







 本文是Python深度学习(基于PyTorch)的第一部分,详细介绍了Numpy基础,包括从已有数据创建数组、利用random模块生成数组、创建特定形状的多维数组以及使用arange和linspace函数生成数组。接着讲解了PyTorch的基础,如Tensor和Autograd的自动求导原理,以及如何进行非标量反向传播。此外,还提到了PyTorch神经网络工具箱的使用,包括构建神经网络、准备数据、训练模型以及nn和optim模块的运用。最后,讨论了PyTorch的数据处理工具箱,如data和torchvision模块,用于数据加载和预处理。
本文是Python深度学习(基于PyTorch)的第一部分,详细介绍了Numpy基础,包括从已有数据创建数组、利用random模块生成数组、创建特定形状的多维数组以及使用arange和linspace函数生成数组。接着讲解了PyTorch的基础,如Tensor和Autograd的自动求导原理,以及如何进行非标量反向传播。此外,还提到了PyTorch神经网络工具箱的使用,包括构建神经网络、准备数据、训练模型以及nn和optim模块的运用。最后,讨论了PyTorch的数据处理工具箱,如data和torchvision模块,用于数据加载和预处理。
Python深度学习(基于PyTorch)
第一部分 PyTorch基础
一、Numpy 基础
1. 生成numpy数组
1.1.1 生成numpy数组–从已有数据中创建数组
直接对python的基础数据类型(如列表、元组等)进行转换来生成ndarray:
-
将列表转换成ndarray:
import numpy as np lst1 = [3.14,2.17,0,1,2] nd1 = np.array(lst1) print(nd1) print(type(nd1))
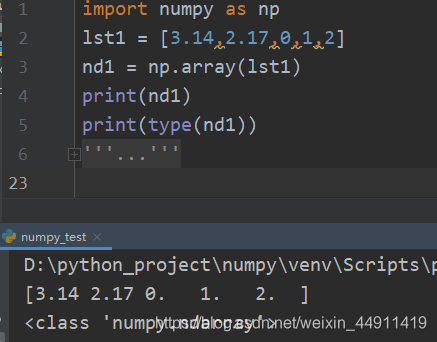
-
嵌套列表可以转换成多维ndarray:
import numpy as np lst2 = ([3.14,2.17,0,1,2],[1,2,3,4,5]) nd2 = np.array(lst2) print(nd2) print(type(nd2))
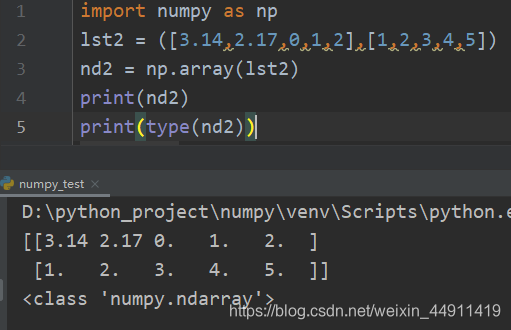
1.1.2 生成numpy数组–利用random模块生成数组
深度学习中经常要对一些参数进行初始化,因此为了更有效的训练模型,提高模型性能,一些初始化还需要满足一定条件,如满足正态分布或均匀分布等。
下面介绍几种常用方法,列举了np.random模块常用函数:
| 函数 | 描述 |
|---|---|
| np.random.random | 生成0到1之间的随机数 |
| np.random.uniform | 生成均匀分布的随机数 |
| np.random.randn | 生成标准正态i的随机数 |
| np.random.randint | 生成随机的整数 |
| np.random.normal | 生成正态分布 |
| np.random.shuffle | 随机打乱顺序 |
| np.random.seed | 设置随机数种子 |
| random_sample | 生成随机浮点数 |
看一下函数的具体使用:
import numpy as np
nd3 = np.random.random([3,3])
print(nd3)
print("nd3的形状为:",nd3.shape)
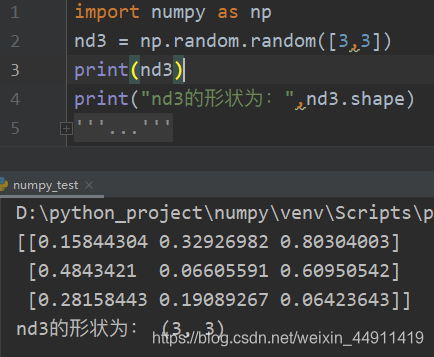
为每次生成同一份数据,可以指定一个随机种子,使用shuffle函数打乱生成的随机数。
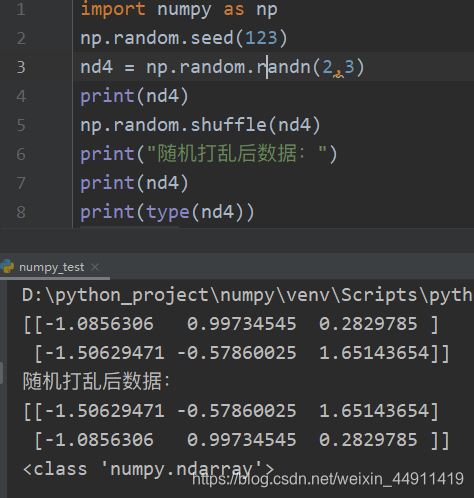
import numpy as np
np.random.seed(123) # 设置随机种子数
nd4 = np.random.randn(2,3) # 生成标准正态的随机数
print(nd4)
np.random.shuffle(nd4) # 随机打乱顺序
print("随机打乱后数据:")
print(nd4)
print(type(nd4))
1.1.3 生成numpy数组 – 创建特定形状的多维数组
参数初始化时,有时需要生成一些特殊矩阵,比如全是0或者1的数组或者矩阵,这时我们可以利用
np.zeros、np.ones、np.diag来实现
| 函数 | 描述 |
|---|---|
| np.zeros((3,4)) | 创建3*4的元素全为0的数组 |
| np.ones((3,4)) | 创建3*4的元素全为1的数组 |
| np.empty((2,3)) | 创建2*3的空数组,空数据中的值并不为0,而是未初始化的垃圾值 |
| np.zeros_like(ndarr) | 以ndarr相同维度创建元素全为0数组 |
| np.ones_like(ndarr) | 以ndarr相同维度创建元素全为1数组 |
| np.empty_like(ndarr) | 以ndarr相同维度创建空数组 |
| np.eye(5) | 该函数用于创建一个5*5的矩阵,对角线为1,其余为0 |
| np.full((3,5),666) | 创建3*5的元素全为666的数组。666为指定值 |
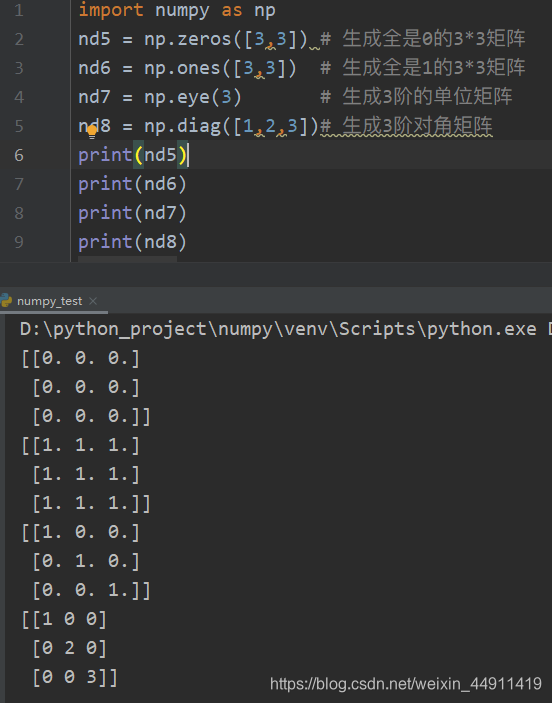
import numpy as np
nd5 = np.zeros([3,3]) # 生成全是0的3*3矩阵
nd6 = np.ones([3,3]) # 生成全是1的3*3矩阵
nd7 = np.eye(3) # 生成3阶的单位矩阵
nd8 = np.diag([1,2,3])# 生成3阶对角矩阵
print(nd5)
print(nd6)
print(nd7)
print(nd8)
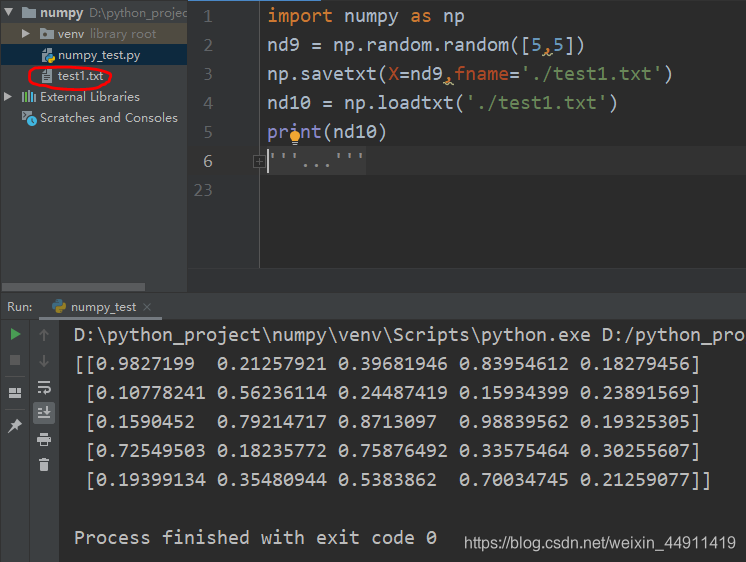
如果需要把生成的数据暂时保存起来,以备后续使用。
import numpy as np
nd9 = np.random.random([5,5])
np.savetxt(X=nd9,fname='./test1.txt')
nd10 = np.loadtxt('./test1.txt')
print(nd10)
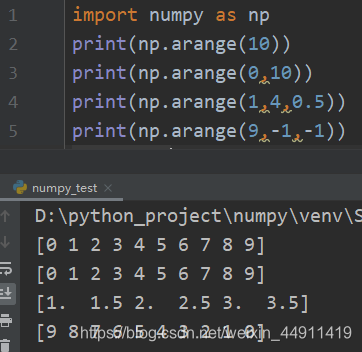
1.1.4 生成numpy数组 – 利用 arange、linspace函数 生成数组
arange 是 numpy模块 中的函数,格式为:
arange([start,] stop[,step,],dtype=None)
start是开始,stop是结束(start、stop用来指定范围),step用来设定步长
import numpy as np
print(np.arange(10))
print(np.arange(0,10))
print(np.arange(1,4,0.5))
print(np.arange(9,-1,-1))
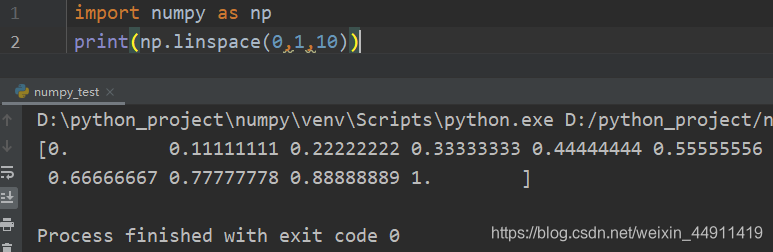
linspace 是 numpy 模块 中的函数,格式为:
np.linspace(start,stop,num=50,endpoint=True,retstep=False,dtype=None)
linspace 可以根据输入的指定数据范围以及等份数量,自动生成一个线性等分向量,其中endpoint(包含终点)默认为True,等份数量num默认为50。如果将 retstep 设置为 True, 则会返回一个带步长的 ndarray。
import numpy as np
print(np.linspace(0,1,10))
二、Pytorch 基础
2.1 Tensor与Autograd(自动求导)
2.1.1 Tensor与Autograd(自动求导)-- 自动求导要点
2.1.2 Tensor与Autograd(自动求导)-- 计算图、
2.1.3 Tensor与Autograd(自动求导)-- 标量反向转播
假设 x, w, b都是标量, z=wx+b, 对标量z调用 backward() 方法, 我们无须对 backward() 传入参数。以下是自动求导的主要步骤:
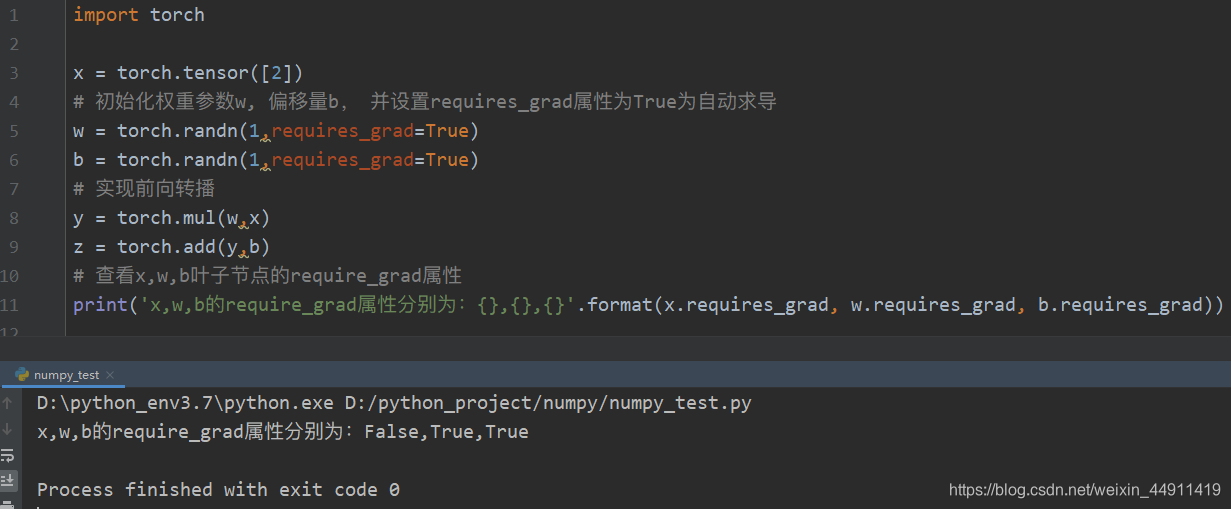
1. 定义叶子节点及算子节点:
import torch
x = torch.tensor([2])
# 初始化权重参数w, 偏移量b, 并设置requires_grad属性为True为自动求导
w = torch.randn(1,requires_grad=True)
b = torch.randn(1,requires_grad=True)
# 实现前向转播
y = torch.mul(w,x)
z = torch.add(y,b)
# 查看x,w,b叶子节点的 require_grad属性
print('x,w,b的require_grad属性分别为:{},{},{}'.format(x.requires_grad, w.requires_grad, b.requires_grad))
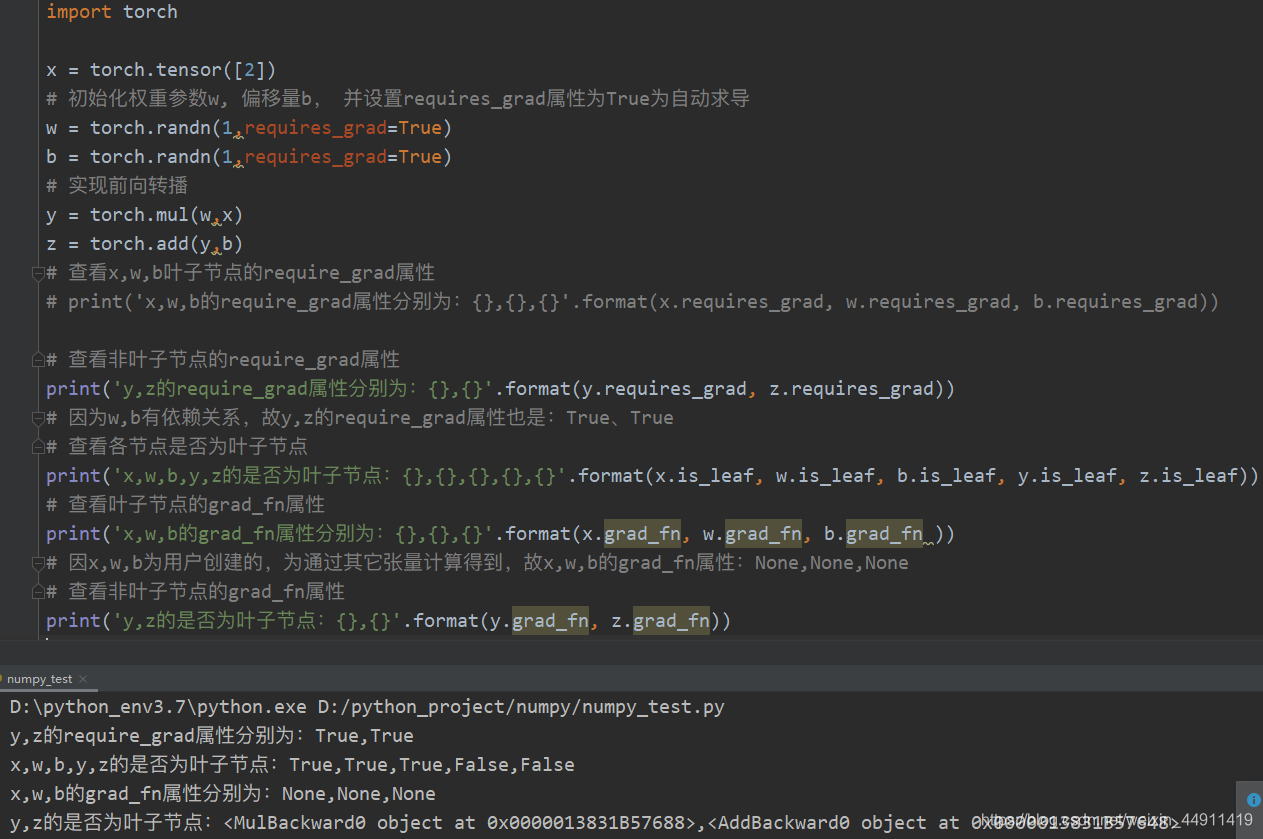
2. 查看叶子节点、非叶子节点的其他属性
# 查看非叶子节点的require_grad属性
print('y,z的require_grad属性分别为:{},{}'.format(y.requires_grad, z.requires_grad))
# 因为w,b有依赖关系,故y,z的require_grad属性也是:True、True
# 查看各节点是否为叶子节点
print('x,w,b,y,z的是否为叶子节点:{},{},{},{},{}'.format(x.is_leaf, w.is_leaf, b.is_leaf, y.is_leaf, z.is_leaf))
# 查看叶子节点的grad_fn属性
print('x,w,b的grad_fn属性分别为:{},{},{}'.format(x.grad_fn, w.grad_fn, b.grad_fn ))
# 因x,w,b为用户创建的,为通过其它张量计算得到,故x,w,b的grad_fn属性:None,None,None
# 查看非叶子节点的grad_fn属性
print('y,z的是否为叶子节点:{},{}'.format(y.grad_fn, z.grad_fn))
3. 自动求导&#x
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1689
1689

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









