






日常进行数据分析时,如果需要知道每辆车出行的具体日期,那就要用到分组聚合字符串。同时对于轨迹数据来说,需要拆分轨迹,以获得单独的路段。本文使用python和sql分别实现上述过程。
欢迎关注本人公众号--交通数据探索师
python
import pandas as pd
data = pd.DataFrame({'vehicle': ['沪A', '沪A', '沪A', '沪B', '沪B'],
'date': ['20240601', '20240602', '20240603', '20240510', '20240511']})
data = (data.
groupby('vehicle').
agg(date_all=('date', lambda x: ','.join(sorted(x.unique())))).
reset_index())
data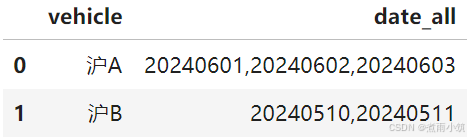
如上图,可以看出沪A在2024年6月1日、2024年6月2日、2024年6月3日均有出行。
clickhouse
select vehicle, arrayStringConcat(arraySort(groupArray(date)),',') as date_all
from table_name
group by vehiclepostgresql
select vehicle, string_agg(distinct date, ',')
from table_name
group by vehicle对于车辆轨迹数据来说,可能所给的数据表中,每个车辆的轨迹是将所经过路段按照顺序拼接起来的字符串,但是我们的操作中需要拆分这个轨迹字符串以获得单独的路段,这个过程相当于上面分组聚合字符串的逆过程。
python
import pandas as pd
data = pd.DataFrame({'vehicle': ['沪A', '沪B'],
'road_id': ['123+456+789', '12+34']})
# 拆分字符串
data['road_id'] = data['road_id'].str.split('+')
data = data.explode('road_id')
data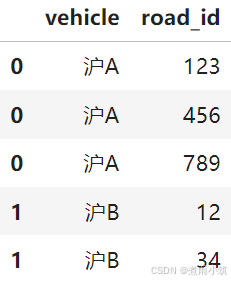
clickhouse
select arrayJoin(splitByChar(road_id, '+')) as road_id ,vehicle
from table_namepostgresql
select regexp_split_to_table(road_id, '+') as road_id, vehicle
from table_name以上就是本文的全部内容了。期待大家的点赞、关注!



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











