread(target=demo1,args=(num2,))
t2 = threading.Thread(target=demo2,args=(num2,))
t1.start()
t2.start()
time.sleep(1.5)
print('在主线程main中,num1的值为:',num1)
if __name__ == '__main__':
main()

一个互斥锁,两个线程进行抢夺,哪个线程抢到了,就立马上锁,上锁之后,CPU就不会再调度它,全局变量就不能再被其他线程执行
lcok.acquire()、lock.release() 上锁的部分越少越好,如果把一整个函数都锁起来,那就变成单任务了
死锁
如何避免:可以设置一个超时等待、把代码写好一点
死锁是互斥锁里面的现象,就是对通过一个资源进行操作时,需要等待上一个线程操作结束并释放锁
仓储模型(生产消费者模型)
两个生产者,三个生产者,在取的地方加锁
join
join的作用是挂起主线程,待当前线程结束之后,再继续执行挂起主线程( 可以指定挂起状态时间 )
daemon 设置守护进程
join有一个 timeout 参数(知识点四)
import threading,time
def run():
for i in range(100):
time.sleep(0.1)
print("子线程结束")
t1 = threading.Thread(target=run)
t1.setDaemon(True)
t1.start()
t1.join(timeout=5) # timeout是join里的一个参数,给它5秒的超时时间
print("主线程结束") # 主线程已经结束了,子线程还在跑着
因为子线程是守护进程,主线程结束了,子线程一定会结束,这个时候不是说无限的等下去,而是只等 5 秒钟,5 秒钟能干完就干,不能干完就杀死
知识点一:
当一个进程启动之后,会默认产生一个主线程,因为线程是程序执行流的最小单元,
当设置多线程时,主线程会创建多个子线程,在python中,默认情况下
(其实就是setDaemon(False)),主线程执行完自己的任务以后,就退出了,
此时子线程会继续执行自己的任务,直到自己的任务结束,例子见下面一。
知识点二:
当我们使用setDaemon(True)方法,设置子线程为守护线程时,
主线程一旦执行结束,则全部线程全部被终止执行,可能出现的情况就是,
子线程的任务还没有完全执行结束,就被迫停止,例子见下面二。
知识点三:
此时join的作用就凸显出来了,join所完成的工作就是线程同步,
即主线程任务结束之后,进入阻塞状态,一直等待其他的子线程执行结束之后,
主线程在终止,例子见下面三。
知识点四:
join有一个timeout参数:
当设置守护线程时,含义是主线程对于子线程等待timeout的时间将会杀死该子线程,最后退出程序。
所以说,如果有10个子线程,全部的等待时间就是每个timeout的累加和。简单的来说,
就是给每个子线程一个timeout的时间,让他去执行,时间一到,不管任务有没有完成,直接杀死。
没有设置守护线程时,主线程将会等待timeout的累加和这样的一段时间,时间一到,
主线程结束,但是并没有杀死子线程,子线程依然可以继续执行,直到子线程全部结束,程序退出。
一、Python多线程的默认情况
import threading
import time
def run():
time.sleep(2)
print('当前线程的名字是: ', threading.current_thread().name)
time.sleep(2)
if __name__ == '__main__':
start_time = time.time()
print('这是主线程:', threading.current_thread().name)
thread_list = []
for i in range(5):
t = threading.Thread(target=run)
thread_list.append(t)
for t in thread_list:
t.start()
print('主线程结束!' , threading.current_thread().name)
print('一共用时:', time.time()-start_time)
关键点:
我们的计时是对主线程计时,主线程结束,计时随之结束,打印出主线程的用时。
主线程的任务完成之后,主线程随之结束,子线程继续执行自己的任务,
直到全部的子线程的任务全部结束,程序结束。
二、设置守护线程
import threading
import time
def run():
time.sleep(2)
print('当前线程的名字是: ', threading.current_thread().name)
time.sleep(2)
if __name__ == '__main__':
start_time = time.time()
print('这是主线程:', threading.current_thread().name)
thread_list = []
for i in range(5):
t = threading.Thread(target=run)
thread_list.append(t)
for t in thread_list:
t.setDaemon(True)
t.start()
print('主线程结束了!' , threading.current_thread().name)
print('一共用时:', time.time()-start_time)
注意请确保 setDaemon() 在 start() 之前。
关键点:
非常明显的看到,主线程结束以后,子线程还没有来得及执行,整个程序就退出了。
三、join的作用
import threading
import time
def run():
time.sleep(2)
print('当前线程的名字是: ', threading.current_thread().name)
time.sleep(2)
if __name__ == '__main__':
start_time = time.time()
print('这是主线程:', threading.current_thread().name)
thread_list = []
for i in range(5):
t = threading.Thread(target=run)
thread_list.append(t)
for t in thread_list:
t.setDaemon(True)
t.start()
for t in thread_list:
t.join()
print('主线程结束了!' , threading.current_thread().name)
print('一共用时:', time.time()-start_time)
关键点:
可以看到,主线程一直等待全部的子线程结束之后,主线程自身才结束,程序退出。
----------------------------死锁与递归锁-------------------------------------
RLock
可重复锁,是线程相关的锁。同样是线程相关的还有threading.local。
通俗地讲:你想在锁中加锁,就需要用到可重入锁,只有可重入锁是在锁里面加锁的,为什么加两层锁呢?多线程操作同一个对象时,加一把锁,但是,当多个线程操作多余一个对象的时候,就要加多个锁。比如说,一个仓库,咱们只考虑仓库取东西的话,一个门,咱们只在仓库上加了一把锁,把仓库看作一个对象的话,锁的话锁的就是数据,那么多线程就操作的是同一个仓库同一个对象,咱么锁的是仓库,那就是操作的就是两对象(?),那就得用两把锁,这两把锁还得嵌套着锁,在锁中有锁-------> 才能用到 可重入锁,那种普通的互斥锁是不行的。
举个例子,哲学家就餐问题
一共五个哲学家,每两个人之间一支筷子, 然后每个人吃饭都只能拿自己身边左右的筷子吃饭,当然如果拿了两边的筷子,身边的人就没有筷子吃饭了
这样,,谁都拿不全一双筷子去吃饭,这个情况叫 死锁,死锁是锁吗?死锁 不是锁,是一个现象,是一个问题!
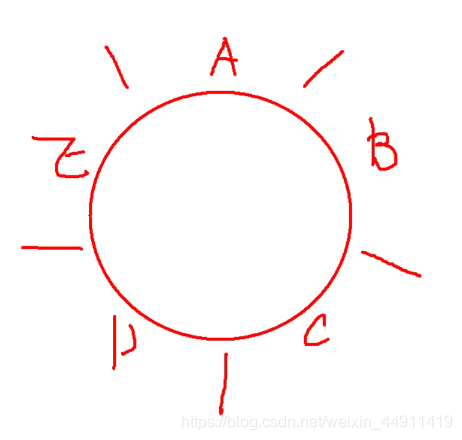
当两个线程同时操作一个对象时,就会出现死锁问题
解决的思路是:哪个线程先执行,就把它执行的“左筷子”锁住,然后再把“右筷子”锁住,那就可以“就餐了”
import threading,time
rlock1 = threading.RLock() #创建对象rlock1
rlock2 = threading.RLock()
rlock3 = threading.RLock()
rlock4 = threading.RLock()
rlock5 = threading.RLock()
class ZheXueJia():
def __init__(self,left,right):
self.left = left
self.right = right
z1 = ZheXueJia(rlock5,rlock1) #哲学家1的左边是筷子5,右边是筷子1
z2 = ZheXueJia(rlock1,rlock2) #哲学家2的左边是筷子1,右边是筷子2
z3 = ZheXueJia(rlock2,rlock3) #哲学家3的左边是筷子2,右边是筷子3
z4 = ZheXueJia(rlock3,rlock4) #哲学家4的左边是筷子3,右边是筷子4
z5 = ZheXueJia(rlock4,rlock5) #哲学家5的左边是筷子4,右边是筷子5
def run(z,name): #写个run()函数
f = z.left.acquire() #获取左筷子(获取锁)
if f:
print(name,"获取左筷子")
ff = z.right.acquire() # 获取右筷子(获取锁)
if ff:
print(name, "获取右筷子")
print("哲学家开始就餐",name)
time.sleep(1) # 休眠一下
# 哲学家吃完了就开始释放筷子,释放筷子从 右筷子 开始释放 ,再释放左筷子
z.right.release()
z.left.release()
# 五个线程:
t1 = threading.Thread(target=run,args=(z1,"z1"))
t2 = threading.Thread(target=run,args=(z2,"z2"))
t3 = threading.Thread(target=run,args=(z3,"z3"))
t4 = threading.Thread(target=run,args=(z4,"z4"))
t5 = threading.Thread(target=run,args=(z5,"z5"))
t1.start()
t2.start()
t3.start()
t4.start()
t5.start()
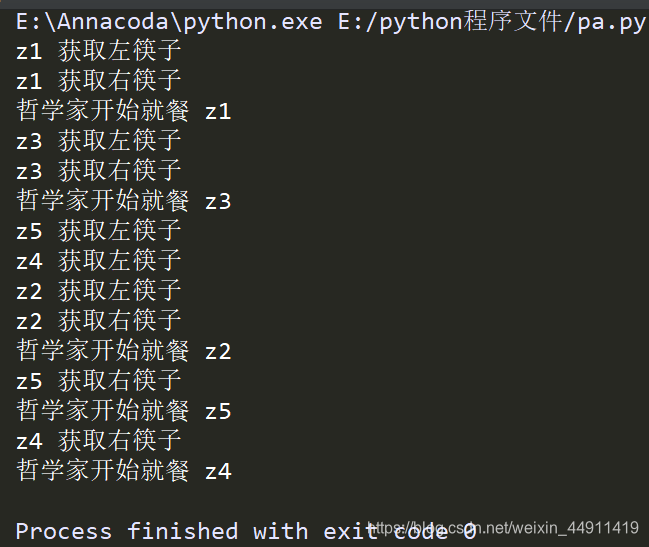
这样就不会出现死锁现象
线程A获得可重用锁,并可以多次成功获取,不会阻塞。最后要再线程A中和acquire次数相同的release。
例1:
import threading
lock = threading.Lock()
lock.acquire()
ret = lock.acquire()
print(1,ret)
运行结果:
阻塞中
在主线程中,使用阻塞锁加锁后,再次获取锁就阻塞了,比如第一个锁 释放掉才可以获取。
例2:
import threading
lock = threading.Lock()
lock.acquire()
ret = lock.acquire(False)
print(1,ret)
运行结果:
1 False
使用非阻塞锁获取,返回False,表示没有获取到锁。
例3:
import threading
lock = threading.RLock()
ret = lock.acquire()
print(ret)
ret = lock.acquire()
print(ret)
运行结果:
True
True
使用RLock可重入锁,第一个锁没有释放,第二个也能获取到锁。
例4:
import threading
lock = threading.RLock()
ret = lock.acquire()
print(ret)
ret = lock.acquire(timeout=3)
print(ret)
ret = lock.acquire(True)
print(ret)
ret = lock.acquire(False)
print(ret)
lock.release()
lock.release()
lock.release()
lock.release()
运行结果:
True
True
True
True
与acquire相应次数的release释放。
例5:
import threading
lock = threading.RLock()
ret = lock.acquire()
print(ret)
ret = lock.acquire(timeout=3)
print(ret)
ret = lock.acquire(True)
print(ret)
ret = lock.acquire(False)
print(ret)
lock.release()
lock.release()
lock.release()
lock.release()
lock.release() #多release一次
运行结果:
True
True
True
True
Traceback (most recent call last):
File “C:/python/test.py”, line 18, in
lock.release()
RuntimeError: cannot release un-acquired lock
但只要多一个release就会抛RuntimeError异常,提示无法释放一个un-acquire的锁。
例6:
import threading
lock = threading.RLock()
def subThread(lock:threading.RLock):
lock.release()
ret = lock.acquire()
print(ret)
ret = lock.acquire(timeout=3)
print(ret)
ret = lock.acquire(True)
print(ret)
ret = lock.acquire(False)
print(ret)
t = threading.Thread(target=subThread,args=(lock,))
t.start()
运行结果:
True
True
True
True
Exception in thread Thread-1:
Traceback (most recent call last):
File “C:/python/test.py”, line 6, in subThread
lock.release()
RuntimeError: cannot release un-acquired lock
acquire是在主线程获取了四个,新起了一次子线程,在子线程中release,
抛出RuntimeError异常,说明RLock是线程级别的,在哪个线程acquire的,
就需要在这个线程release,其它无法release。也就是说RLock无法跨线程。需要跨线程就得使用Lock。
死锁
代码演示
from threading import Thread, Lock
import time
mutexA = Lock()
mutexB = Lock()
class MyThread(Thread):
def run(self):
self.f1()
self.f2()
def f1(self):
mutexA.acquire()
print('%s 拿到A锁' % self.name)
mutexB.acquire()
print('%s 拿到B锁' % self.name)
mutexB.release()
mutexA.release()
def f2(self):
mutexB.acquire()
time.sleep(1)
print('%s 拿到B锁' % self.name)
mutexA.acquire()
print('%s 拿到A锁' % self.name)
mutexA.release()
mutexB.release()
if __name__ == '__main__':
for i in range(10):
t = MyThread()
t.start()
该种情况出现死锁:
代码讲解
由于Thread-1创建的比较快,所以Thread-1先抢到A锁,继而顺利成章的拿到B锁,当Thread-1释放掉A锁时,另外9个线程抢A锁,于此同时,Thread-1抢到B锁,而此时Thread-2抢到A锁,这样Thread-1、Thread-2就等待彼此把锁释放掉,这样程序就卡住了,解决这个问题就用到了递归锁。
递归锁
代码演示
from threading import Thread, Lock, RLock
import time
# mutexA = Lock()
# mutexB = Lock()
mutexA = mutexB = RLock()
class MyThread(Thread):
def run(self):
self.f1()
self.f2()
def f1(self):
mutexA.acquire()
print('%s 拿到A锁' % self.name)
mutexB.acquire()
print('%s 拿到B锁' % self.name)
mutexB.release()
mutexA.release()
def f2(self):
mutexB.acquire()
time.sleep(1)
print('%s 拿到B锁' % self.name)
mutexA.acquire()
print('%s 拿到A锁' % self.name)
mutexA.release()
mutexB.release()
if __name__ == '__main__':
for i in range(10):
t = MyThread()
t.start()
可重入锁和互斥锁原理上的区别就在这里:
递归锁 是通过计数完成对锁的控制的,当acquire一次,count+=1,release一次,count-=1,
当count=0,所有的线程都可以对锁进行抢夺。从而避免了死锁的产生。
---------------------------------Semaphore(信号量)----------------------------------------
互斥锁 同时只允许一个线程更改数据,(用互斥锁,是多个线程操作一个对象时;用锁中锁 可重入锁 是在多个线程 操作 多个对象时),还有一个排他锁和互斥锁一样
而 *Semaphore 是同时允许一定数量的线程更改数
据 **
比如厕所有 3 个坑,那最多只允许 3 个人上厕所,后面的人只能等里面有人出来了才能再进去
import threading,time
s = threading.Semaphore(3) # 同时允许三个线程
def run(name):
s.acquire()
print(name,"开始执行")
time.sleep(5)
print(name,"执行结束")
s.release()
t1 = threading.Thread(target=run,args=("t1",))
t2 = threading.Thread(target=run,args=("t2",))
t3 = threading.Thread(target=run,args=("t3",))
t4 = threading.Thread(target=run,args=("t4",))
t5 = threading.Thread(target=run,args=("t5",))
t6 = threading.Thread(target=run,args=("t6",))
t7 = threading.Thread(target=run,args=("t7",))
t8 = threading.Thread(target=run,args=("t8",))
t9 = threading.Thread(target=run,args=("t9",))
t10 = threading.Thread(target=run,args=("t10",))
t1.start()
t2.start()
t3.start()
t4.start()
t5.start()
t6.start()
t7.start()
t8.start()
t9.start()
t10.start()
开始 t1、t2、t3 三个线程先同步开始执行
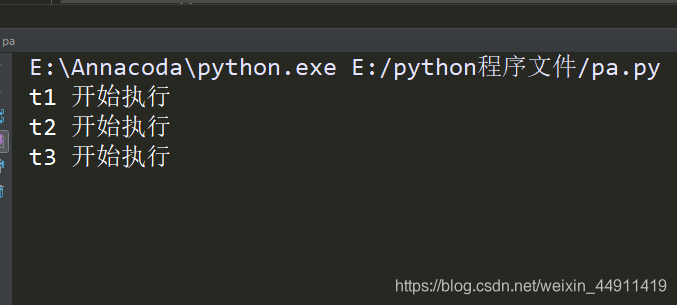
5秒之后:t1、t2、t3这三个线程执行结束, t4、t5、 t6再开始
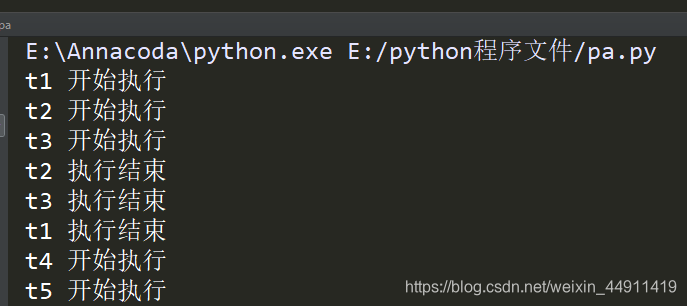
下面做一个计时:
import threading,time
#s = threading.Semaphore(3)
s = threading.Lock() # 不用信号量,用互斥锁的话
def run(name):
s.acquire()
print(name,"开始执行")
time.sleep(1)
print(name,"执行结束")
s.release()
start_time = time.time()
t1 = threading.Thread(target=run,args=("t1",))
t2 = threading.Thread(target=run,args=("t2",))
t3 = threading.Thread(target=run,args=("t3",))
t4 = threading.Thread(target=run,args=("t4",))
t5 = threading.Thread(target=run,args=("t5",))
t6 = threading.Thread(target=run,args=("t6",))
t7 = threading.Thread(target=run,args=("t7",))
t8 = threading.Thread(target=run,args=("t8",))
t9 = threading.Thread(target=run,args=("t9",))
t10 = threading.Thread(target=run,args=("t10",))
t1.start()
t2.start()
t3.start()
t4.start()
t5.start()
t6.start()
t7.start()
t8.start()
t9.start()
t10.start()
# 把十个主线程挂起,等他们全部都执行完之后,再算时间,这才是总共运行的时间
t1.join()
t2.join()
t3.join()
t4.join()
t5.join()
t6.join()
t7.join()
t8.join()
t9.join()
t10.join()
end_time = time.time()
print(end_time-start_time)
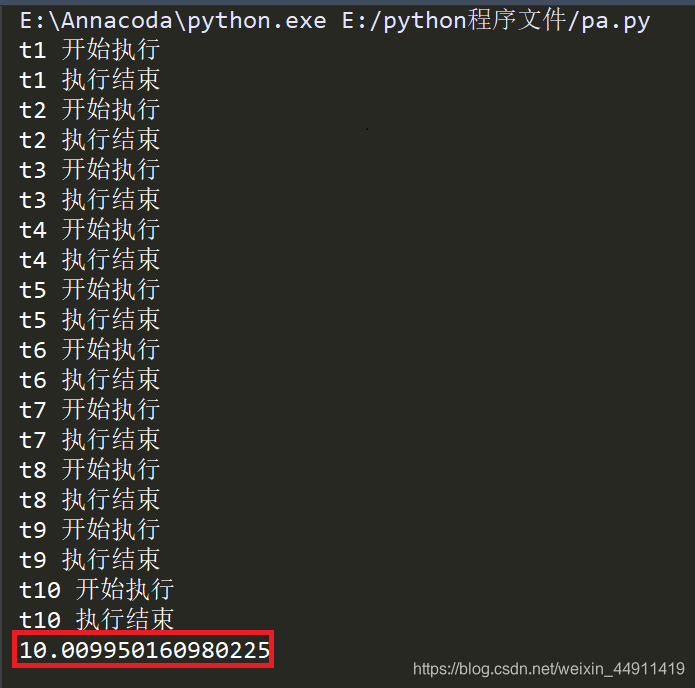
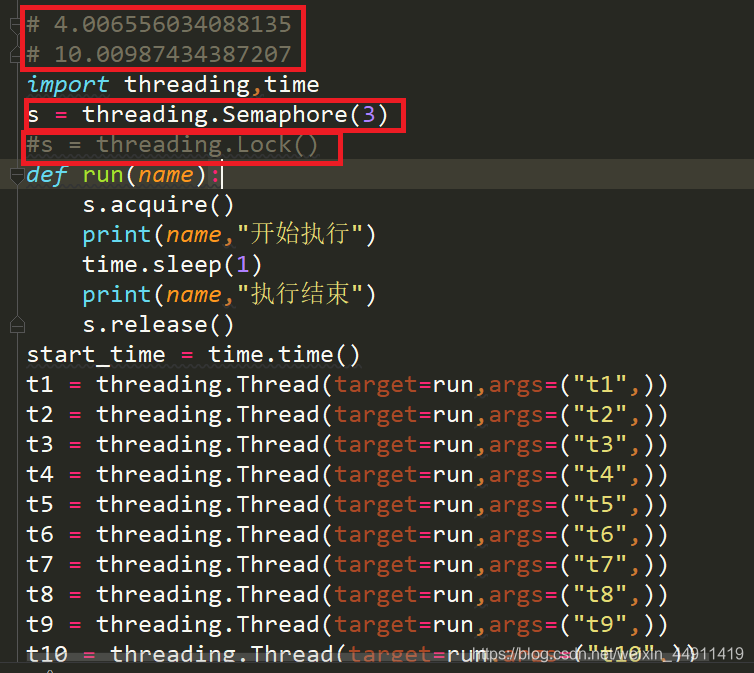
下面是不带信号量一个一个主线程运行,等十个主线程全部执行完所用的时间:
import threading,time
s = threading.Semaphore(3) # 用信号量,不用互斥锁的话
#s = threading.Lock()
def run(name):
s.acquire()
print(name,"开始执行")
time.sleep(1)
print(name,"执行结束")
s.release()
start_time = time.time()
t1 = threading.Thread(target=run,args=("t1",))
t2 = threading.Thread(target=run,args=("t2",))
t3 = threading.Thread(target=run,args=("t3",))
t4 = threading.Thread(target=run,args=("t4",))
t5 = threading.Thread(target=run,args=("t5",))
t6 = threading.Thread(target=run,args=("t6",))
t7 = threading.Thread(target=run,args=("t7",))
t8 = threading.Thread(target=run,args=("t8",))
t9 = threading.Thread(target=run,args=("t9",))
t10 = threading.Thread(target=run,args=("t10",))
t1.start()
t2.start()
t3.start()
t4.start()
t5.start()
t6.start()
t7.start()
t8.start()
t9.start()
t10.start()
t1.join()
t2.join()
t3.join()
t4.join()
t5.join()
t6.join()
t7.join()
t8.join()
t9.join()
t10.join()
end_time = time.time()
print(end_time-start_time)
这里是加了信号量的,三个线程同步执行,全部执行完所用时长就少了很多。
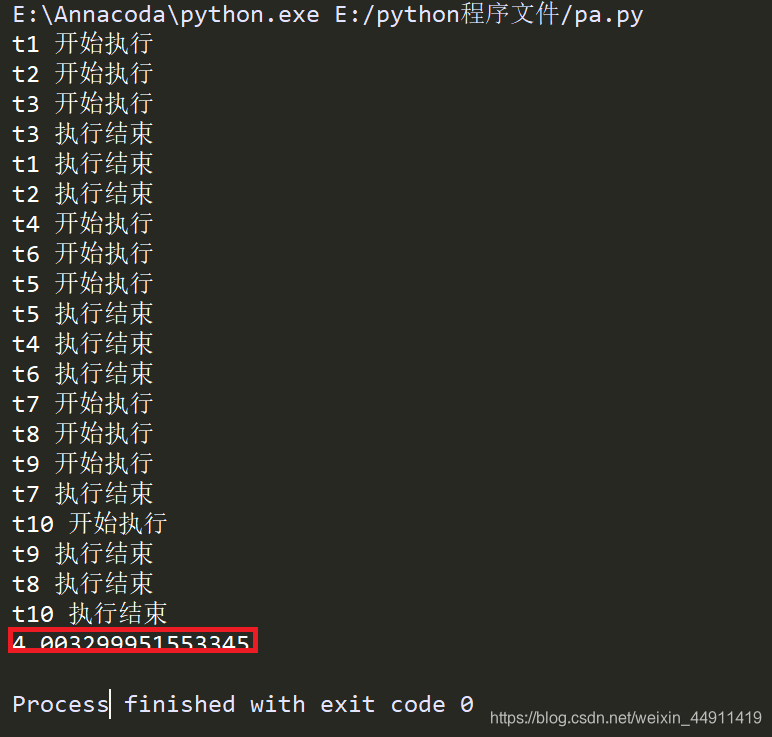
一个加信号量一个不加信号量,所用全部执行时长的区别:
from threading import Thread, Semaphore, currentThread # 导入:threading是包;Thread 和 Semaphore 是类。用前面那个包可以调出后面那两个类,所以其实后面的两个类可以不写的,没有意义
import time
smph = Semaphore(5) #创建一个信号量对象,同时允许5个线程
def do_task():
smph.acquire()
print('\033[45m%s\033[0m 获得了权限' % currentThread().name)
time.sleep(2)
print('\033[46m%s\033[0m 放弃了权限' % currentThread().name)
smph.release()
if __name__ == '__main__':
for i in range(10):
t = Thread(target=do_task, )
t.start()
代码讲解
信号量Semaphore本质也是一把锁,但是这把锁可以限定允许多个任务同时执行任务,
但是不能超出规定的限制,下面的代码参数5就代表可以执行5个任务,如果第6个任务要执行,
必须等5个任务中的一个结束,然后第六个才能进入执行。
smph = Semaphore(5)
这有点像进程池,只不过进程池规定了进程数量,多个任务进入进程池只能有数量一定的进程进行处理。
,但是Semaphore可以产生多个线程。
-----------------------------------------定时器---------------------------
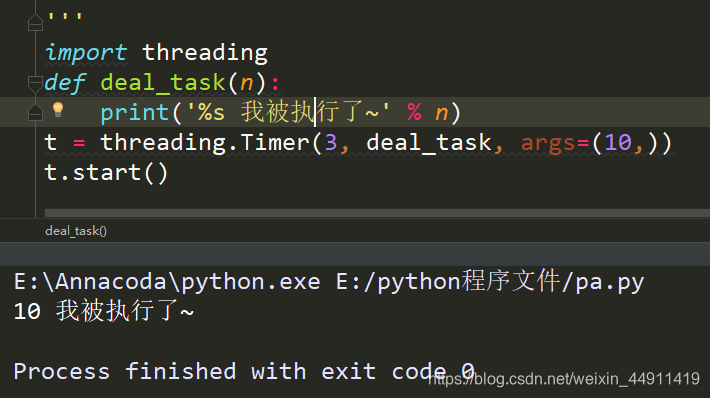
代码演示
from threading import Timer
def deal_task(n):
print('%s 我被执行了~' % n)
t = Timer(3, deal_task, args=(10,)) # Timer表示定时器类型,3 表示定时3秒,3秒之后执行函数deal_task()
t.start()
代码讲解
注意传参时必须是元组形式
import threading
def deal_task(n):
print('%s 我被执行了~' % n)
t = threading.Timer(3, deal_task, args=(10,))
t.start()
定时 挺3秒后,执行上面的 deal_task()函数,打印出这句话:“我被执行了~”
定时器 也是一种线程 但是它可以定时执行
----------------------------------------Event-------------------------------------
from threading import Thread, Event, currentThread
import time
e = Event() # 定义 Event 对象
def traffic_lights():
time.sleep(5)
e.set() # 一旦到了这条语句执行,就会通知下面的wait(),你们不要再等了,往下走吧
def cars():
print('\033[45m%s\033[0m is waiting' % currentThread().name)
e.wait() # 可以把线程从 运行状态 变成 挂起状态,十台车跑跑跑,跑到wait这里全部停下,线程只要运行到这就挂起
print('\033[45m%s\033[0m is running' % currentThread().name)
if __name__ == '__main__':
for i in range(10): # 循环十次,相当于创建十台车
t = Thread(target=cars, ) # 主线程里创建子线程,cars是类
t.start() # 创建十台车,这十台车全start
traffic_lights = Thread(target=traffic_lights, ) # 这是红绿灯的线程,这个线程运行起来就会运行traffic_lights
traffic_lights.start()
代码讲解
首先创建10个线程代表10辆车正在等信号灯,创建1个线程代表信号灯,
当10辆汽车被创建后就等着信号灯发信号起跑,当遇到e.wait()时程序被挂起,
等待信号灯变绿,而e.set()就是来改变这个状态让信号灯变绿,
当e.set被设置后cars等到了信号,就可以继续往后跑了,代码可以继续执行了。
e.set()默认False,e.set()调用后值变为True,e.wait()接收到后程序由挂起变为可执行。
应用场景
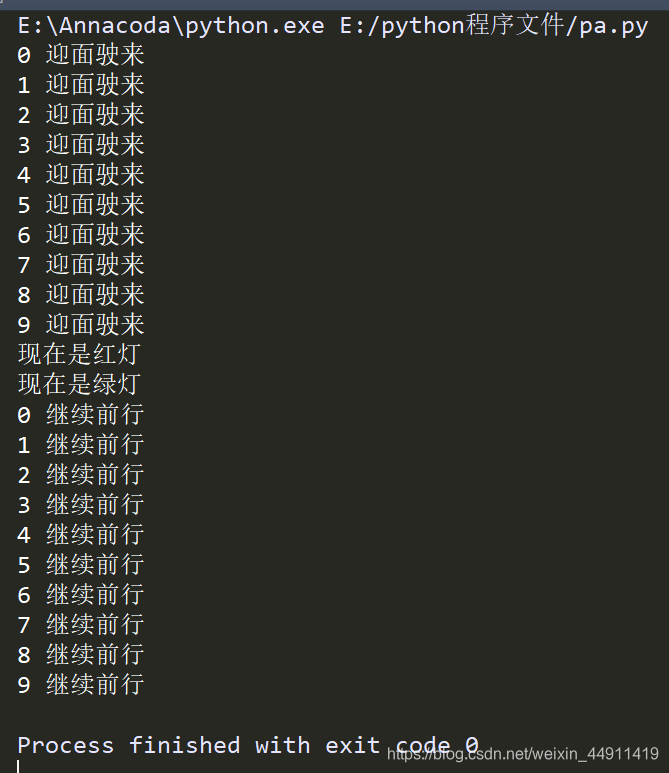
1.
import threading,time
e = threading.Event()
def hld():
print("现在是红灯")
time.sleep(5) # 红灯! 卡 5 秒钟,等一等
e.set()
print("现在是绿灯")
def car_run(name):
print(name,"迎面驶来")
e.wait()
print(name,"继续前行")
for i in range(10):
t = threading.Thread(target=car_run,args=(i,))
t.start()
h = threading.Thread(target=hld,)
h.start()
2.
import threading,time
e = threading.Event() #创建 Event 对象
def hld(): # 红绿灯
#print("现在是红灯")
time.sleep(5) # 休眠5秒
e.set()
#print("现在是绿灯")
def car_run(name):
#print(name,"迎面驶来")
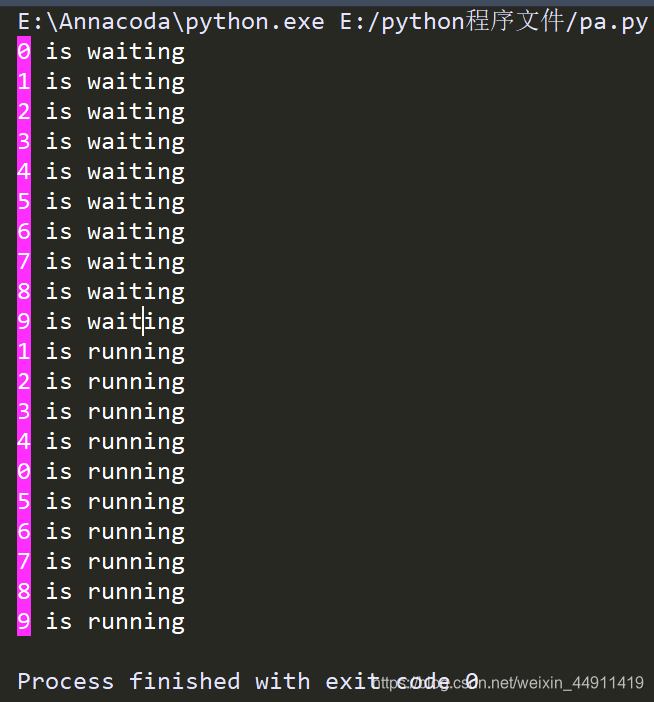
print('\033[45m%s\033[0m is waiting' % name) # 这一条 可以打印出 颜色,可以看下面图片
e.wait()
#print(name,"继续前行")
print('\033[45m%s\033[0m is running' % name)
for i in range(10): # 循环十次
t = threading.Thread(target=car_run,args=(i,))
t.start()
h = threading.Thread(target=hld,)
h.start()
代码演示
from threading import Thread, Event, currentThread
import time
e = Event()
def check_sql():
print('%s is checking mySQL' % currentThread().name)
time.sleep(5)
e.set()
def link_sql():
count = 1
while not e.is_set():#e.isSet是一个绑定方法,自带布尔值为True,e.is_set()默认值为False
e.wait(timeout=1)
print('%s is trying %s' % (currentThread().name, count))
if count > 3:
raise ConnectionError('连接超时')
count += 1
print('%s is connecting' % currentThread().name)
if __name__ == '__main__':
t_check = Thread(target=check_sql, )
t_check.start()
for i in range(3):
t_link = Thread(target=link_sql, )
t_link.start()
代码讲解
数据库远程连接
e.isSet是一个绑定方法,自带布尔值为True,e.is_set()默认值为False
----------------------------------线程Queue-----------------------
线程Queue
1.队列Queue
代码演示
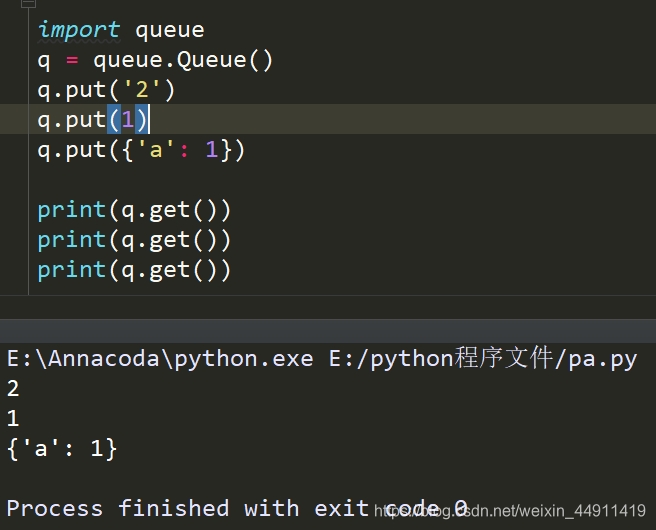
import queue
q = queue.Queue()
q.put('2')
q.put(1)
q.put({'a': 1})
print(q.get())
print(q.get())
print(q.get())
代码讲解
先进先出
可以存放任意类型数据
2.堆栈Queue
代码演示
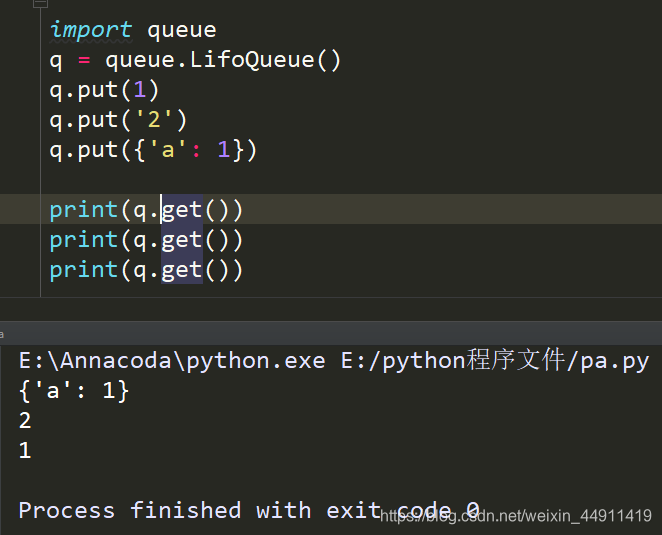
import queue
q = queue.LifoQueue()
q.put(1)
q.put('1')
q.put({'a': 1})
print(q.get())
print(q.get())
print(q.get())
代码讲解
可以存放任意数据类型
Lifo代表后进先出
3.优先级Queue
代码演示
import queue
q = queue.PriorityQueue()
q.put((10, 'Q'))
q.put((30, 'Z'))
q.put((20, 'A'))
print(q.get())
print(q.get())
print(q.get())
打印输出的结果按字典的顺序排,
优先级顺序是字典顺序
优先级队列这个函数里有计算哈希值的方法,哈希值越小,优先级越高
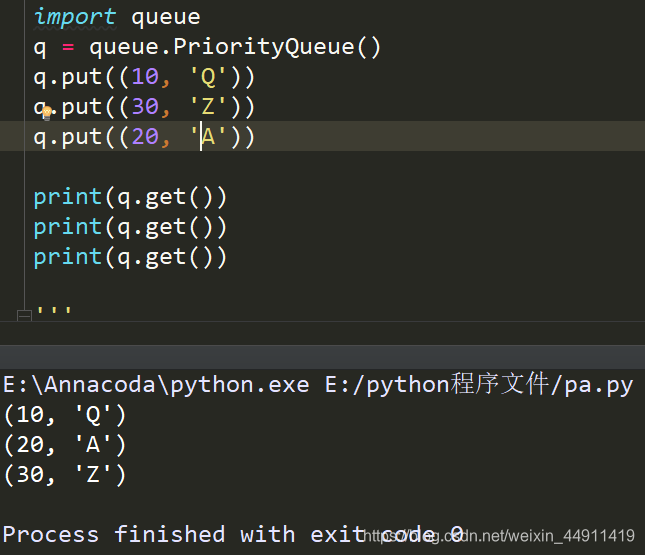
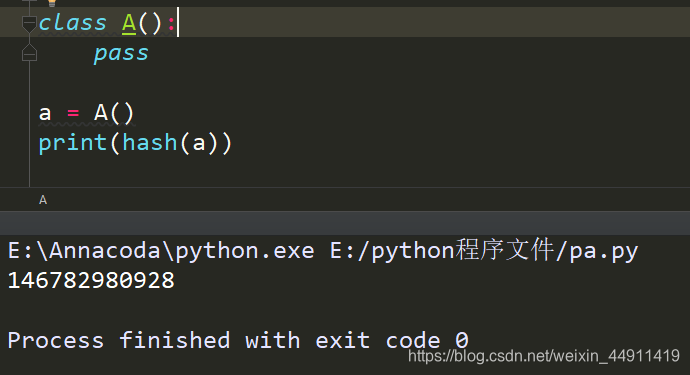
看哈希值怎么看?
class A():
pass
a = A()
print(hash(a))
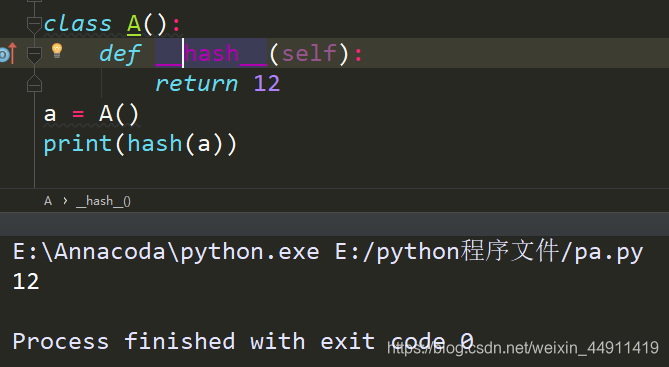
如果你想改变哈希值的话!(比如说,改成12)
class A():
def __hash__(self):
return 12
a = A()
print(hash(a))
**下面告诉你哈希函数怎么写:**
正常 a的哈希值是97,b的哈希值是98)
class A():
def __init__(self,a): # 构造函数里,加一个属性a
self.a = a # 定义了一个属性a
def __hash__(self):
if self.a=="a":
return 10
else:
return 6
a = A("a")
b = A("b")
print(hash(a))
print(hash(b))
# 下面把 a 和 b放在优先级队列里
import queue
q = queue.PriorityQueue()
q.put(hash(a))
q.put(hash(b))
print(q.get())
print(q.get())
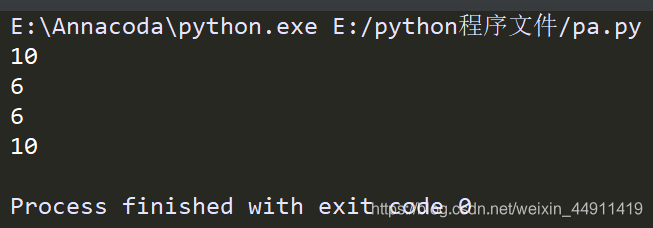
代码讲解
存放的数据是元组类型,带有优先级数字越小优先级越高。
数据优先级高的优先被取出。
用于VIP用户数据优先被取出场景,因为上面两种都要挨个取出。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









