







「ICLR2021_rejected」【RETHINKING THE PRUNING CRITERIA FOR CONVOLUTIONAL NEURAL NETWORK】论文笔记

论文地址:https://openreview.net/forum?id=ZD7Ll4pAw7C
Abstract
当前Channel Pruning的工作提出了很多不同的剪枝准则去移除冗余的Filters。本文通过实验,发现不同剪枝准则的一些盲点(blind spots):
- 相似性(Similarity):the ranks of filters’ importance in a convolutional layer are almost the same, resulting in similar pruned structures.【重要性排序结果相同】
- 适应性(Applicability):For a large network (each convolutional layer has a large number of filters), some criteria can not distinguish the network redundancy well from their measured filters’ importance.【一些准则对于大模型效果不好】
本文假设对于良好训练(well-trained)的模型的卷积核服从类正态分布(Gaussian-alike)分布,并通过对假设的统计检验,在理论层面验证了以上两个发现。
1. Introduction
Several critical factors for channel pruning:
- Procedures: One-shot/Iterative
- Criteria:Norm-based/Activation-based/Importance-based/BN-based/etc…
- Strategy:Layer-wise(e.g. l 1 l_1 l1)/Global(e.g. network slimming)
本文主要分析了4个(其实是3个)不同的准则:
- l 1 l_1 l1-norm (Li et al., 2016)[1]
- l 2 l_2 l2-norm (He et al., 2018)[2]
- Fermat & GM (He et al., 2019)[3]

本文区别于之前的文章(之前主要关注模型压缩后的性能、压了多少、推理速度…),主要关注不同剪枝准则的两个盲点:
-
相似性(Similarity): What are the actual differences among these previous pruning criteria? 从Tab.1 可以看出,对于ResNet和VGG,不同剪枝准则得到的剪枝结果几乎相同。
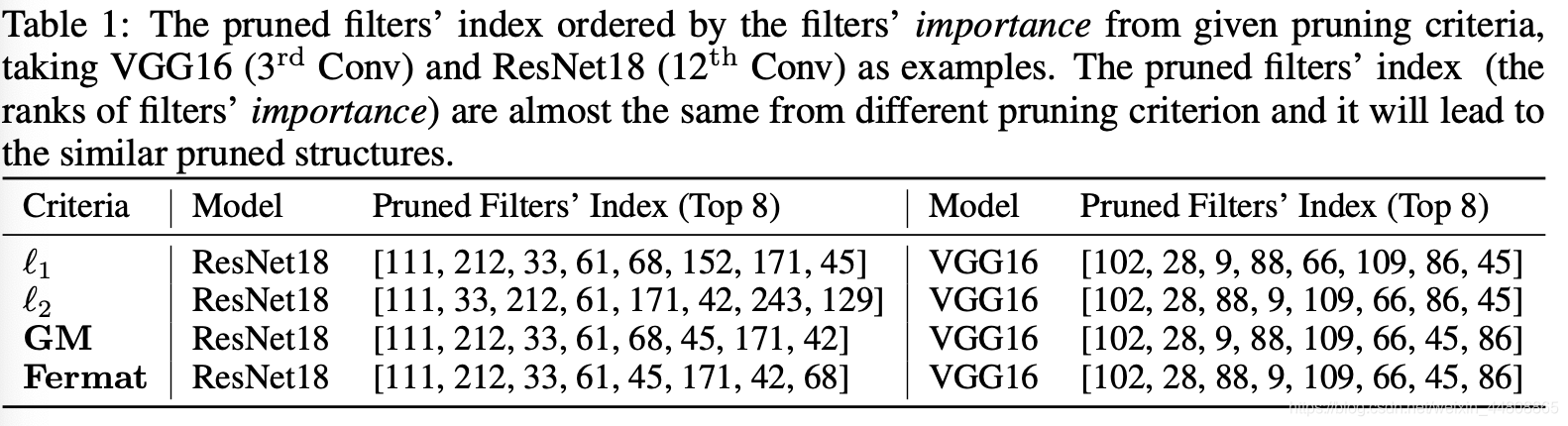
-
适应性(Applicability): What is the Applicability of these pruning criteria to prune the CNNs? 如:对于卷积核范数大小相近的卷积层,很难通过范数( l 1 l_1 l1或 l 2 l_2 l2)的方法来有效的区分其真实重要性。
文章结构:
- Section 2:提出CWDA(Convolution Weight Distribution Assumption)假设。在Appendix P做了系统和广泛的统计检验.
- Section 3 and Section 4: 理论上验证了不同剪枝准则的相似性和适应性.
- Section 5: 讨论了CWDA的成立条件、其他类型剪枝准则的相似性和适应性、其他剪枝策略:Global pruning.
2. Weight Distribution-Assumption
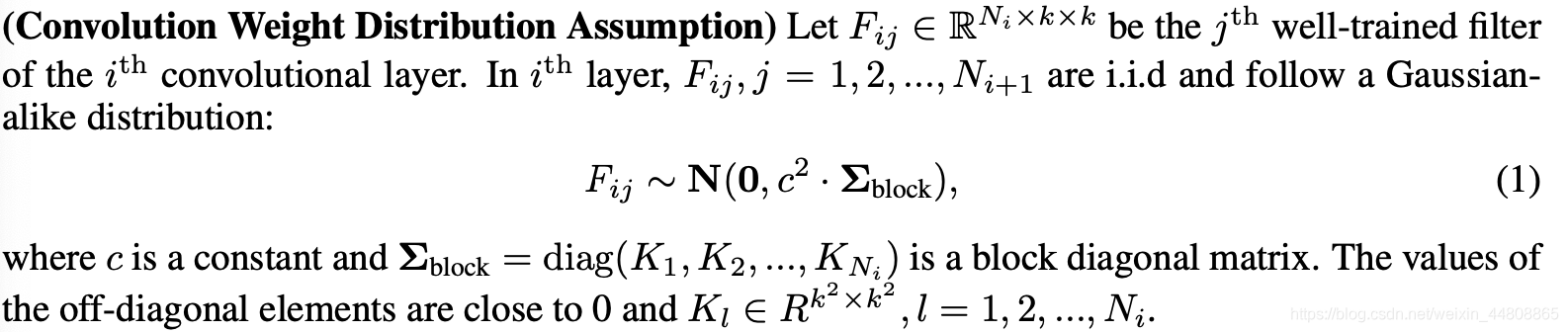
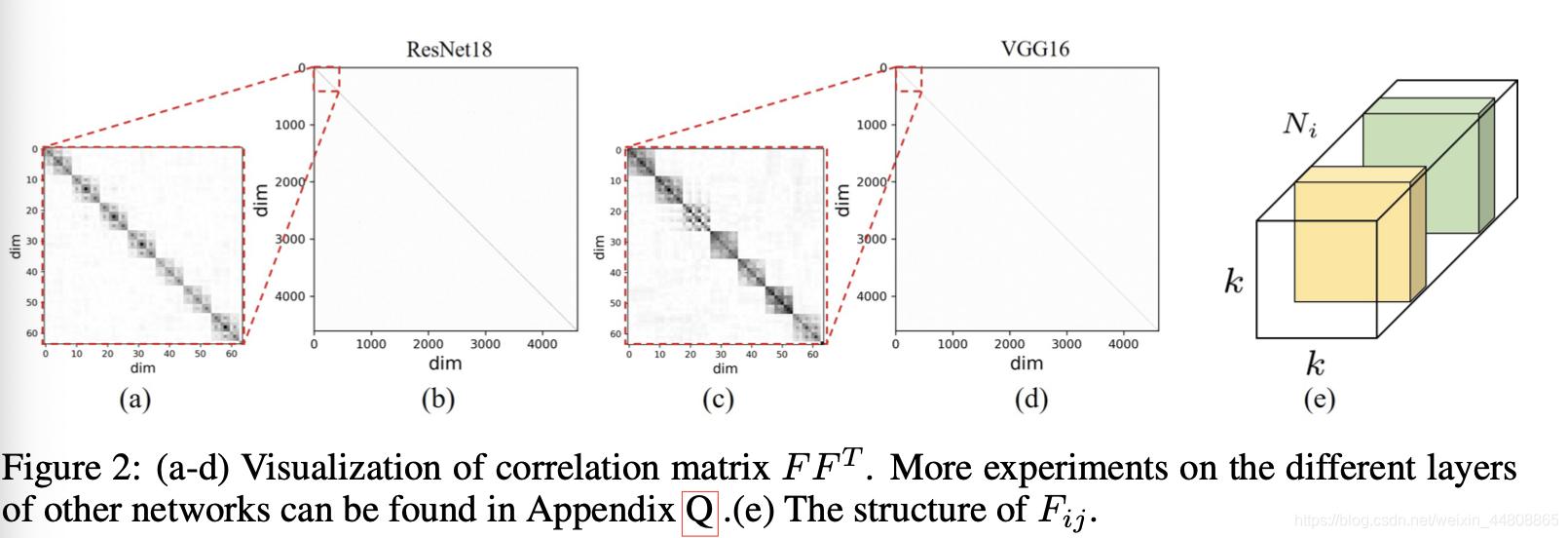
以上假设基于Fig.2. 设
F
∈
R
(
N
i
×
k
×
k
)
×
N
i
+
1
F\in \mathbb{R}^{(N_i\times k \times k)\times N_{i+1} }
F∈R(Ni×k×k)×Ni+1为第i层卷积层的权值参数,用
F
F
T
FF^T
FFT估计协方差阵
Σ
b
l
o
c
k
\bf{\Sigma_{block}}
Σblock的形状。Fig.2 可以看出
F
F
T
FF^T
FFT为块对角阵。这一现象表明:在一个卷积核
F
i
j
F_{ij}
Fij内,相同通道内的权值参数趋向于线性相关,不同通道的参数线性相关程度低。
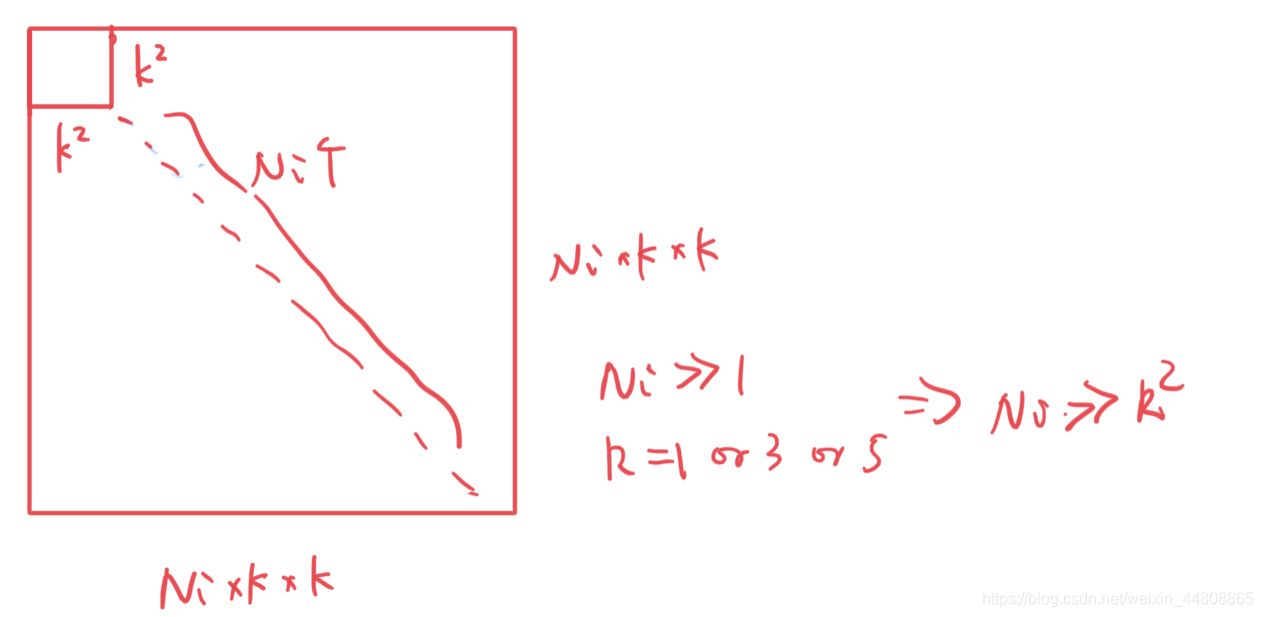
又因为卷积核的通道数
N
i
N_i
Ni远大于
k
2
k^2
k2。因此,
Σ
b
l
o
c
k
\bf{\Sigma_{block}}
Σblock可以看做是对角阵。为了分析方便,将CWDA中的假设放松为:

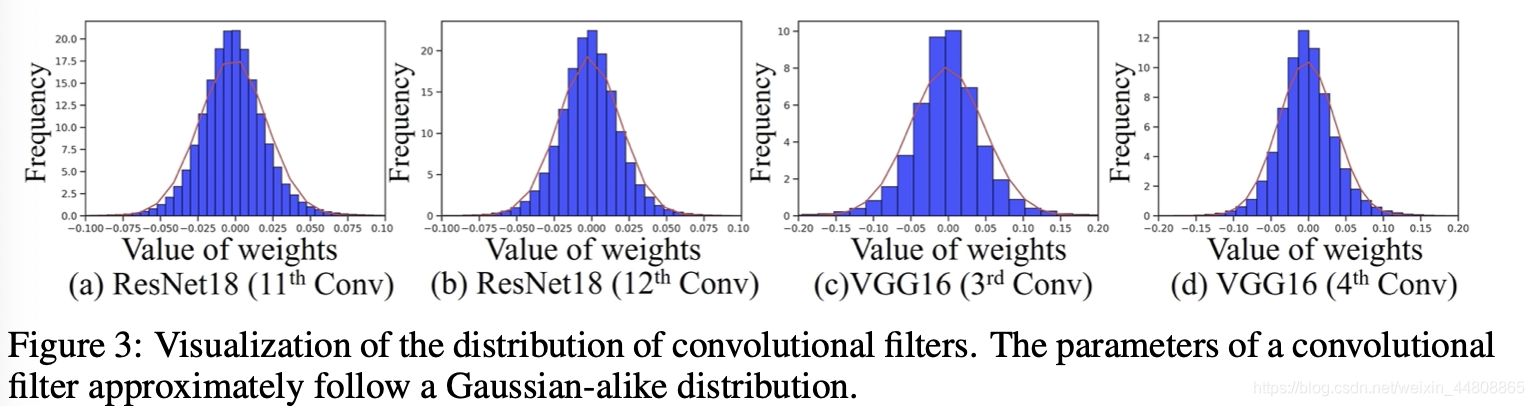
【P.S.Fig.3 可视化只能说卷积层整体服从正态,感觉可视化单个卷积核比较好】
2.1 Statistical Test
通过假设检验的方法验证了三个CWDA的必要条件:
- 正态假设
- 标准方差
- 均值为0
Details见Appendix P.
3. Similarity
本节通过实验和理论两个角度,验证了Tab.2中不同剪枝准则的相似性。
Empirical Analysis
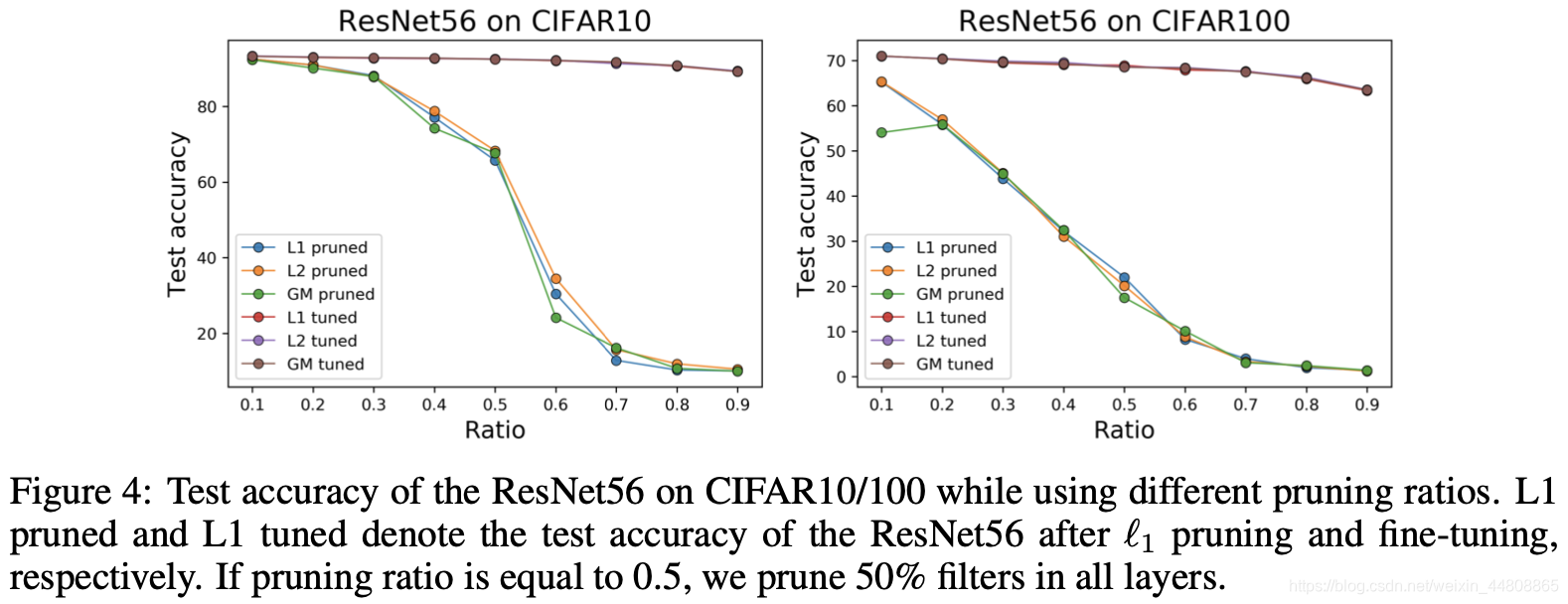
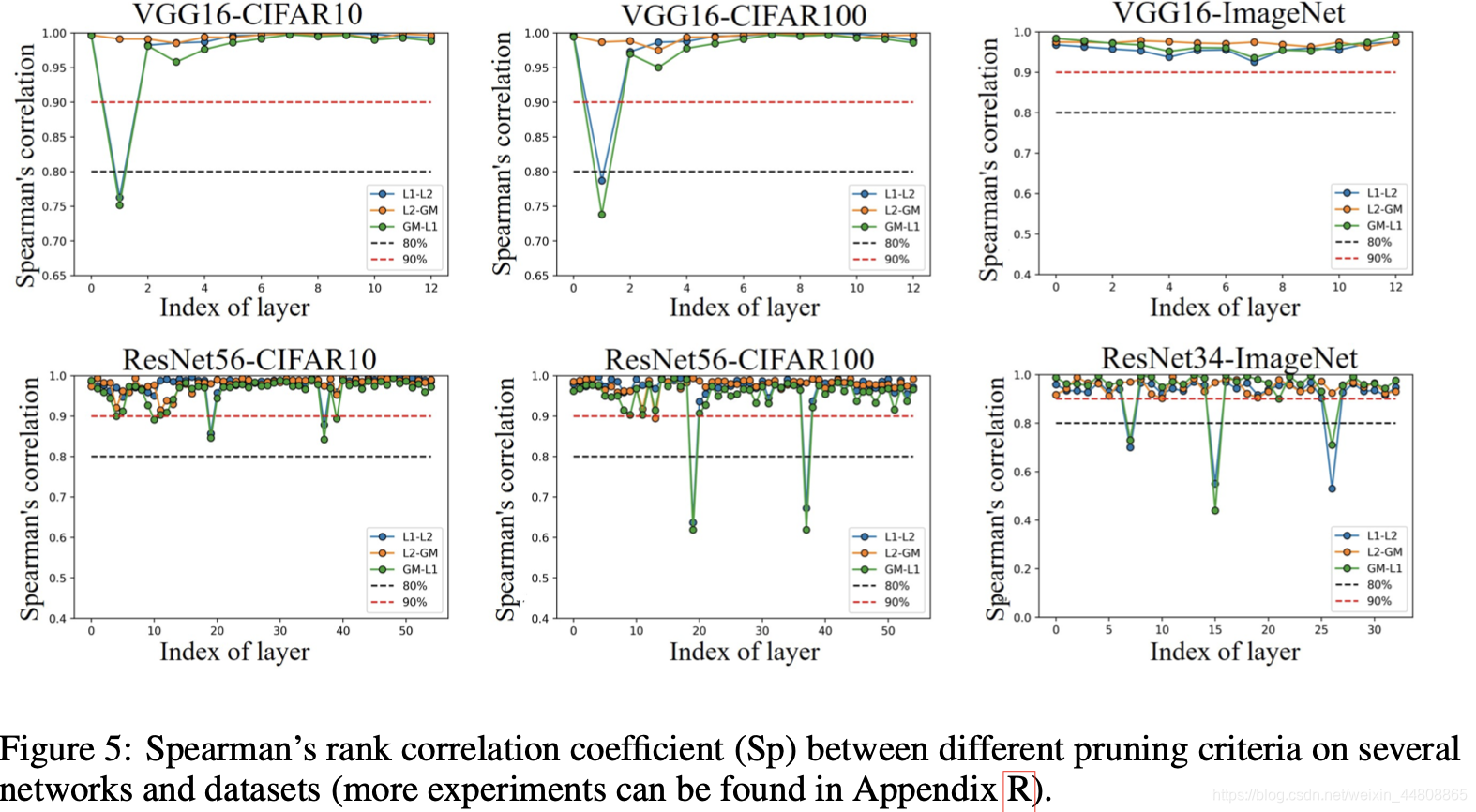
【P.S. 通过以上两图可以看出来不同剪枝准则的效果在绝大多数情况下都是相同的,尤其是Fig.4,经过finetune后,更方法精度几乎相同(当然也有比例尺的问题),个人认为这个地方加一个和随机剪枝的对比会更好。另外CIFAR上可信度不太高,ImageNet上做实验更好。Fig.5上做的结构相似度对比可以看出来其实大部分层是差不多的,但是还是存在一些特殊情况,尤其是L1-GM和L1-L2。】
Theoretical Analysis

特别地:



4. Applicability
- 主要针对Norm-based准则去对大模型(各卷积层卷积核足够多)剪枝.
- 适应性问题:当权值参数方差小,norm-based不好(He et al., 2019)[3]。本文进一步提出,可能当方差够大仍然会有适应性的问题出现。这是因为可能重要性的数量级要比方差的数量级大。【P.S. 我的理解就是方差的大小不足以对不同卷积核的重要程度进行区分。感觉这个地方用importance这个词不太好,用norm value不较好】
原文:However, even if the values of the variance are large, it may still have the Applicability problems. This is because the magnitude of these importance may be much greater than the values of the variance, where we can use the mean of importance to represent their magnitude.
- 造成适应性问题的条件:

【P.S.第二个其实就是说范数值很大,方差也很大的情况,但是方差相对于范数值不够大,简单画了个示意图,可能描述的也不太准确,但就是这个意思应该】

5. Discussion
5.1 WHY CWDA SOMETIMES DOES NOT HOLD?
- 训练不够好
- 卷积核数目少的时候过不了假设检验
- 卷积核维度不够大
【P.S. 个人还是不太理解这个卷积核数目和维度有什么区别,维度是把所有的乘到一起吗?求大神解答】
5.2 WHAT ABOUT OTHER PRUNING CRITERIA?
略
5.3 WHAT ABOUT GLOBAL PRUNING?
略
6. Conclusion

【Ed.'s Understanding】
这篇文章出来的时候自己还是很感兴趣的,自己前段时间也在做channel pruning的东西,做实验时候确实发现各种文章提出的剪枝准则天花乱坠说了一堆,其实最终效果其实都和L1差不多,包括Global的那些方法,搜了半天结构,然后在相同FLOPs下其实没比简单的L1好多少。只要后期finetune够多完全可以弥补。
这篇文章算是把这个问题正式抛出来了,虽然最后没投中,但是还是挺值得Pruning这个领域的人研究的,到底怎么去评价一个剪枝算法是否真的有提升。都可以进一步讨论。
对于文章的内容个人感觉那个假设还是有待进一步验证的,简单的认为服从一个正态分布确实有点太naive了感觉。以上全都是个人想法,不喜勿喷。
[1]: Hao Li, Asim Kadav, Igor Durdanovic, Hanan Samet, and Hans Peter Graf. Pruning filters for efficient convnets. arXiv preprint arXiv:1608.08710, 2016.
[2]: Yang He, Guoliang Kang, Xuanyi Dong,
Yanwei Fu, and Yi Yang. Soft filter pruning for accelerating deep convolutional neural networks. arXiv preprint arXiv:1808.06866, 2018.
[3]: Yang He, Ping Liu, Ziwei Wang, Zhilan Hu, and Yi Yang. Filter pruning via geometric median for deep convolutional neural networks acceleration. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 4340–4349, 2019.


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









