







这里写目录标题
一、Apache Hive 介绍
- Hive是一款建立在Hadoop之上的开源数据仓库系统。
- Hive可以将存储在Hadoop文件中的结构化、半结构化数据文件映射为一张数据库表,基于表提供了一种类似SQL的查询模型,称为Hive查询语言(HQL),用于访问和分析存储在Hadoop文件中的大型数据集。
- Hive核心是将HQL转换为MapReduce程序,然后将程序提交到Hadoop群集执行。

|

|
二、Apache Hive 架构

1、用户接口
| 接口 | 介绍 |
|---|---|
| CLI | CLI(command line interface)为shell命令行,通过命令行访问。 |
| JDBC/ODBC | Hive中的Thrift服务器允许外部客户端通过网络与Hive进行交互,类似于JDBC或ODBC协议。 |
| WebGUI | WebGUI是通过浏览器访问Hive。 |
2、元数据存储
- 元数据(Metadata),
描述数据的数据,主要是描述数据属性(property)的信息,用来支持如指示存储位置、历史数据、资源查找、文件记录等功能。通常是存储在关系数据库如mysqlorderby中。Hive 中的元数据包括表的名字,表的列和分区及其属性,表的属性否为外部表等,表的数据所在目录等。 - 元数据服务(Metastore),Metastore服务的作用是
管理metadata元数据,对外暴露服务地址,让各种客户端通
过连接metastore服务,由metastore再去连接MySQL数据库来存取元数据。
(1)Hive Metastore 架构图
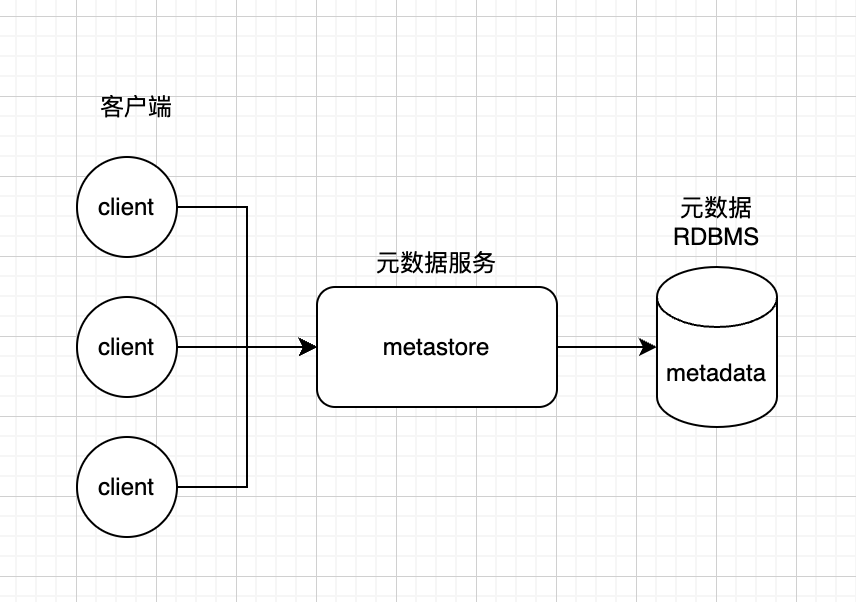
(2)metastore 配置模式
| 模式 | 内嵌模式 | 本地模式 | 远程模式【推荐企业使用】 |
|---|---|---|---|
| Metastore服务是否需要单独配置、单独启动? | 否 | 否 | 是 |
| Metadata存储介质 | Derby | Mysql | Mysql |
3、Driver驱动程序
Driver驱动程序,包括语法解析器、计划编译器、优化器、执行器,完成 HQL 查询语句从词法分析、语法分析、编译、优化以及查询计划的生成。生成的查询计划存储在 HDFS 中,并在随后有执行引擎调用执行。

4、执行引擎
Hive本身并不直接处理数据文件。而是通过执行引擎处理。当下Hive支持MapReduce、Tez、Spark3种执行引擎。


















 934
934

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









