






摘要:本文整理自阿里云实时数仓 Hologres 负责人姜伟华老师在 Flink Forward Asia 2024 行业解决方案(二)专场中的分享。主要分为以下三个方面:
-
实时数仓的发展历程
-
从实时数仓到实时湖仓
-
总结
Tips:关注「公众号」回复 FFA 2024 查看会后资料~
01
实时数仓的发展历程
以一个典型客户案例来回顾实时数仓的发展历程。
1.1 第一代实时数仓:Lambda 架构,离线实时分别计算
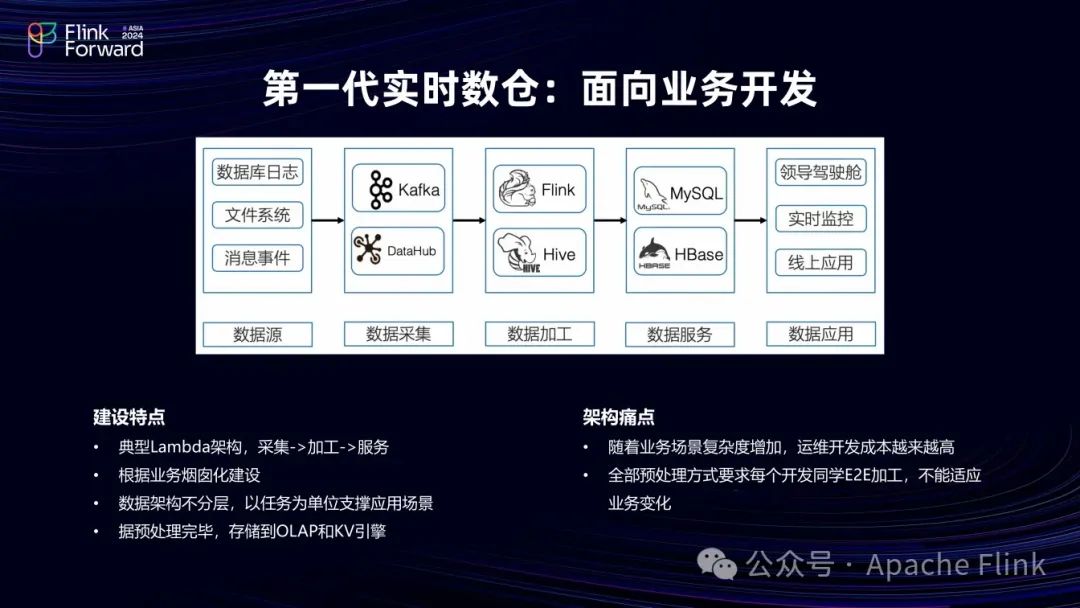
自大数据出现之始,实时数仓采用的就是 Lambda 架构,实时和离线两条链路完全独立。离线链路中,数据写入 Hive 或 MaxCompute 等类似的离线数仓,进行T + 1加工;实时链路中,数据则先写入 Kafka,由 Flink 消费加工后,将最终结果(如 DWS 层或 ADS 层)写入 KV 存储(如 MySQL、HBase 或 Redis)对外提供服务。两条链路的连接点在于离线链路会在第二天修正实时结果数据,以确保最终数据的准确性。
但这种架构存在诸多问题。其一,数据和计算双源头,由两个引擎完成计算;其二,逻辑难以对齐,导致计算和数据重复。离线链路一般存在 ODS 层、DWD 层、DWS 层的分工,因此,离线数据复用较为简单;而在实时链路上,端到端的数据计算,会形成烟囱式架构,运维难度和成本极高。
1.2 第二代实时数仓:Kafka 实时数仓分层+OLAP
在第一代实时数仓的基础上,该客户研发了第二代实时数仓。
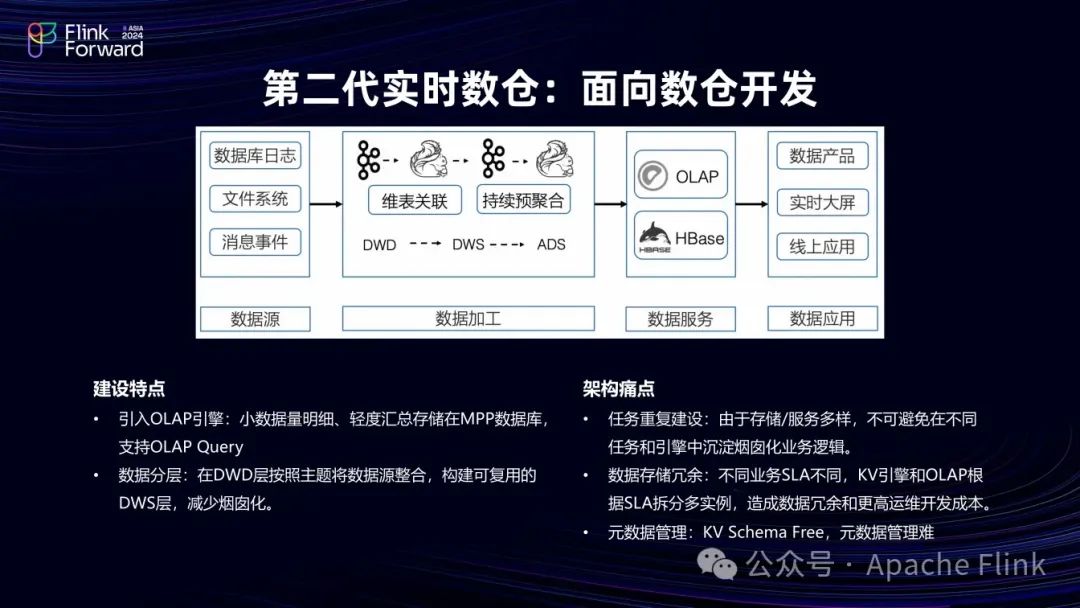
该架构离线链路部分保持不变,实时链路部分尝试构建 DWD 层、DWS层和 ADS 层的分工,通过分层建立复用机制,实现秒级或分钟级的实时数据。典型做法是使用 Kafka 作为中间层,每层由 Flink 消费 Kafka,并写入下一级 Kafka ,实现一定程度的实时复用。
但在实际应用中发现,Kafka 用于实时复用非常困难,且效果有限。因其本质是因为Kafka消费设计,数据不可查、不可订正,这使得架构的复用性较差。但该架构也有创新点,即在最下层引入 OLAP 引擎(如 Hologres),提供了除 KV 查询之外更复杂的查询能力,业务可灵活查询,减少了预计算 KV 的情况,且在数据出现问题时可方便反查每一层。
1.3 第三代实时数仓:Hologres 实时数仓分层复用+分析服务一体
针对使用 Kafka 导致的数据中间层复用困难的问题,该客户与Hologres 合作完成了第三代实时数仓的架构设计。
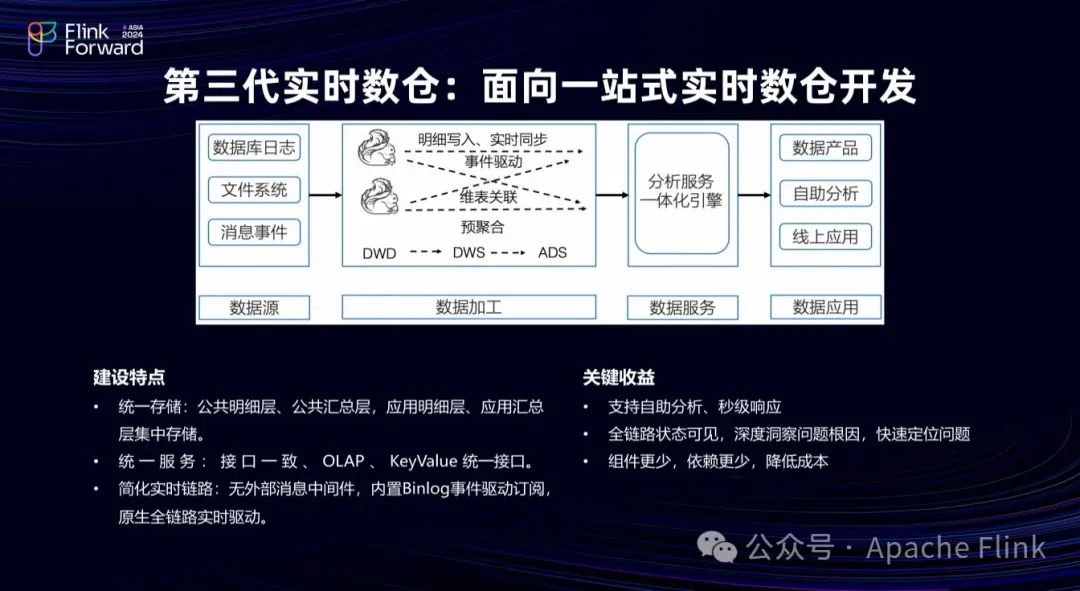
第三代实时数仓将 Kafka 替换为 Hologres 存储引擎,在列存的基础上提供 Binlog,数据的任何写入都会产生 Binlog ,驱动下游 Flink 任务计算,把每一层(DWD 层、DWS 层和 ADS 层)的数据统一存储在 Hologres 中,中间由 Flink 加工,实现了统一存储和服务,便于查询和修改业务数据。
基于此,形成了实时数仓三明治架构:
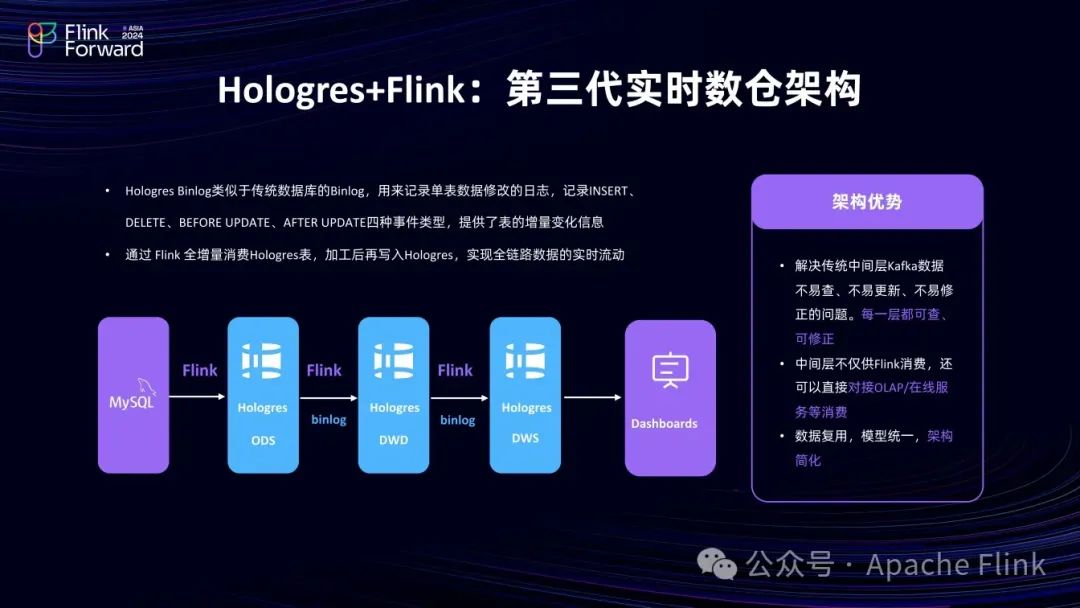
上游数据经 Flink 加工后写入 Hologres 形成 ODS 层,Hologres 的 Binlog 驱动下游 Flink 任务计算,依次生成 DWD 层、DWS 层数据,形成秒级响应的端到端链路,数据实时流动且分层,解决了 Lambda 架构实时数据加工分层和实时离线一致化的问题。
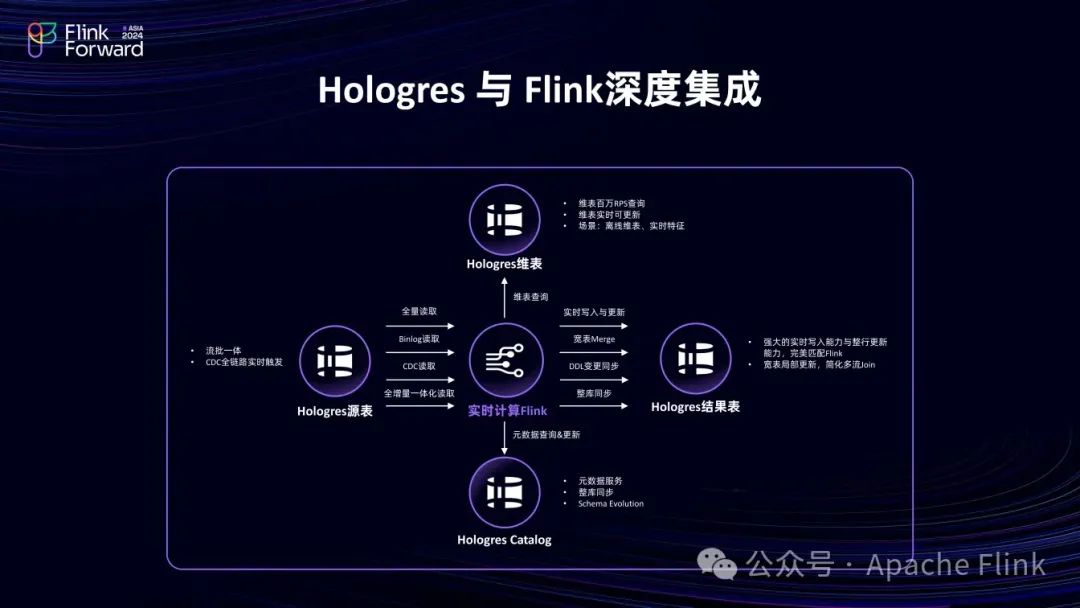
在这个过程中, Hologres 与Flink 进行了深度集成。Hologres 可作为 Flink 的维表,提供每秒百万级的查询能力;也可作为结果表,支持实时写入且写入即可见,具备高性能的写入和更新能力;还能作为 Flink 的上游,支持 Flink 读取全量数据和消费 Binlog 以获取增量数据;并且对接了 Flink 的 Catalog ,使用更加便捷。
1.4 未来架构演进思考:从实时数仓到实时湖仓
在数仓领域,Flink + Hologres 方案表现出了不错的性能和优势,但在新兴的湖仓场景下,我们需要进一步思考如何实现更好的效果。

湖仓场景下,首要解决的是实时与离线如何更好结合的问题。Flink + Hologres 仅解决了 Lambda 架构的实时链路数据分层加工的问题,要将实时链路与离线链路结合,理想状态是 Lambda 架构的实时和离线链路访问同一份数据,即统一存储,且用户使用相同的 SQL 表达业务逻辑,实现统一计算,否则 Lambda 架构的不一致问题将始终存在。这就需要灵活的引擎,既能支持批处理,又能支持流处理和增量处理,同时具备高性能、生命周期管理、存储语义等特性,以实现统一存储和计算,达到实时互通的效果。于是近两年通过 Hologres + Flink + Paimon 的组合我们逐渐实现了这一目标。
02
从实时数仓到实时湖仓
2.1 湖仓统一元数据管理
在湖仓架构中,数据存储在湖上,首先要考虑如何方便访问湖的元数据。Hologres 在 3.0 版本中引入了 External Database 概念。Hologres 是一个 PostgreSQL 生态的数仓产品。Hologres 3.0扩展了 PostgreSQL 的 database 概念,引入 External Database 。External database 对于用户和BI工具来说,就是一个普通的 PostgreSQL database。但其实这个external database 可以映射到数据湖上的一个Catalog(如Paimon Catalog)。这样,用户使用兼容 PG 的 BI 工具连接该 Database 时,无需导入元数据,即可查看湖上的 Schema 和 Table。
同时,也支持把阿里云 MaxCompute 离线数仓的 project 映射成External Database。换言之,用户使用 PG 的 BI 工具来连接External Database 即可访问 MaxCompute 数据湖上所有元数据的表,乃至建表和查询。
2.2 湖仓高性能查询
实时数仓大部分是内表,查询性能非常高。但是要基于湖仓架构对外提供服务,则要考虑如何在数据湖上提供高性能查询的问题。
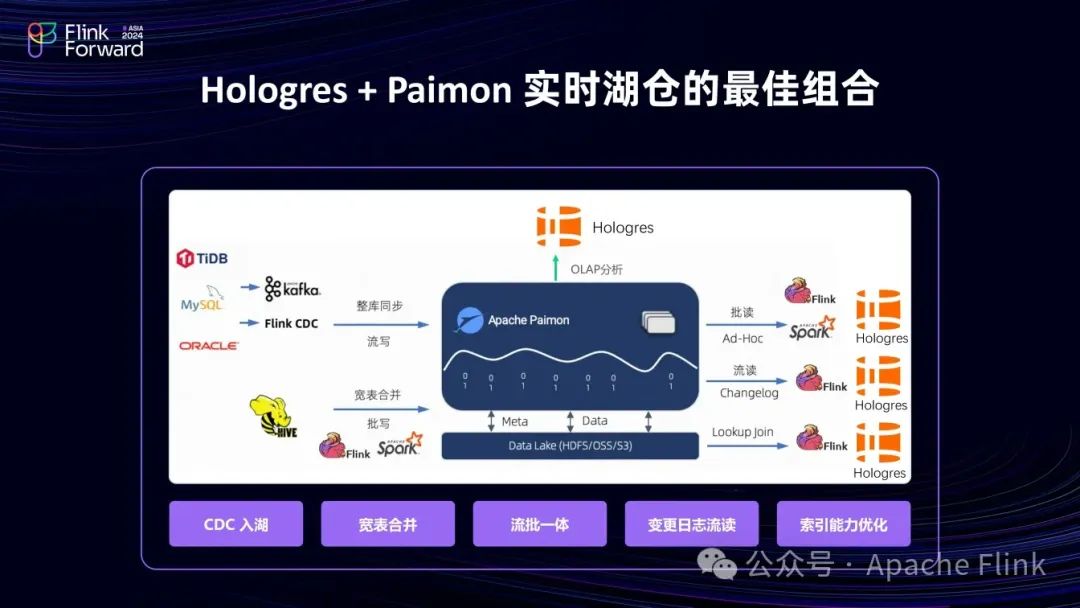
对于湖上数据的高性能查询,Hologres 提供了良好的查询能力,尤其针对 Paimon、MySQL 等表。
2.2.1 Hologres + Paimon 核心特性
Paimon 作为阿里主推的开源湖格式,和 Hologres 结合具有诸多优势。

Hologres 3.0 重点支持了 Paimon 的增删查改元数据能力、Deletion Vector以及查询性能加速,并且是唯一支持 Paimon Changelog 的 OLAP 产品。Paimon Changelog 类似于 Binlog ,可以体现 Paimon 的两个 snapshot 之间的 delta ,可利用此构建增量和流式加工能力,实现流批一体或 Lambda 架构的统一计算。Hologres 3.0的 dynamic table 支持增量消费 Paimon Changelog。同时Hologres 3.0也支持写入 Paimon表。
2.2.2 性能对比:Hologres + Paimon 与 Trino + Paimon
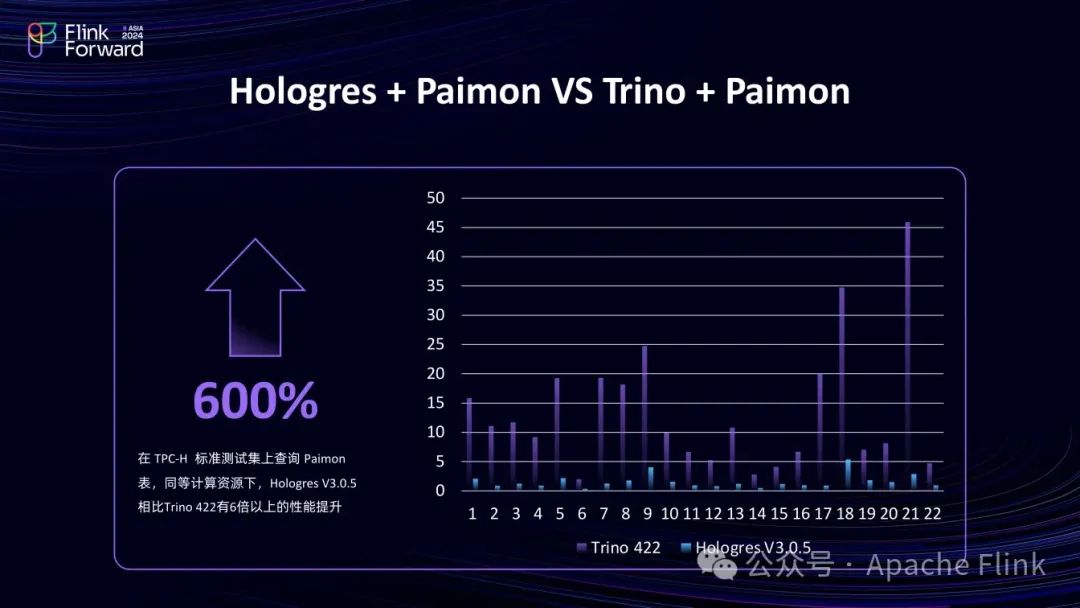
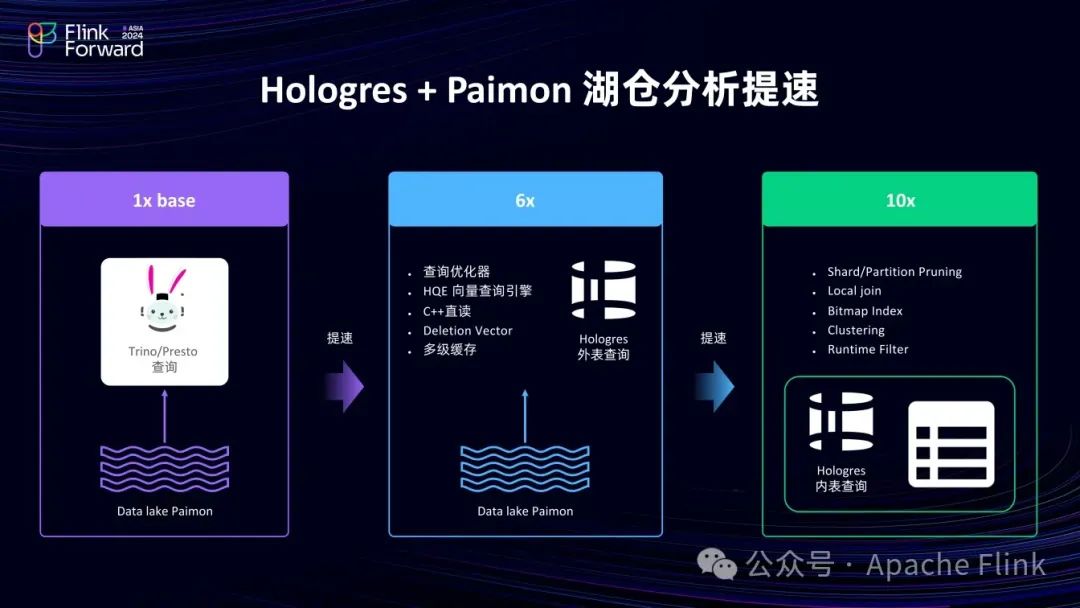
若只查 Paimon 数据湖,Hologres 3.0 性能约为 Trino 的 6倍,若将数据导入 Hologres 内表,利用其更多的索引,性能可提升至约 10 倍,用户可根据业务需求选择。若注重数据共享,直查数据湖较好;若是 DWS 层或 ADS 层,更关注性能,则导入内表更佳。
2.3 实时湖仓分层架构
2.3.1 Hologres Dynamic Table
■ 功能概述
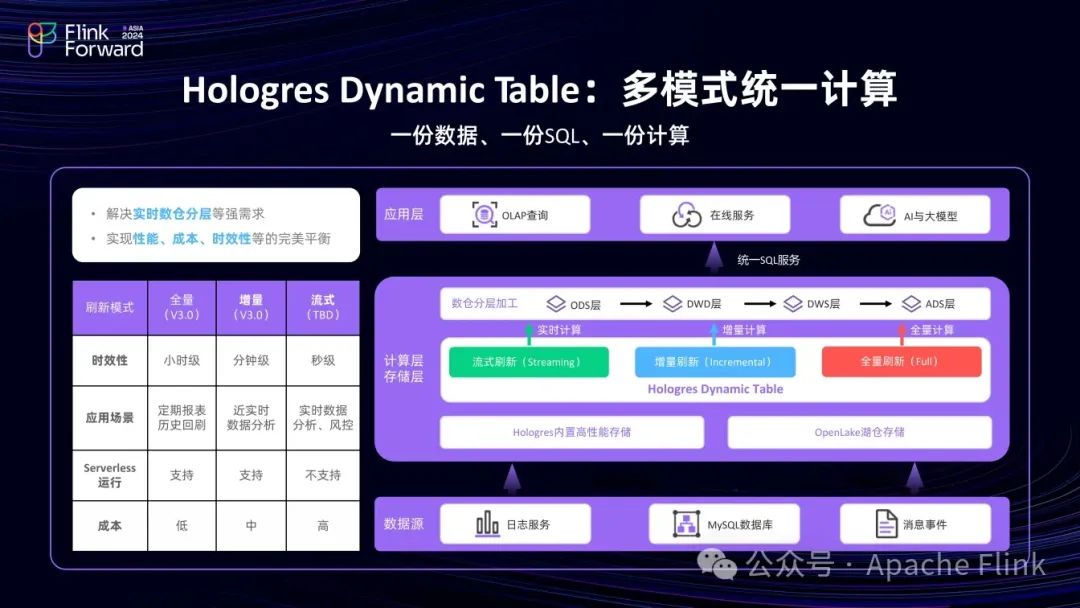
Hologres 3.0 发布的 Dynamic Table 功能实现了多模式统一计算,支持批、流和增量三种计算模式一体。无论何种计算模式,用户数据可保持一份,无论是湖上的 Paimon 表或是 Hologres 内表,通过同一份SQL表达业务逻辑,实现多种模式统一。
在 3.0 版本中,推出了全量和增量两种计算模式,流式计算内部已有版本,公有云发布时间待定。全量计算也可看作离线计算,时效性可达天级或小时级,适用于定期报表;增量计算时效性为分钟级,适用于定时分析;流式计算时效性为秒级,适用于实时风控和监测等场景。
从成本角度看,全量计算调度频率低,也无需状态,实现业务逻辑成本相对较低,但较长时间的全量计算成本较高;增量适中;流式要预先占用资源,成本最高。通过三种模式,可根据时效性和成本要求对湖表或内表进行实时数仓分层,实现流批一致化计算。
■ 技术原理
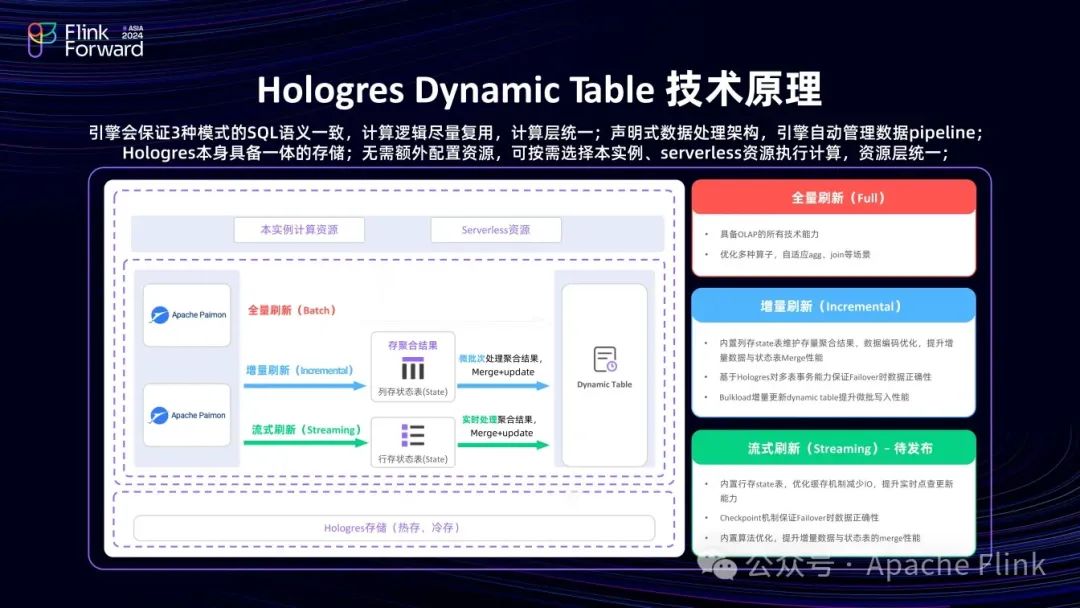
关于全量计算(离线)的研究非常成熟;流是一种利用状态实现数据快速计算的计算方式;增量也利用了状态,但其状态与流的状态略有不同,流的状态是依次进入的,整体上为延迟考虑。而增量更多考虑吞吐,将数据切成若干个批,每次基于上一批的结果状态,处理一个批,并更新状态。这样就实现了近实时的高性能增量计算。综上,增量模式使用列存状态表,流式模式使用行存状态表。
■ 使用方式

Dynamic Table 在语法上非常接近于标准 SQL 中的 create table as select (CTAS)。CTAS是一次性的 SQL,执行完便不再执行该 SQL ,而是直接把结果写到一张表。Dynamic Table在 CTAS上加了一个 Dynamic 字样,即该计算被周期性地执行。
在全量刷新模式下,调度周期可以是每天或者每小时。在增量刷新模式下,由于增量一般要求分钟级的延时,因此,刷新周期一般是1-5分钟。
可以看到,对于不同的计算模式,其 SQL 差异是非常小的。业务逻辑部分几乎完全相同。因此,在 Lambda 架构下,表达实时和离线的计算逻辑使用同一个 SQL 。
Dynamic Table 还支持分区级别的自动刷新模式转换。这很好适配了lambda架构的当天分区需要近实时或者实时刷新(增量、流式),而T+1分区用全量刷新的使用模式。这样,用户只需要写一个SQL就可以了,无需为实时和离线写两遍SQL。
■ Serverless降本与隔离
当提及 Dynamic Table 时,有一个无法绕开的问题——资源从哪里来。当我们每天或每小时加工一次,无论是增量或是全量,都需要大量的资源。Hologres 是一个实时数仓,致力于提高资源的使用率,为用户提供最低延迟、最高 QPS 的查询,无论是数仓分层或是数据计算都要消耗很多资源。如果计算直接发生在实例内,它会挤占实例的大量资源,大大降低实例的稳定性,影响刷新的速度。
基于此,Hologres 引入了一个与 Dynamic Table 配套的能力——Serverless Computing。
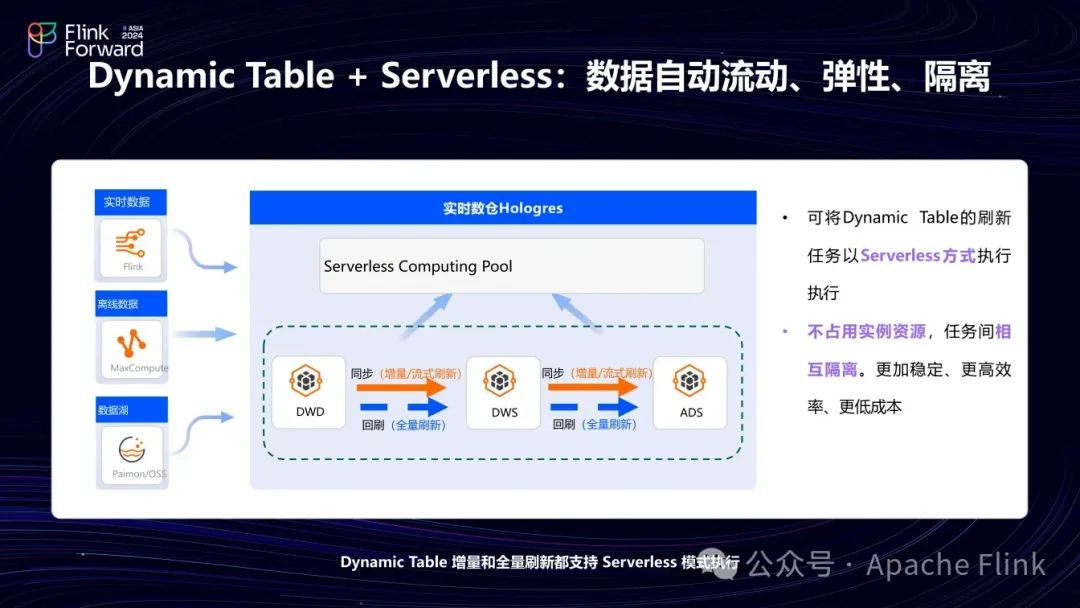
各个云厂商、各个产品使用的 Serverless 的语义不同。对于Hologres来说,Serverless指的是单条 SQL 可以不依赖于实例资源,独立按需分配资源执行。因此,这里的 Serverless 的单位是单条 query 。对于一条 query,只要设一个flag,它会用 Serverless 方式,临时拉起资源执行该 query,执行结束后归还资源,按照使用的资源量收费。
首先,引入 Serverless 消除了对实例的影响;其次,对于Dynamic Table定时调度任务或高并发的大量查询,无需预留资源,根据实际使用资源付费,成本降低。最后,非常重要的一点,优化器会根据 SQL 的特点自动估算需要使用的资源,用户无需再关心资源分配是否合理,保证Query 100% 执行成功。
结合 Serverless 与Dynamic Table,即可在执行定期计算任务时使用Serverless 资源完成,不影响实例的同时,更快更好地执行。
2.3.2 Hologres Dynamic Table+Paimon

要实现实时湖仓,Hologres 基于 Paimon 构建 Dynamic Table 增量式消费 Paimon Changelog ,驱动增量计算进行增量 ETL 的加工,使得 ETL 计算更轻量,时效性更好。
2.3.3 实时湖仓分层应用案例
Dynamic Table 是一个相对较新的功能,今年在淘宝的两个核心业务上线,并经受了618和双11大促的严苛考验。
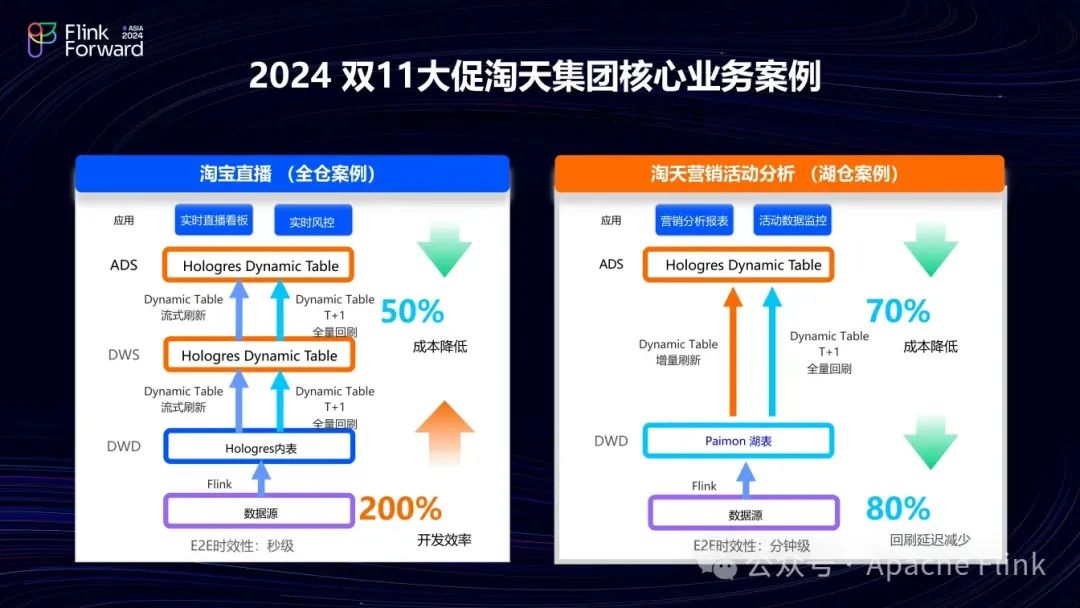
■ 淘宝直播
由于直播对时效性的要求,它是一个全仓的场景,其数据从 ODS 层开始都在 Hologres 中,依次在 DWD、DWS、ADS 层层加工。经 Flink 加工后写入 Hologres 内表,利用 Dynamic Table 的流式刷新能力逐层加工至 DWS 层和 ADS 层,形成实时风控和看板。同时,利用 Dynamic Table的全量回刷功能实现 T + 1 离线回刷,且实时和离线逻辑使用同一 SQL 。这样,即可构建纯实时的数据分层的 Lambda 架构。经评估,成本降低50%,开发效率提升约三倍。
■ 淘天营销活动分析场景
这是一个湖仓场景,对淘天的营销活动进行跟踪分析,时效性要求较低,分钟级足以。
该场景下,数据写入 Paimon 表,通过 Dynamic Table 的增量模式构建 ADS 层,形成分钟级延时的营销活动分析报表。此场景将流式改为增量,统一了链路,成本降至原来的三分之一,回刷延迟降至原来的五分之一。
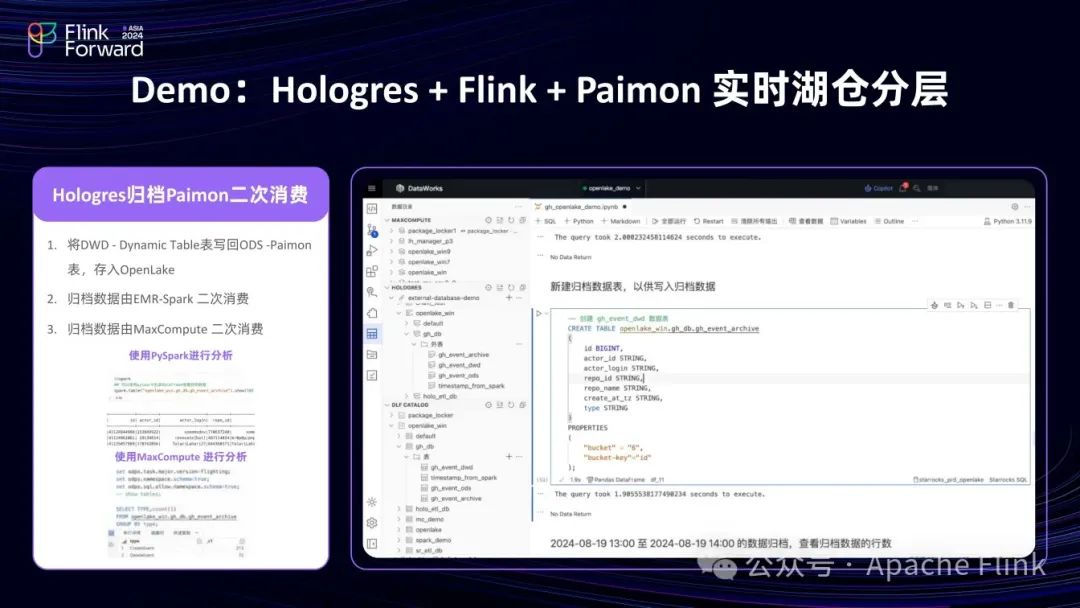
2.3 Demo:Hologres + Flink + Paimon 实时湖仓分层
通过一个简单 Demo 展示基于 Flink + Paimon + Hologres 的湖上加工流程。
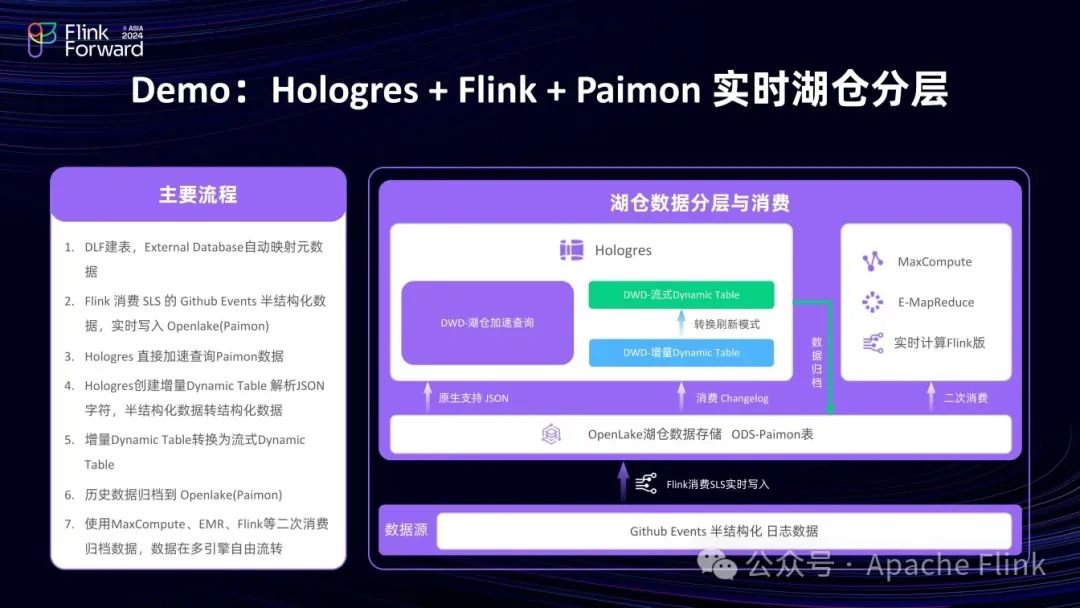
以 GitHub 的 Events 半结构化数据为例:先经 Flink 加工写入湖上的 Paimon 表,然后可直接查询 Paimon 表数据,利用 Dynamic Table 构建数仓分层,还可将数据写回湖上。
具体操作包括:
(1)创建一个 Database 关联湖上元数据,在湖上创建 Paimon 表
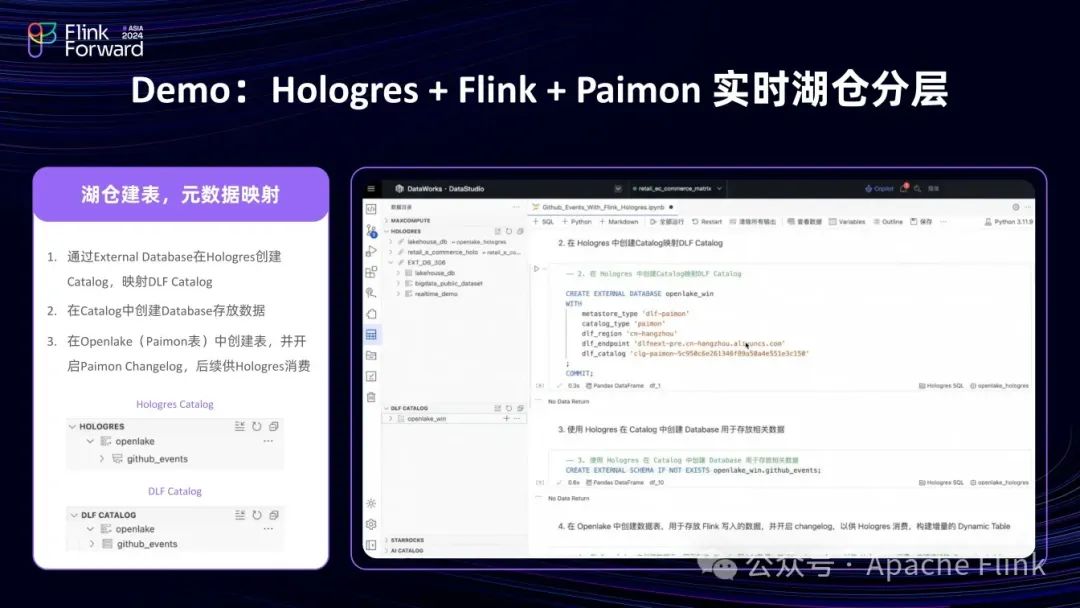
(2)通过 Flink 在表中写入数据
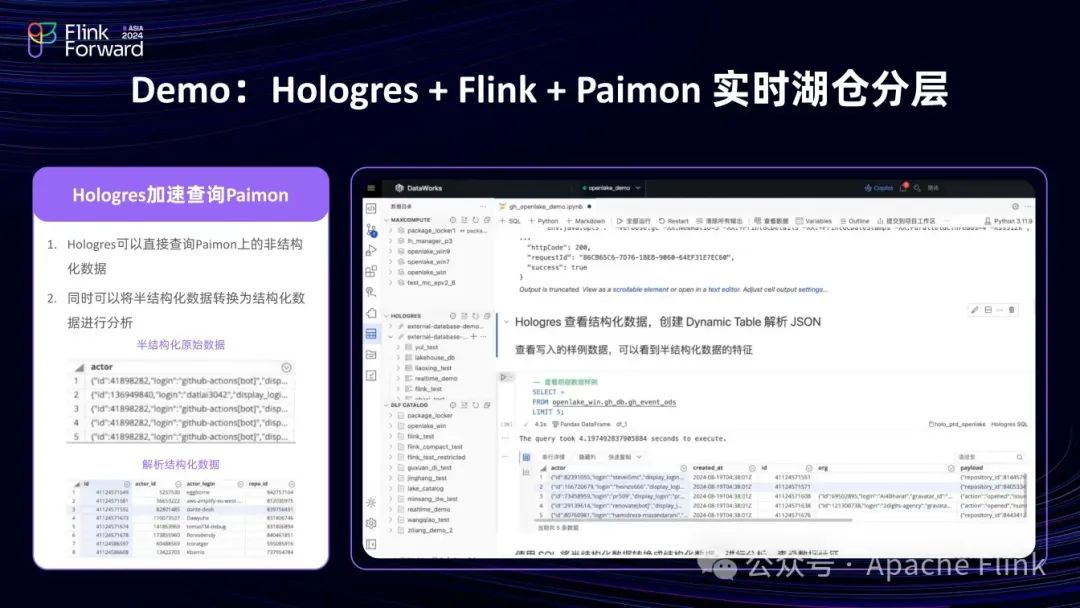
(3)由于该表的数据是 Json 格式,故可以直接查询;若要固化查询到的 SQL,可以抽取 Json 中的数据,写入 Hologres 表中
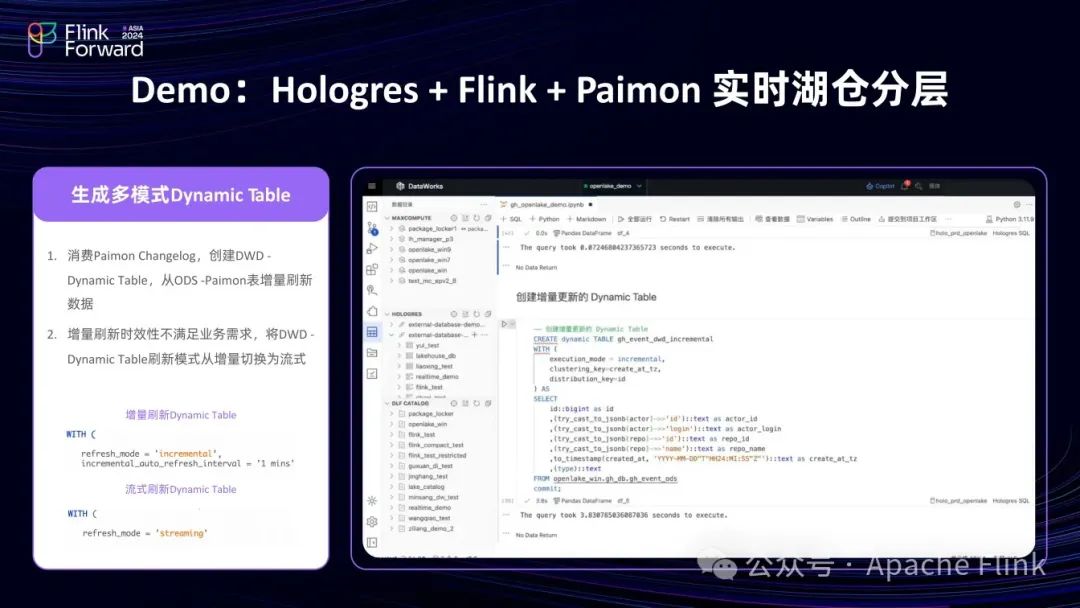
(4)可以在该 SQL 上加一个 Create Dynamic Table 的语法,由于是增量模式,可以把湖中的数据自动抽到仓中,也可以将模式改为流式,抽取会更加及时,可以手动刷新数据。
(5)也可以把数据直接写到湖上,在创建好湖表后,可以在湖表中 insert,把仓中的数据导入湖表;还可以使用 Spark、MaxCompute 等产品查湖表的数据,实现一个数据的多引擎的共享。
03
总结
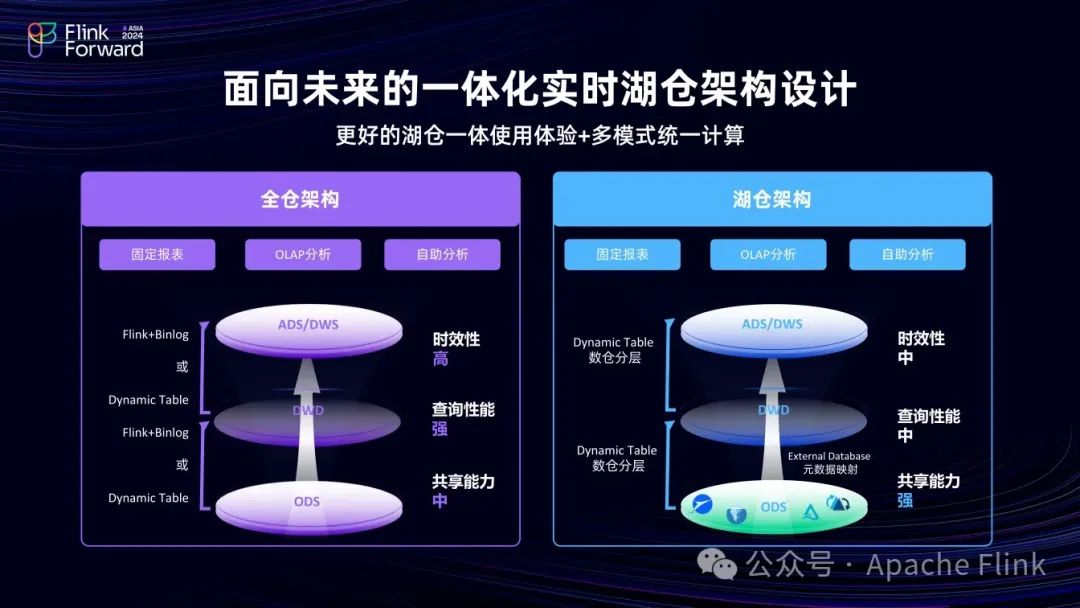
实时数仓阶段, Flink + Hologres 组合实现了Lambda架构下实时链路的数仓分层和复用。在湖仓场景下,随着 Dynamic Table 等能力的增强,用户可根据业务需求选择全仓、湖仓或全湖方案。
若是全仓方案,可以在 Hologres 中加工时使用 Dynamic Table或者Flink引擎来实现流批一体或多模式计算。而随着用户对于数据共享的需求越来越多,用户可以把数仓分层中的较下面的某些层次(比方说ODS或者DWD,这些层更关注共享性和复用)放在湖上,而上层(如 ADS 或 DWS 层,这些层更关注性能)入仓。随着技术的进步,在湖仓一体的时代,用户可以根据自己对业务的诉求,包括成本、性能、延时、共享性等,选择更加合理的方案。

Hologres 作为阿里云的自研实时数仓引擎,在集团内外都有巨大的使用量。目前官网已有 40家以上的客户案例文章,实际客户远大于 40。随着湖仓能力的增强,该产品定位实现了由原本的实时数仓到一体化实时湖仓的转变。用户的数据无论是在仓中还是湖中,都可以通过使用 Hologres 获得良好的使用体验,如果大家对我们产品感兴趣,可以在阿里云官网搜索参与免费试用,谢谢大家。

















 957
957

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









