







简述
什么是MapReduce
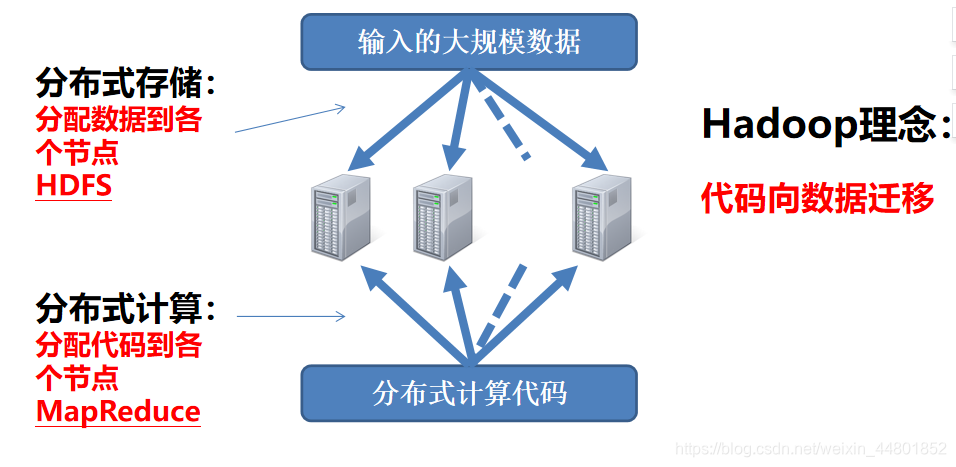
Hadoop下的一个负责分布式计算的组件
一个软件系统,运行于HDFS之上
定义了一种实现分布式计算的框架
负责计算任务在集群中的分配调度、负载均衡、容错处理、网络通信等一系列问题
方便编程人员在不熟悉分布式并行编程的情况下,能够编写程序对分布式环境下的大数据进行处理
借鉴了函数式编程
函数:集合之间的一种映射关系
不同于命令式编程,函数式编程关注集合之间的映射关系
函数可以作为另一个函数的输入和输出
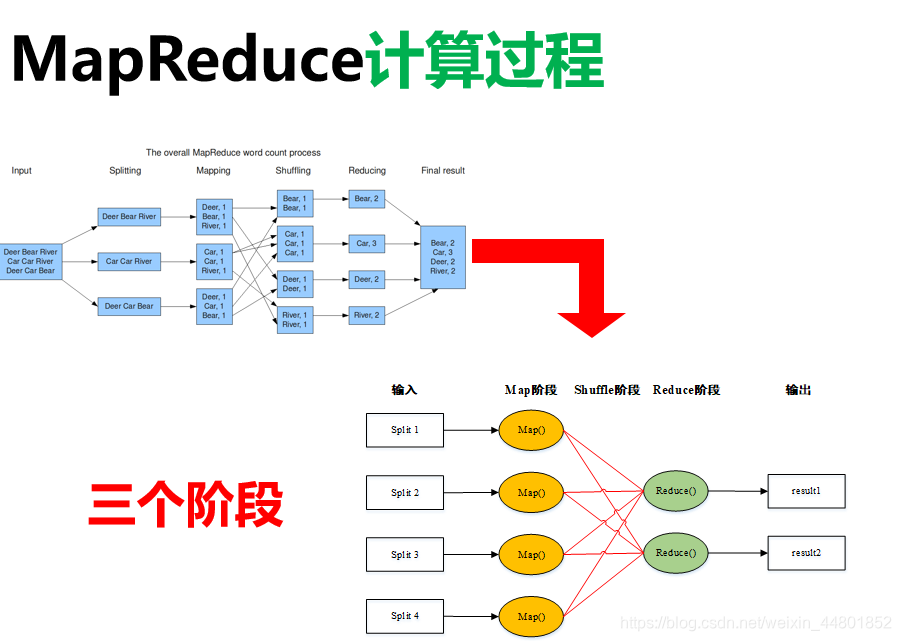
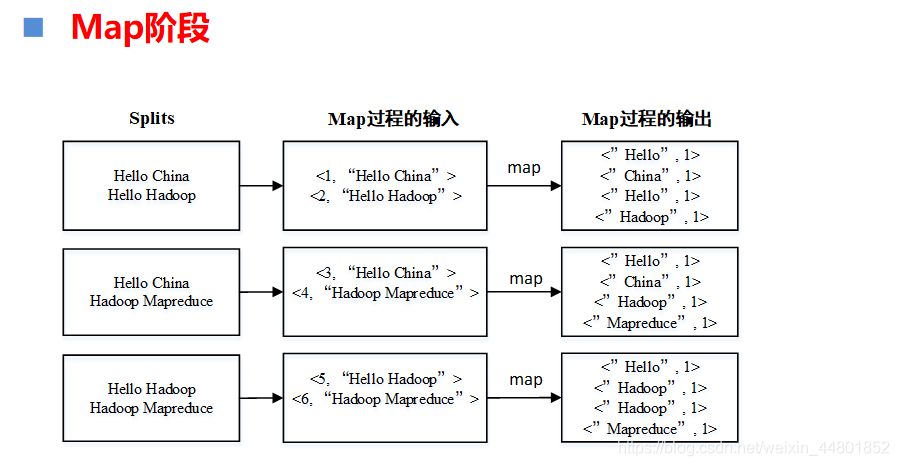
MapReduce框架
将分布式环境下的并行大数据处理过程抽象为两个函数:map和reduce
Map: <key1,value1> -> <key2, value2>
Reduce: <key2,value-list> -> <key3, value3>
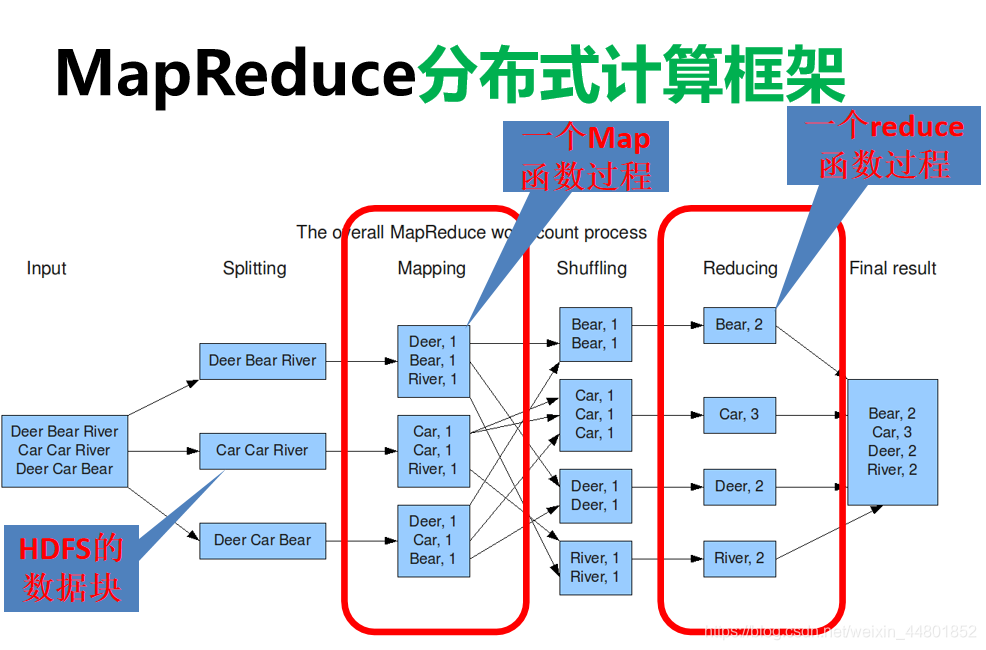
MapReduce适合的场景:待处理的大数据集可以分成不同的数据块,而且每个小数据块可以独立的并行的进行处理
比如求最大值最小值,计数等
但是中位数不能计算,因为求中位数每个小数据块并不能进行独立的计算。
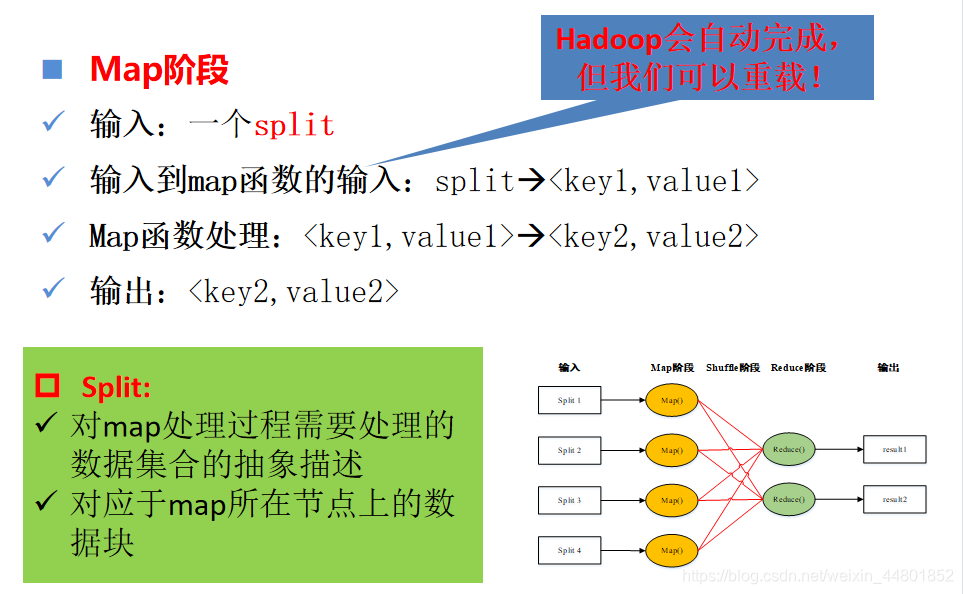
Split是数据块的描述,并不是具体的数据。
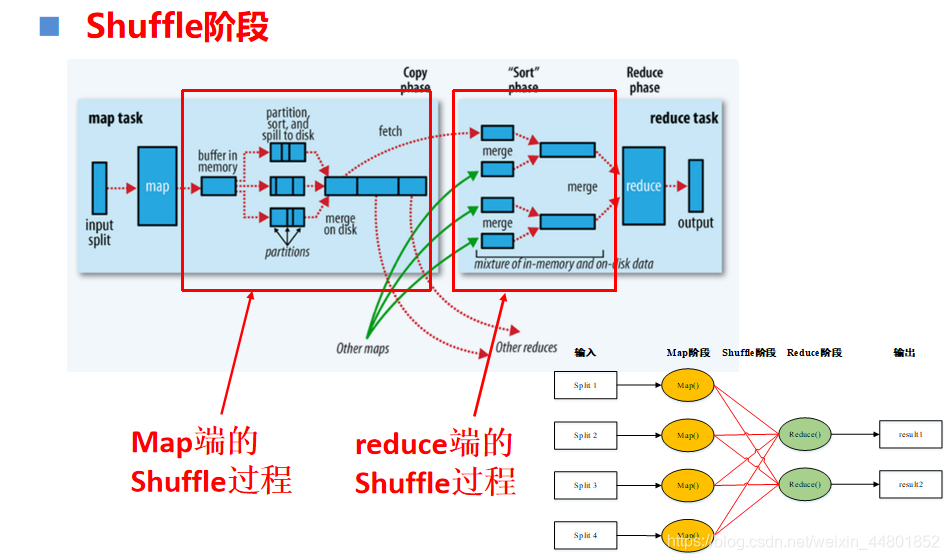
Partition分区操作
将map产生的不同<key, value>键值对分配给不同的reduce
默认是根据对map输出的<key, value>键值对中的key值进行Hash运算(hash(key)%num_reduceTasks)的结果来将数据进行分区
实际中也可以通过重载分区接口来改写分区的方式
Combine合并操作
将一个分区内相同key的value进行合并运算处理,以减少需要在map和reduce之间传输的数据量
常见的合并运算包括求和、取最大、取最小
在实际中是可选的,它要求编程人员重载合并接口并进行明确的设置
合并前: 合并后:
第一个分区:<”China”, 1> 第一个分区:<”China”, 1>
第二个分区:<”Hello”, 1> 第二个分区:<”Hello”, 2>
<”Hello”, 1> <”Hadoop”, 1>
<”Hadoop”, 1>
Merge文件合并操作
MapReduce将map产生的<key, value>数据写入磁盘,每次写入磁盘都会形成一个文件
在map过程结束之后,merge操作将map过程产生的多个文件合并成一个大文件
将不同文件中相同分区的<key, value>数据划分到同一个分区并重新进行排序
将一个分区内来自不同文件的相同的key的数据进行合并形成一个新的<key, value-list>形式的数据

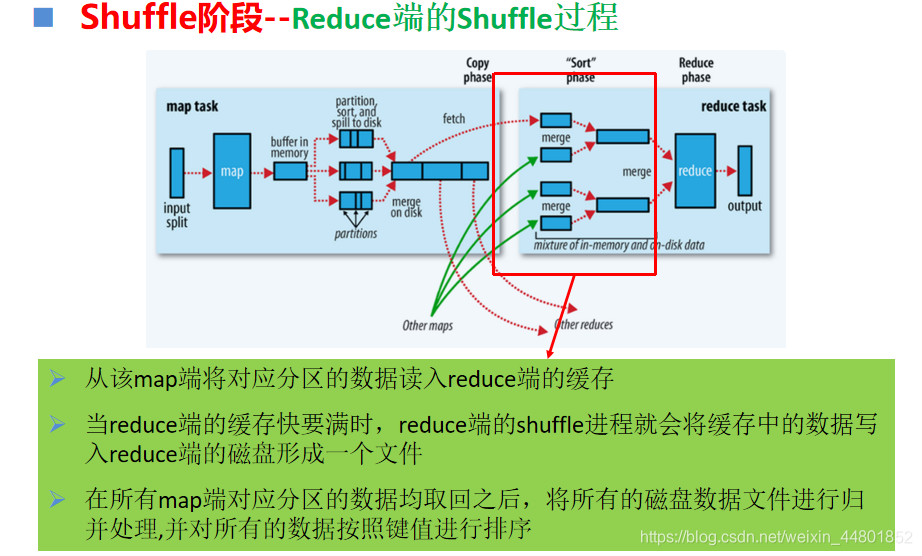
Reduce阶段
根据用户对reduce函数的定义,对每个新的<key, value-list>形式的键值对数据通过执行reduce函数进行处理
将最终的结果输出到文件系统
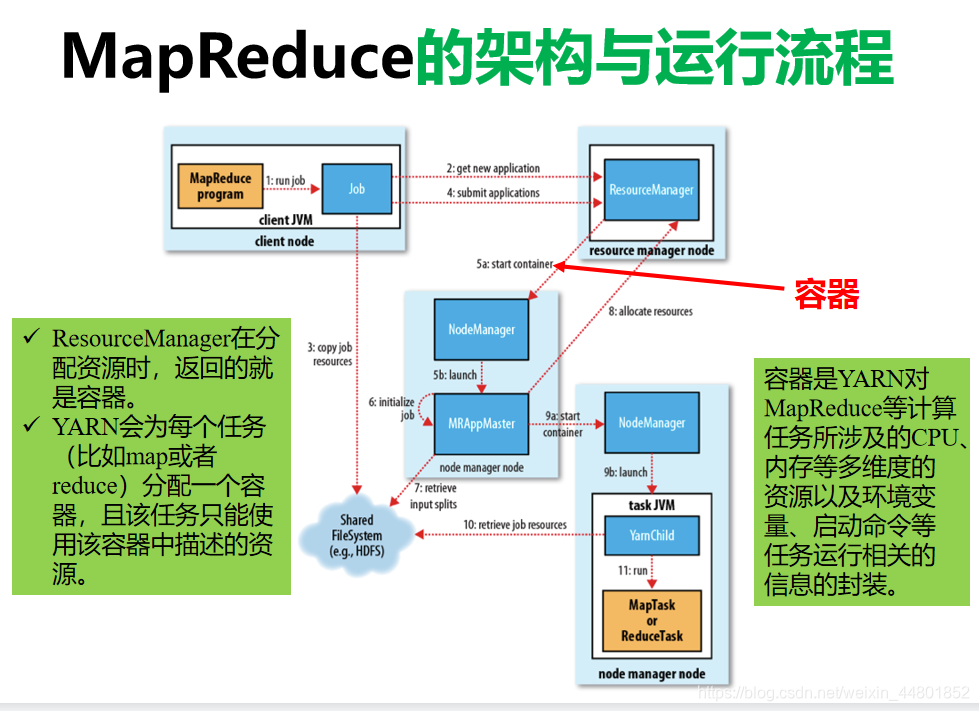
Hadoop资源管理器:yarn
Yet Another Resource Negotiator
为集群提供通用的资源管理和调度服务
不仅能够运行MapReduce任务,而且能运行Spark等任务
主要包括两个进程:ResourceManager、NodeManager
ResourceManager :
控制整个集群的资源
并负责向具体的计算任务分配基础计算资源
NodeManager :
管理集群中单个节点的计算资源
跟踪管理节点上的每个容器以及节点的健康状况
WordCount的MapReduce程序(idea+maven)
pom文件
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<!-- 如下的groupID、artifactID、version标签都是建立maven项目时所要填写的信息。这些信息需要针对自己所建立的maven项目进行修改 -->
<groupId>com.liu</groupId>
<artifactId>WrodCount</artifactId>
<version>1.0-SNAPSHOT</version>
<!-- 示例所依赖的jar包都通过如下的标签给出 -->
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.10.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.10.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>2.10.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-jobclient</artifactId>
<version>2.10.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-common</artifactId>
<version>2.10.0</version>
</dependency>
</dependencies>
</project>
程序
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.*;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
import java.util.StringTokenizer;
public class WordCount {
public static class MyMapper extends Mapper<Object, Text, Text, IntWritable>{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context)
throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
//将结果写入context
context.write(word, one);
}
}
}
public static class MyReducer
extends Reducer<Text,IntWritable,Text,IntWritable> {
private IntWritable result = new IntWritable();
//从这可以看出reduce处理的输入数据是<key, value-list>类型的键值对
public void reduce(Text key, Iterable<IntWritable> values,Context context)
throws IOException, InterruptedException {
int sum = 0;
//reduce函数就是对列表values中的数值进行相加
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
//将结果写入context
context.write(key, result);
}
}
/*
1.WordCount的main函数。
2.main函数主要创建一个job对象,然后对WordCount任务所需的map函数、reduce函数、输入文件路径、输出文件路径等信息进行配置。
*/
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "word count");//获取一个任务实例
job.setJarByClass(WordCount.class);//设置工作类
job.setMapperClass(MyMapper.class);//设置Mapper类
job.setReducerClass(MyReducer.class);//设置Reducer类
job.setOutputKeyClass(Text.class);//设置输出键值对中key的类型
job.setOutputValueClass(IntWritable.class);//设置输出键值对中value的类型
FileInputFormat.addInputPath(job, new Path(args[0]));//设置输入文件的路径
FileOutputFormat.setOutputPath(job, new Path(args[1]));//设置输出文件的路径
FileSystem fs=FileSystem.get(conf);//获取HDFS文件系统
fs.delete(new Path(args[1]),true);//删除输出路径下可能已经存在的文件
boolean result=job.waitForCompletion(true);//提交运行任务
System.exit(result? 0: 1);//如result为 false则等待任务结束
}
}

















 448
448

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









