






- 列举 Python2 和 Python3 的区别?
(1).print语句变成了print函数
(2).编码格式:python2中unicode是单独的,不是byte类型,python3中支持utf-8字符串,以及字节类
(3).除法:python2中浮点数除法会保留浮点数的小数部分
(4).xrange:python2中常用xrange()创建生成器对象,这个生成器是无穷的。
(5)Python 2.x 中反引号相当于repr函数的作用,Python 3.x 中去掉了这种写法,只允许使用repr函数
(6).数据类型:python3中去掉了长整型
(7).不等运算符:python2中不等有两种 != 和 <>
- 简述 Python 的深浅拷贝以及应用场景?
浅拷贝:copy.copy()
深拷贝:copy.deepcopy()
对于只有一层的数据类型来说,浅拷贝,深拷贝是一样的。eg:字符串,数字,一层的列表,元祖,字典。
对于不止一层的数据类型来说,
浅拷贝:
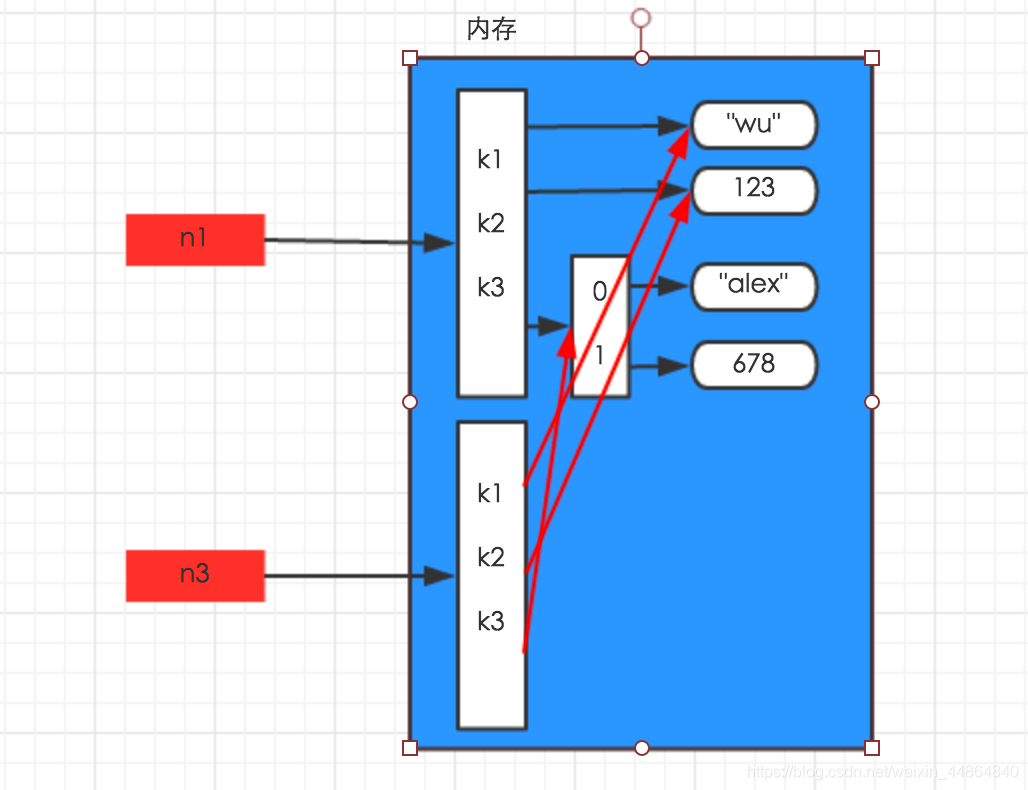
深拷贝:
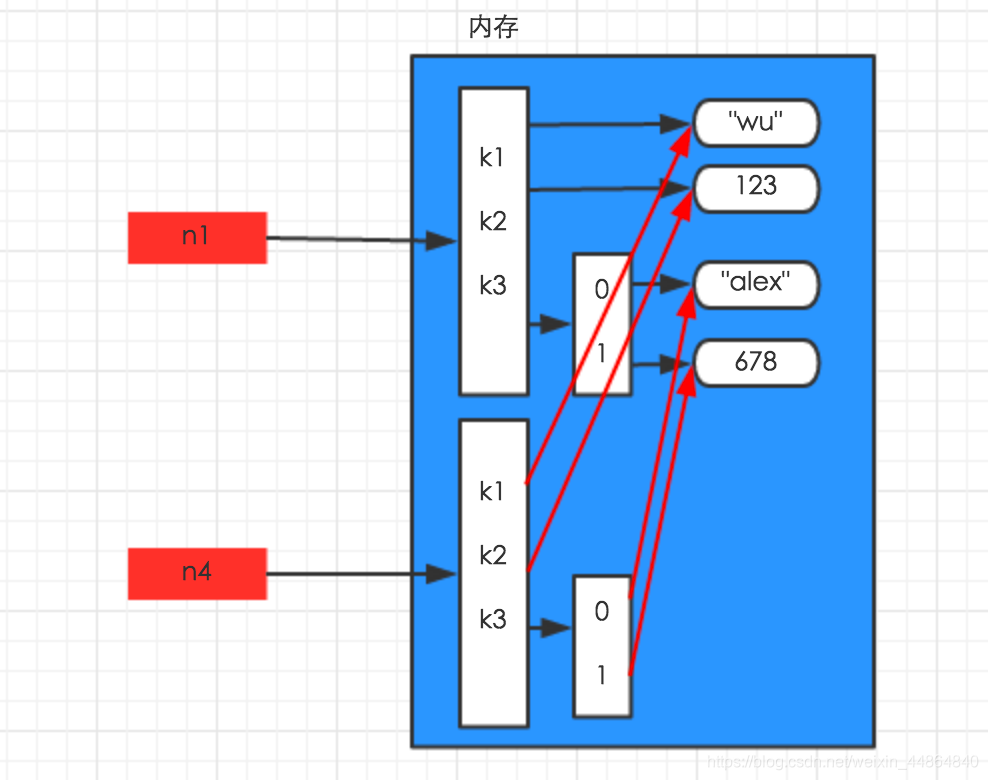
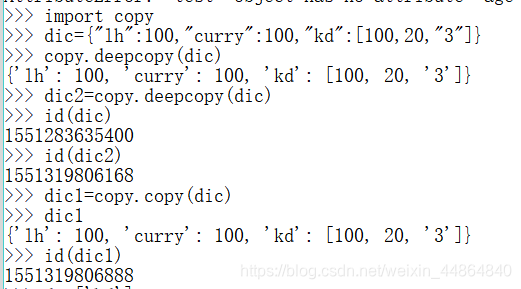
深浅拷贝后字典的起始地址均不一样,但浅拷贝字典中二层数据的地址与原字典一样,未拷贝。

- 能否解释一下 *args 和 **kwargs?
*arg会把多出来的位置参数转化为tuple
**kwarg会把关键字参数转化为dict
- 简述 生成器、迭代器、可迭代对象 以及应用场景?
生成器:一边循环一边生成的容器
迭代器:可以进行迭代,有next()方法
可迭代对象:可以用for循环进行遍历的对象,字符串,列表,元祖,字典。
- 请说明 yield 关键字的工作机制。
每次执行next(),遇到yield语句返回,再次执行时执行到下一个yield
第一次执行next(),执行到yield关键字,再执行next()方法,从yield关键字后执行到下一个yield
- 请简单谈谈装饰器的作用和功能。
在不改变原有模块的基础上,加入新的需求或功能。
如插入日志、性能测试、事务处理、缓存、权限校验等
- Python 中如何读取大数据的文件内容?
一次性读取的文件内容过大,非常危险。直接使用read())方法会造成memoryerror。
所以在读取大文件时,可以使用readline方法。
常用方法:在python中,with语句会自动使用缓冲I/O以及内存管理,不必担心资源问题
- Python 中的模块和包是什么?
模块实际上就是py文件,在模块内定义了一些封装好的功能,当需要使用这些功能时,导入该模块即可使用。
包是一个有py文件组成的目录,区别于常规目录,包目录下有__init__.py文件,用来初始化包,设置__all__值,包里可以有多个子模块和多个子包。
- python 是如何进行内存管理的(python 是如何实现垃圾回收机制的)?
引用计数为主,标记清除和分代收集为辅。
检查引用计数为0的对象,清除其内存空间。同时还有一个循环垃圾回收器,确保释放循环引用对象(a引用b,b引用a)
内存池机制:小整数池,字符串驻留
- 谈谈你对面向对象的理解?
面向对象就像站在上帝视角解决问题,在上帝眼中世间万物皆为i对象,不存在的对象也要创造出来,找到客观事物的描述和规律。 将解决事物问题的逻辑封装在方法中,侧重点在数据而非过程。
优点:易维护,易扩展
缺点:性能比面向过程低
- Python 面向对象中的继承有什么特点?
基类的构造方法不会被调用,需要在子类的构造方法中再调用
先在子类中查找调用的方法,找不到再去父类找
调用父类的方法时,需要加上父类名和self
- 面向对象中 super 的作用?
super 是用来解决多重继承问题的,直接用类名调用父类方法在使用单继承的时候没问题,但是如果使用多继承,会涉及到查找顺序(MRO)、重复调用(钻石继承)等种种问题。
- 面向对象深度优先和广度优先是什么, 并说明应用场景?
深度优先:从根出发,沿着一条线路走到头,再返回走另一条线路
广度优先:从根出发,走完与根关联的所有结点,在走完与这些关联结点相关联的所有结点。
应用场景:走迷宫,棋盘问题
- 请简述__init__和__len__这两个魔术方法的作用
__init__:构造方法,构造类的属性
__len__:返回容器的长度

















 581
581

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









