







MoE(Mixture of Experts,混合专家模型)
一、MoE介绍
“Mixture of Experts”(MoE)是一种机器学习模型,特别是在深度学习领域中,它属于集成学习的一种形式。MoE模型由多个专家(experts)和一个门控网络(gating network)组成。每个专家负责处理输入数据的不同部分或不同特征,而门控网络则负责决定每个输入应该由哪个专家来处理。例如,在下图中,“More”这个 token 被发送到第二个专家,而“Parameters”这个 token 被发送到第一个专家。
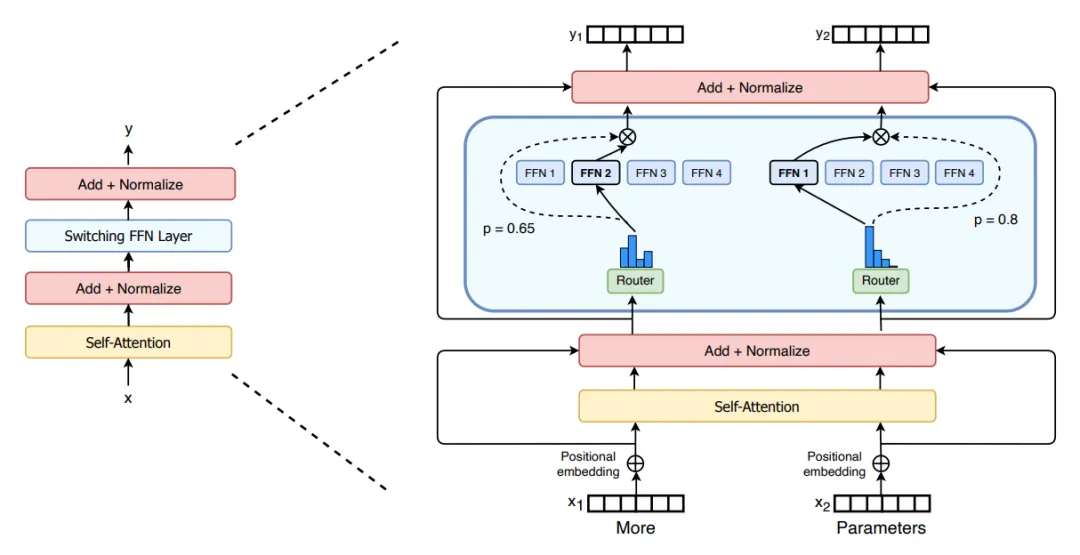
二、MoE出现的背景
本质上来说就是一种高效的 scaling 技术,用较少的 compute 实现更大的模型规模,从而获得更好的性能。
三、有哪些MoE模型
Switch Transformers、Mixtral、GShard、DBRX、Jamba DeepSeekMoE 等等。以Mixtral为例Mixtral 是一个稀疏的专家混合网络。它是一个decoder-only的模型,其中前馈块从一组 8 个不同的参数组中选择。在每一层,对于每个令牌,路由器网络选择其中两个组(“专家”)来处理令牌并附加地组合他们的输出。下图:混合专家层
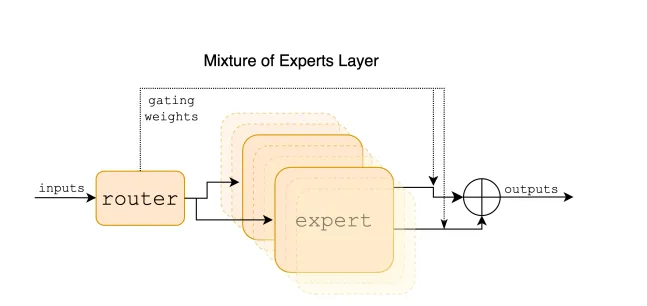
这种技术在控制成本和延迟的同时增加了模型的参数数量,因为模型只使用每个令牌总参数集的一小部分。具体来说,Mixtral 总共有 46.7B 个参数,但每个令牌只使用 12.9B 个参数。因此,它以与 12.9B 型号相同的速度和相同的成本处理输入和生成输出。Mixtral 基于从开放 Web 中提取的数据进行预训练——同时培训专家和路由器。
四、 为什么 MoE 模型是稀疏的?
MoE 模型的稀疏性主要源于以下两个方面:
专家选择: MoE 模型的核心思想是根据输入数据选择合适的专家进行处理。通常情况下,只有少数几个专家会被激活,而其他专家则保持不活跃状态。这种选择机制使得 MoE 模型的参数使用更加高效,避免了所有参数都参与计算。
门控网络: 门控网络负责根据输入数据计算每个专家的激活概率。为了鼓励稀疏性,通常会对门控网络的输出进行一些限制,例如:
引入稀疏正则项: 在训练过程中,通过添加鼓励稀疏性的正则项,例如 L1 正则化,来约束门控网络的输出,使其倾向于选择较少的专家。
使用类似 Gumbel-Softmax 的技巧: 采用一些特殊的采样技巧,例如 Gumbel-Softmax,可以使得门控网络的输出更加稀疏,鼓励模型只选择最相关的专家。
总而言之,MoE 模型通过专家选择和门控网络的设计实现了模型的稀疏性,从而在保持模型表达能力的同时降低了计算成本,并提高了模型的泛化能力。
五、介绍门控网络或路由门控网络
接收输入数据并执行一系列学习的非线性变换。这一过程产生了一组权重,这些权重表示了每个专家对当前输入的贡献程度。通常,这些权重经过softmax等函数的处理,以确保它们相加为1,形成了一个概率分布。这样的分布表示了在给定输入情境下每个专家被激活的概率。一个典型的门控函数通常是一个带有 softmax 函数的简单的网络。
https://github.com/wenet-e2e/wenet/blob/main/wenet/transformer/positionwise_feed_forward.py#L61
"""Positionwise feed forward layer definition."""
class MoEFFNLayer(torch.nn.Module):
"""
Mixt 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 6307
6307

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









