









1. 什么是索引
索引 是帮助MySQL高效获取数据的实现类高级查找算法的数据结构,当表的数据量越来越大时,索引对性能的影响愈发重要,索引一般以文件的形式存储在硬盘
索引可以包含一个或多个列的值。如果索引包含多个列,则列的顺序十分重要(MySQL只能高效地使用索引的最左前缀列)。创建一个包含两个列的索引,和创建两个只包含一列的索引是大不相同的;使用ORM,也要关注索引
2. 索引的类型
MySQL中,索引是在存储引擎层而不是服务器层实现的,所以没有统一的索引标准:不同存储引擎的索引的工作方式不同,也不是所有的存储引擎都支持所有类型的索引。即使多个存储引擎支持同一种类型的索引,其底层的实现也可能不同
2.1 B-Tree
B-Tree通常意味着所有的值都是按顺序存储的,并且每一个叶子页到根的距离相同
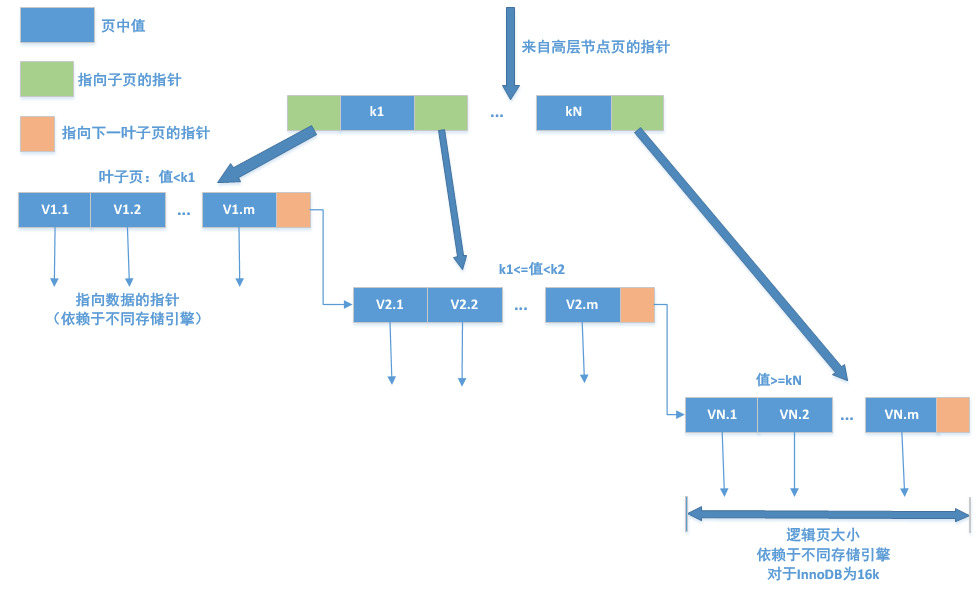
B-Tree索引能加快访问数据的速度,因为存储引擎不再需要进行全表扫描来获取需要的数据,而是从索引的根节点(图示并未画出)开始进行搜索。根节点的槽中存放了指向子节点的指针,存储引擎根据这些指针向下层查找。通过比较节点页的值和要查找的值可以找到合适的指针进入下层子节点,这些指针实际上定义了子节点页中值的上限和下限。最终存储引擎要么是找到对应的值,要么该记录不存在
存储引擎以不同的方式使用B-Tree索引,性能也各有不同;B-Tree对索引列是顺序组织存储的,所以适合查找范围数据
B-Tree索引适用于全键值、键值范围或键前缀查找。其中键前缀查找只适用于根据最左前缀的查找。前面所述的索引对如下类型的查询有效
- 全值匹配:和索引中的所有列进行匹配
- 匹配最左前缀:只使用索引的第一列,如以a开头的姓名
- 匹配列前缀:只匹配某一列的值的开头部分,也只使用了索引的第一列
- 匹配范围值:匹配某个范围内的对象,如查找姓在Allen和Barrymore之间的人
- 精确匹配某一列并范围匹配另外一列:如姓名是全匹配,年龄是范围匹配
B-Tree索引的限制
- 如果不是按照索引的最左列开始查找,则无法使用索引
- 不能跳过索引中的列
- 如果查询中有某个列的范围查询,则其右边所有列都无法使用索引优化查找
2.2 哈希索引
哈希索引(hash index)基于哈希表实现,只有精确匹配索引所有列的查询才有效。是Memory引擎表的默认索引类型,存储引擎都会对每一行数据计算一个哈希码(hash code),哈希码是一个较小的值,并且不同键值的行计算出来的哈希码也不一样。哈希索引将所有的哈希码存储在索引中,同时在哈希表中保存指向每个数据行的指针
例如对一个表进行查询后,对查询结果的每一行数据都赋予了一个哈希值,‘a’=3241,b’’=2253,‘c’=4451,‘d’=3257,则对应的哈希索引的数据结构如下(下列哈希值是实例数据,非真实数据)
| 槽(Slot) | 值(Value) |
|---|---|
| 2253 | 指向第一行的指针(b) |
| 3241 | 指向第一行的指针(a) |
| 3257 | 指向第一行的指针(d) |
| 4451 | 指向第一行的指针(c) |
注意槽的编号是顺序的,数据行要对应编号
这样做的性能会非常高,因为MySQL优化器会使用这个选择性很高而体积很小的基于url_crc列的索引来完成查找(在上面的案例中,索引值为1560514994)。即使有多个记录有相同的索引值,查找仍然很快,只需要根据哈希值做快速的整数比较就能找到索引条目,然后一一比较返回对应的行
哈希索引的限制
- 哈希索引只包含哈希值和行指针,而不存储字段值,所以不能使用索引中的值来避免读取行
- 哈希索引数据并不是按照索引值顺序存储的,所以也就无法用于排序
- 哈希索引也不支持部分索引列匹配查找,因为哈希索引始终是使用索引列的全部内容来计算哈希值的
- 哈希索引只支持等值比较查询,包括=、IN()、<=>(注意<>和<=>是不同的操作)。也不支持任何范围查询,例如WHERE price>100
- 访问哈希索引的数据非常快,除非有很多哈希冲突(不同的索引列值却有相同的哈希值)
- 如果哈希冲突很多的话,一些索引维护操作的代价也会很高
InnoDB引擎有一个特殊的功能叫做“自适应哈希索引(adaptive hash index)”。当某些索引值被频繁使用时,会在内存中基于B-Tree索引之上再创建一个哈希索引,让B-Tree索引也具有哈希索引的一些优点;例如用B-Tree来存储URL(URL本身都很长),就可以用CRC32做哈希,就可以使用下面的方式查询

实例
- 创建表
CREATE TABLE pseudohash ( id int unsigned NOT NULL auto_increment, url varchar(255) NOT NULL, url_crc int unsigned NOT NULL DEFAULT 0, PRIMARY KEY(id) );- 然后创建触发器。先临时修改一下语句分隔符,这样就可以在触发器定义中使用分号
DELIMITER // CREATE TRIGGER pseudohash_crc_ins BEFORE INSERT ON pseudohash FOR EACH ROW BEGIN SET NEW.url_crc=crc32(NEW.url); END; // CREATE TRIGGER pseudohash_crc_upd BEFORE UPDATE ON pseudohash FOR EACH ROW BEGIN SET NEW.url_crc=crc32(NEW.url); END; // DELIMITER ;-
验证一下触发器如何维护哈希索引
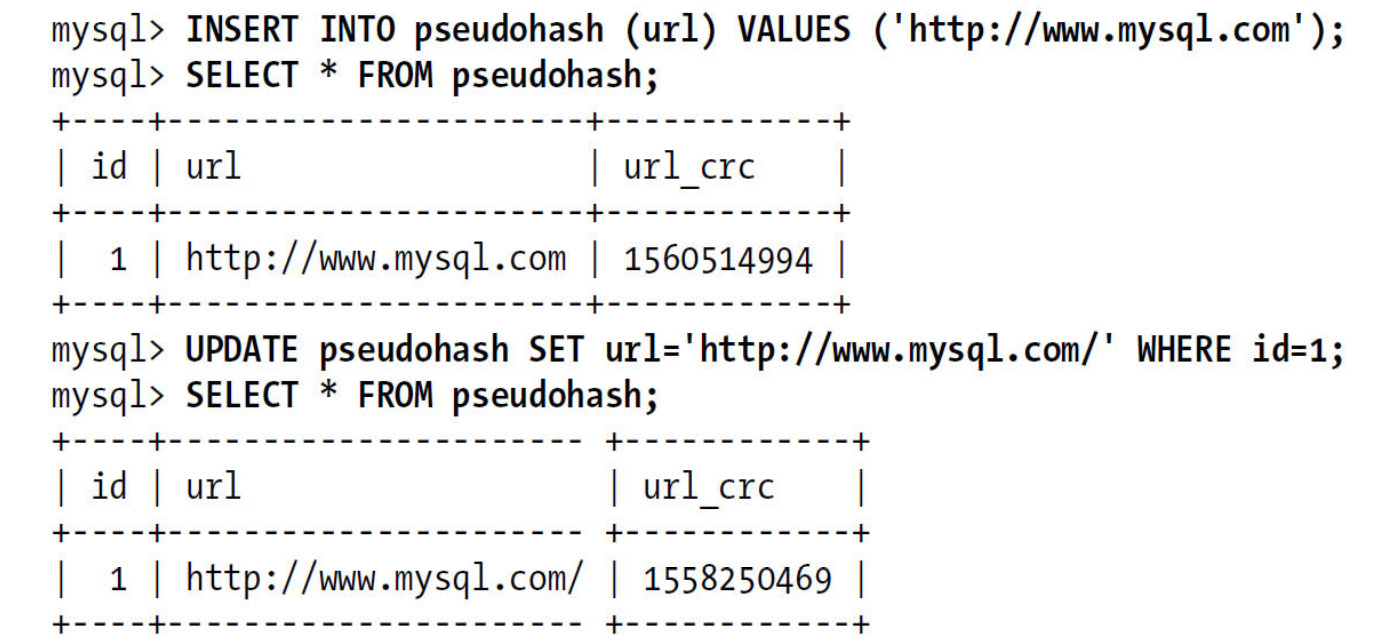
采用这种方式,记住不要使用SHA1()和MD5()作为哈希函数。因为这两个函数计算出来的哈希值是非常长的字符串,会浪费大量空间,比较时也会更慢。SHA1()和MD5()是强加密函数,设计目标是最大限度消除冲突,这里不需要这样高的要求。简单哈希函数的冲突在一个可以接受的范围,同时又能够提供更好的性能
这种索引因为容易出现哈希冲突(“生日悖论”、哈希值重复),所以必须在WHERE子句中包含常量值:
mysql> SELECT id FROM url WHERE url_crc=CRC32("http://www.mysql.com") -> AND url="http://www.mysql.com";

2.3 空间数据索引(R-Tree)
MyISAM表支持空间索引,可以用作地理数据存储。和B-Tree索引不同,这类索引无须前缀查询。空间索引会从所有维度来索引数据。查询时,可以有效地使用任意维度来组合查询。必须使用MySQL的GIS相关函数如MBRCONTAINS()等来维护数据
2.4 全文索引
全文索引是一种特殊类型的索引,它查找的是文本中的关键词,而不是直接比较索引中的值。全文搜索和其他几类索引的匹配方式完全不一样。它有许多需要注意的细节,如停用词、词干和复数、布尔搜索等。全文索引更类似于搜索引擎做的事情,而不是简单的WHERE条件匹配;
在相同的列上同时创建全文索引和基于值的B-Tree索引不会有冲突,全文索引适用于MATCH AGAINST操作,而不是普通的WHERE条件操作
2.5 其他索引类别
还有很多第三方的存储引擎使用不同类型的数据结构来存储索引。例如TokuDB使用分形树索引(fractal tree index),这是一类较新开发的数据结构,既有B-Tree的很多优点,也避免了B-Tree的一些缺点
ScaleDB使用Patricia tries(这个词不是拼写错误),其他一些存储引擎技术如InfiniDB和Infobright则使用了一些特殊的数据结构来优化某些特殊的查询
3. 索引的优点
只有当索引帮助存储引擎快速查找到记录带来的好处大于其带来的额外工作时,索引才是有效的。对于非常小的表,大部分情况下简单的全表扫描更高效。对于中到大型的表,索引就非常有效。但对于特大型的表,建立和使用索引的代价将随之增长。这种情况下,则需要一种技术可以直接区分出查询需要的一组数据,而不是一条记录一条记录地匹配
总结
- 索引大大减少了服务器需要扫描的数据量
- 索引可以帮助服务器避免排序和临时表
- 索引可以将随机I/O变为顺序I/O
该学习笔记学习自《高性能MySQL》/(美)Schwartz,(美)Zaitsev,(美)Tkachenko著 宁海元等译

















 2305
2305

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









