 Kafka事务机制及API使用解析
Kafka事务机制及API使用解析





目录
1、kafka事务的机制
1.1 幂等性
Producer 的幂等性指的是当发送同一条消息时,数据在 Server 端只会被持久化一次,数据不丟不重,Kafka为了实现幂等性,底层设计架构中引入了ProducerID和SequenceNumbe。
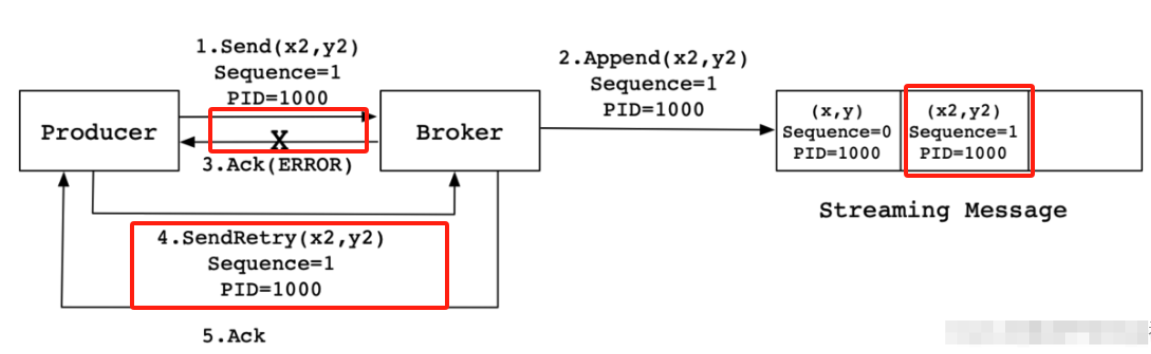
当Producer发送消息(x2,y2)给Broker时,Broker接收到消息并将其追加到消息流中。此时,Broker返回Ack信号给Producer时,发生异常导致Producer接收Ack信号失败。对于Producer来说,会触发重试机制,将消息(x2,y2)再次发送,但是,由于引入了幂等性,在每条消息中附带了PID(ProducerID)和SequenceNumber。相同的PID和SequenceNumber发送给Broker,而之前Broker缓存过之前发送的相同的消息,那么在消息流中的消息就只有一条(x2,y2),不会出现重复发送的情况。
缺点:Kafka 的 Exactly Once 幂等性只能保证单次会话内的精准一次性,不能解决
跨会话和跨分区的问题;
1.2 事务的原子性
事务原子性是指 Producer 将多条消息作为一个事务批量发送,要么全部成功要么全部失败。 引入了一个服务器端的模块,名为Transaction Coordinator,用于管理 Producer 发送的消息的事务性。
该Transaction Coordinator维护Transaction Log,该 log 存于一个内部的 Topic 内。由于 Topic 数据具有持久性,因此事务的状态也具有持久性。
Producer 并不直接读写Transaction Log,它与Transaction Coordinator通信,然后由Transaction Coordinator将该事务的状态插入相应的Transaction Log。
Transaction Log的设计与Offset Log用于保存 Consumer 的 Offset 类似。
Kafka事务的回滚,并不是删除已写入的数据,而是将写入数据的事务标记为 Rollback/Abort 从而在读数据时过滤该数据。
1.3 事务的原理
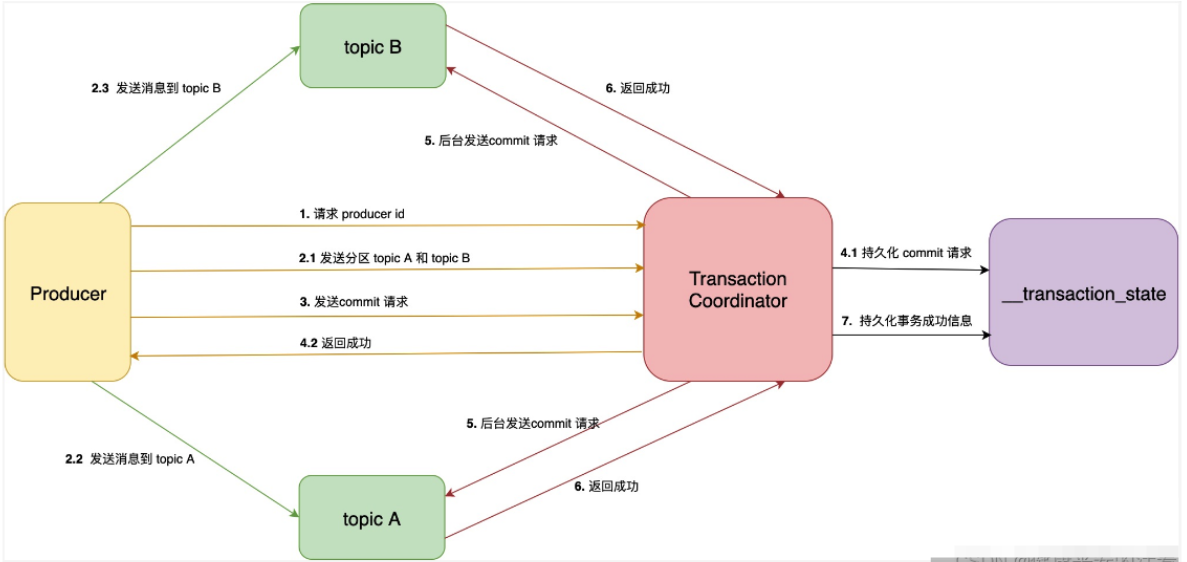
图中的 Transaction Coordinator 运行在 Kafka 服务端,下面简称 TC 服务。
__transaction_state 是 TC 服务持久化事务信息的 topic 名称,下面简称事务 topic。
Producer 向 TC 服务发送的 commit 消息,下面简称事务提交消息。
TC 服务向分区发送的消息,下面简称事务结果消息。
1.4 事务的作用
kafka的事务机制,是kafka实现端到端有且仅有一次语义的基础。Kafka 的 Exactly Once 幂等性只能保证单次会话内的精准一次性,不能解决跨会话和跨分区的问题;
Kafka的事务特性本质上是支持了Kafka跨分区和Topic的原子写操作。
通过事务机制,KAFKA 可以实现对多个 topic 的多个 partition 的原子性的写入,即处于同一个事务内的所有消息,不管最终需要落地到哪个 topic 的哪个 partition, 最终结果都是要么全部写成功,要么全部写失败(Atomic multi-partition writes);开启事务,必须开启幂等性,KAFKA的事务机制,在底层依赖于幂等生产者。
Kafka的事务特性就是要确保跨分区的多个写操作的原子性。
具体的场景包括:Producer多次发送消息可以封装成一个原子性操作,即同时成功,或者同时失败;(可以是跨多分区的写入)Consumer-Transform-Producer模式下,因为消费者提交偏移量出现问题,导致在重复消费消息时,生产者重复生产消息。需要将这个模式下消费者提交偏移量操作和生成者一系列生成消息的操作封装成一个原子操作。
为支持事务机制,KAFKA 引入了两个新的组件:
Transaction Coordinator 和
Transaction Log,其中 transaction coordinator 是运行在每个 kafka broker 上的一个模块,是 kafka broker 进程承载的新功能之一(不是一个独立的新的进程);而 transaction log 是 kakafa 的一个内部 topic;
1.5 拒绝僵尸实例
在分布式系统中,一个instance的宕机或失联,集群往往会自动启动一个新的实例来代替它的工作。此时若原实例恢复了,那么集群中就产生了两个具有相同职责的实例,此时前一个instance就被称为“僵尸实例(Zombie Instance)”。在Kafka中,两个相同的producer同时处理消息并生产出重复的消息(read-process-write模式),这样就严重违反了Exactly Once Processing的语义。这就是僵尸实例问题。
解决办法:
kafka事务特性通过transaction-id属性来解决僵尸实例问题。所有具有相同transaction-id的Producer都会被分配相同的pid,同时每一个Producer还会被分配一个递增的epoch。Kafka收到事务提交请求时,如果检查当前事务提交者的epoch不是最新的,那么就会拒绝该Producer的请求。从而达成拒绝僵尸实例的目标。
1.6 开启事务的生产者和消费者
1)生产者:开启了事务的生产者,生产的消息最终还是正常写到目标 topic 中,但同时也会通过 transaction coordinator 使用两阶段提交协议,将事务状态标记 transaction marker,也就是控制消息 controlBatch,写到目标 topic 中,控制消息共有两种类型 commit 和 abort,分别用来表征事务已经成功提交或已经被成功终止;
2)消费者:开启了事务的消费者,如果配置读隔离级别为 read-committed, 在内部会使用存储在目标 topic-partition 中的事务控制消息,来过滤掉没有提交的消息,包括回滚的消息和尚未提交的消息,从而确保只读到已提交的事务的 message;
开启了事务的消费者,过滤消息时,KAFKA consumer 不需要跟 transactional coordinator 进行 rpc 交互,因为 topic 中存储的消息,包括正常的数据消息和控制消息,包含了足够的元数据信息来支持消息过滤;
3)总结:kakfa 的 producer 和 consumer 是解耦的,也可以使用非 transactional consumer 来消费 transactional producer 生产的消息,此时目标 topic-partition 中的所有消息都会被返回,不会进行过滤,此时也就丢失了事务 ACID 的支持;
2、事务的api
- 对于Producer,需要设置transactional.id属性,这个属性的作用下文会提到。设置了transactional.id属性后,enable.idempotence属性会自动设置为true。
- 对于Consumer,需要设置isolation.level = read_committed,这样Consumer只会读取已经提交了事务的消息。另外,需要设置enable.auto.commit = false来关闭自动提交Offset功能。
2.1 生产者
/**
* 初始化事务
*/
public void initTransactions();
/**
* 开启事务
*/
public void beginTransaction() throws ProducerFencedException ;
/**
* 在事务内提交已经消费的偏移量
*/
public void sendOffsetsToTransaction(Map<TopicPartition, OffsetAndMetadata> offsets,
String consumerGroupId) throws ProducerFencedException ;
/**
* 提交事务
*/
public void commitTransaction() throws ProducerFencedException;
/**
* 丢弃事务
*/
public void abortTransaction() throws ProducerFencedException ;2.2 Write-process-wirte
KafkaProducer producer = createKafkaProducer(
"bootstrap.servers", "localhost:9092",
"transactional.id”, “my-transactional-id");
producer.initTransactions();
producer.beginTransaction();
producer.send("outputTopic", "message1");
producer.send("outputTopic", "message2");
producer.commitTransaction();2.3 Read-process-Write
KafkaProducer producer = createKafkaProducer(
"bootstrap.servers", "localhost:9092",
"transactional.id", "my-transactional-id");
KafkaConsumer consumer = createKafkaConsumer(
"bootstrap.servers", "localhost:9092",
"group.id", "my-group-id",
"isolation.level", "read_committed");
consumer.subscribe(singleton("inputTopic"));
producer.initTransactions();
while (true) {
ConsumerRecords records = consumer.poll(Long.MAX_VALUE);
producer.beginTransaction();
for (ConsumerRecord record : records)
producer.send(producerRecord(“outputTopic”, record));
producer.sendOffsetsToTransaction(currentOffsets(consumer), group);
producer.commitTransaction();
}
参考博文:


















 1905
1905

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









