






论文名称:Rethinking Atrous Convolution for Semantic Image Segmentation
1.重新讨论了空洞卷积的使用,使得在串行模块和空间金字塔池化的框架下,能够获取更大的感受野从而获取多尺度信息;
2.改进了ASPP模块:由不同采样率的空洞卷积和BN层组成,尝试以串行或并行的方式布局模块;
3.讨论了一个重要问题:使用大采样率的3×3的空洞卷积,因为图像边界响应无法捕捉远距离信息(小目标),会退化为1×1的卷积, 建议将图像级特征融合到ASPP模块中。
论文下载地址:https://arxiv.org/abs/1706.05587

上图为笔者模型预测效果(由于设备性能原因,训练次数仅为20轮)
参考代码:https://github.com/fregu856/deeplabv3
参考文章:
https://blog.youkuaiyun.com/qq_37541097/article/details/121797301
https://blog.youkuaiyun.com/qq_35759272/article/details/123700919
https://blog.youkuaiyun.com/qq_43492938/article/details/111183906
Cascaded modules
图1(a)未使用空洞卷积,所以图像分辨率一直缩小(信息的丢失非常严重);图1(b) 不改变分辨率以及感受野,其中Block1-4是原始ResNet网络中的层结构,但在Block4中将第一个残差结构里的3x3卷积层以及捷径分支上的1x1卷积层步距stride由2改成了1(即不再进行下采样),并且所有残差结构里3x3的普通卷积层都换成了空洞卷积层。Block5,Block6和Block7是额外新增的层结构,其结构与Block4一致,即由三个残差结构构成。
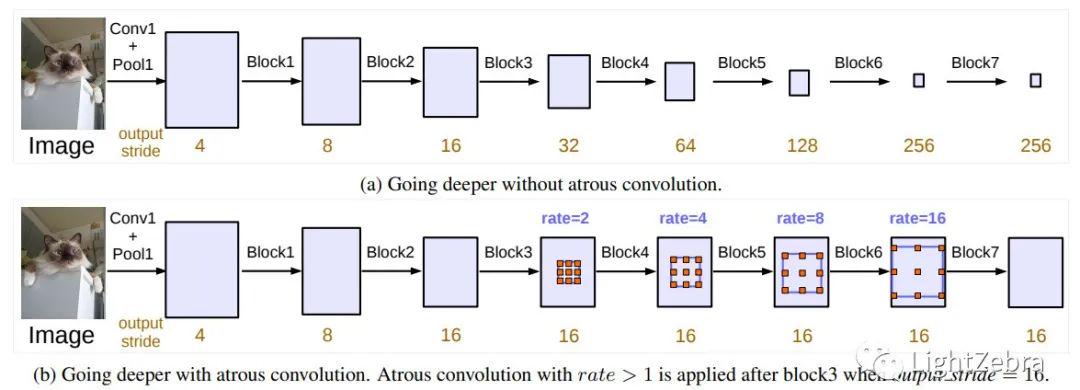
图1 Cascaded modules without and with atrous convolution
2.Atrous Spatial Pyramid Pooling
ASPP可以以不同的rate有效地捕捉多尺度信息,但是随着Block的深入与空洞卷积rate的增大,会导致卷积退化为1x1。例如,对于尺寸为65x65的特征图,如果将3x3、rate=30的空洞卷积核应用于它,生成的特征图会仅有中心点,捕获不到全局信息。为解决此问题,添加了Image-Level 图像级别的特征。具体来讲,将输入特征图的每一个通道做全局平均池化,再通过256个1x1的卷积核构成新的大小为(1, 1, 256)的特征图,再通过双线性插值得到需要的分辨率的图(如(b)所示),这么做可以弥补当rate太大的时候丢失的信息。(a)的部分包括一个1x1和rate分别为6、12、18的3x3的空洞卷积。将(a)和(b)进行concat,然后再通过256个1x1的卷积核得到新的特征图,上采样后进行损失的计算。
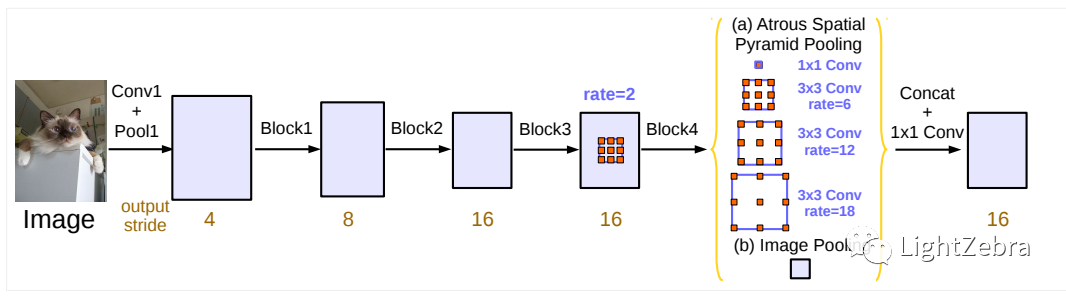
图2 Parallel modules with atrous convolution (ASPP), augmented with image-level features
DeepLab V3中的ASPP结构有5个并行分支(图3中心部分),分别是一个1x1的卷积层,三个3x3的膨胀卷积层,以及一个全局平均池化层(为了增加全局上下文信息global context information),然后通过Concat的方式将这5个分支的输出进行拼接,最后再通过一个1x1的卷积层进一步融合信息。
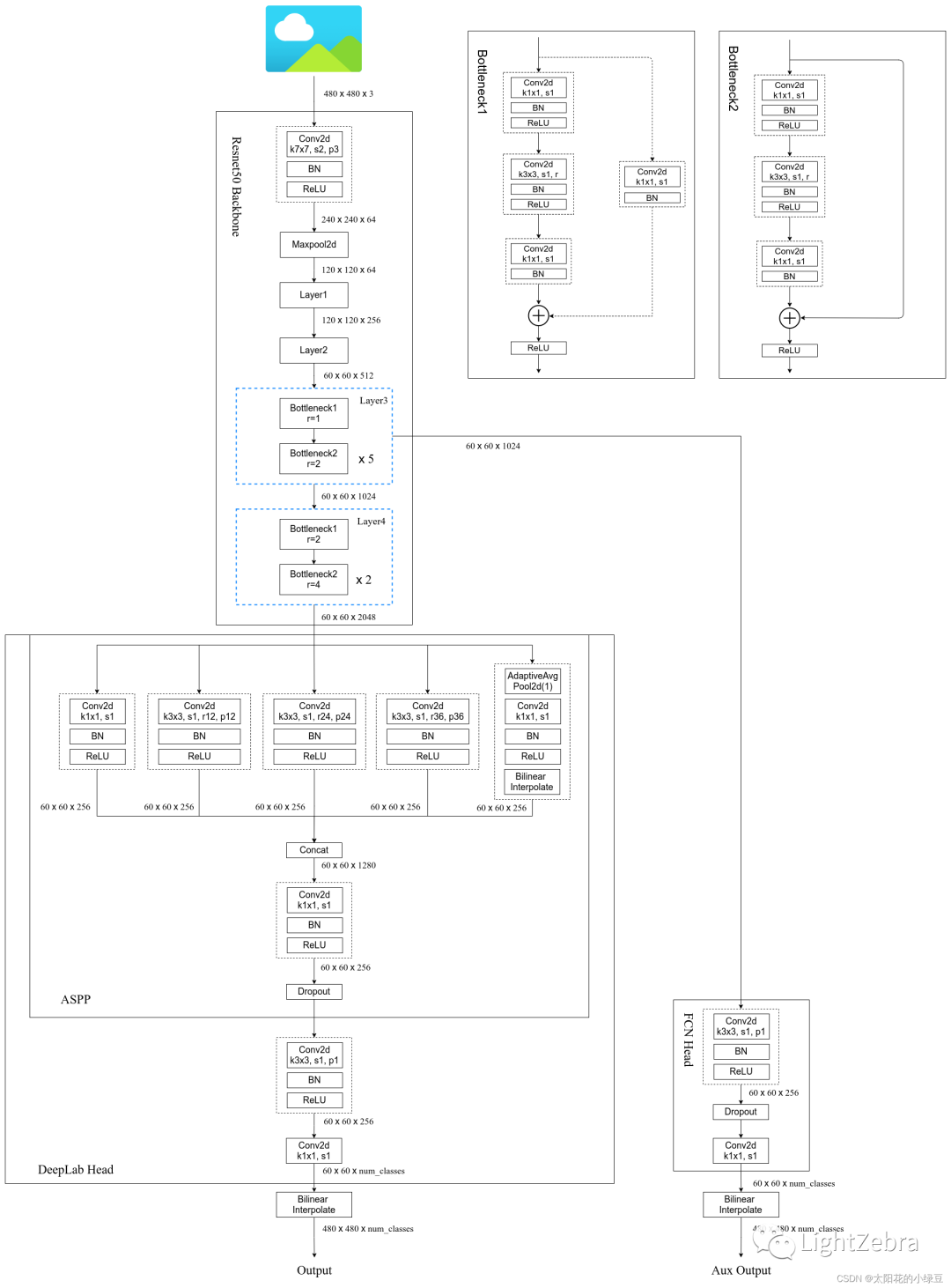
图3 DeepLab V3的网络结构(优快云:太阳花的小绿豆)
Part 1 数据预处理
将cityscapes数据集中gtFine文件中的labelIds.png中的id转换为trainId,并将转换后的文件放置到cityscapes_meta_ path中
# 创建id与trainId相对应的字典:
id_to_trainId = {label.id: label.trainId for label in labels}
# vectorize:将函数向量化,用法:np.vectorize(函数)(待函数处理的数据)
id_to_trainId_map_func = np.vectorize(id_to_trainId.get)
train_dirs = ["jena/", "zurich/", "weimar/", "ulm/", "tubingen/", "stuttgart/",
"strasbourg/", "monchengladbach/", "krefeld/", "hanover/",
"hamburg/", "erfurt/", "dusseldorf/", "darmstadt/", "cologne/",
"bremen/", "bochum/", "aachen/"]
val_dirs = ["frankfurt/", "munster/", "lindau/"]
test_dirs = ["berlin", "bielefeld", "bonn", "leverkusen", "mainz", "munich"]
cityscapes_data_path = "/home/luyx/zk/Cityscapes"
cityscapes_meta_path = "/home/luyx/zk/Cityscapes/meta"
if not os.path.exists(cityscapes_meta_path):
os.makedirs(cityscapes_meta_path)
if not os.path.exists(cityscapes_meta_path + "/label_imgs"):
os.makedirs(cityscapes_meta_path + "/label_imgs")
# 将gtFine中labelIds.png中的id转换为trainId,并将转换后的文件放置到cityscapes_meta_path中
train_label_img_paths = []
img_dir = cityscapes_data_path + "/leftImg8bit/train/"
label_dir = cityscapes_data_path + "/gtFine/train/"
for train_dir in train_dirs:
print (train_dir)
train_img_dir_path = img_dir + train_dir
train_label_dir_path = label_dir + train_dir
file_names = os.listdir(train_img_dir_path)
for file_name in file_names:
# 提取出图像编号:如“aachen_000000_000019”
img_id = file_name.split("_leftImg8bit.png")[0]
# 提取出gtFine中的labelIds.png图像
gtFine_img_path = train_label_dir_path + img_id + "_gtFine_labelIds.png"
gtFine_img = cv2.imread(gtFine_img_path, -1) # (shape: (1024, 2048))
# 使用np.vectorize将id转换为trainId
label_img = id_to_trainId_map_func(gtFine_img) # (shape: (1024, 2048))
label_img = label_img.astype(np.uint8)
cv2.imwrite(cityscapes_meta_path + "/label_imgs/" + img_id + ".png", label_img)
train_label_img_paths.append(cityscapes_meta_path + "/label_imgs/" + img_id + ".png")
img_dir = cityscapes_data_path + "/leftImg8bit/val/"
label_dir = cityscapes_data_path + "/gtFine/val/"
for val_dir in val_dirs:
print (val_dir)
val_img_dir_path = img_dir + val_dir
val_label_dir_path = label_dir + val_dir
file_names = os.listdir(val_img_dir_path)
for file_name in file_names:
img_id = file_name.split("_leftImg8bit.png")[0]
gtFine_img_path = val_label_dir_path + img_id + "_gtFine_labelIds.png"
gtFine_img = cv2.imread(gtFine_img_path, -1) # (shape: (1024, 2048))
label_img = id_to_trainId_map_func(gtFine_img) # (shape: (1024, 2048))
label_img = label_img.astype(np.uint8)
cv2.imwrite(cityscapes_meta_path + "/label_imgs/" + img_id + ".png", label_img)计算类别权重
print ("computing class weights")
# 共有20个类别,trainId为0-19
num_classes = 20
trainId_to_count = {}
for trainId in range(num_classes):
trainId_to_count[trainId] = 0
# 获取每个类别的所有训练label_imgs中的像素总数
for step, label_img_path in enumerate(train_label_img_paths):
if step % 100 == 0:
print (step)
label_img = cv2.imread(label_img_path, -1)
for trainId in range(num_classes):
trainId_mask = np.equal(label_img, trainId)
trainId_count = np.sum(trainId_mask)
trainId_to_count[trainId] += trainId_count
# 根据ENet论文计算类的权重:
class_weights = []
total_count = sum(trainId_to_count.values())
for trainId, count in trainId_to_count.items():
trainId_prob = float(count)/float(total_count)
trainId_weight = 1/np.log(1.02 + trainId_prob)
class_weights.append(trainId_weight)
print (class_weights)
with open(cityscapes_meta_path + "/class_weights.pkl", "wb") as file:
pickle.dump(class_weights, file, protocol=2)图像增强
import torch
import torch.utils.data
import numpy as np
import cv2
import os
train_dirs = ["jena/", "zurich/", "weimar/", "ulm/", "tubingen/", "stuttgart/",
"strasbourg/", "monchengladbach/", "krefeld/", "hanover/",
"hamburg/", "erfurt/", "dusseldorf/", "darmstadt/", "cologne/",
"bremen/", "bochum/", "aachen/"]
val_dirs = ["frankfurt/", "munster/", "lindau/"]
test_dirs = ["berlin", "bielefeld", "bonn", "leverkusen", "mainz", "munich"]
class DatasetTrain(torch.utils.data.Dataset):
def __init__(self, cityscapes_data_path, cityscapes_meta_path):
self.img_dir = cityscapes_data_path + "/leftImg8bit/train/"
self.label_dir = cityscapes_meta_path + "/label_imgs/"
self.img_h = 1024
self.img_w = 2048
self.new_img_h = 512
self.new_img_w = 1024
self.examples = []
for train_dir in train_dirs:
train_img_dir_path = self.img_dir + train_dir
file_names = os.listdir(train_img_dir_path)
for file_name in file_names:
img_id = file_name.split("_leftImg8bit.png")[0]
img_path = train_img_dir_path + file_name
label_img_path = self.label_dir + img_id + ".png"
example = {}
example["img_path"] = img_path
example["label_img_path"] = label_img_path
example["img_id"] = img_id
self.examples.append(example)
self.num_examples = len(self.examples)
def __getitem__(self, index):
example = self.examples[index]
img_path = example["img_path"]
img = cv2.imread(img_path, -1) # (shape: (1024, 2048, 3))
img = cv2.resize(img, (self.new_img_w, self.new_img_h),
interpolation=cv2.INTER_NEAREST) # (shape: (512, 1024, 3))
label_img_path = example["label_img_path"]
label_img = cv2.imread(label_img_path, -1) # (shape: (1024, 2048))
label_img = cv2.resize(label_img, (self.new_img_w, self.new_img_h),
interpolation=cv2.INTER_NEAREST) # (shape: (512, 1024))
# 以0.5的概率翻转img与label:
flip = np.random.randint(low=0, high=2) # 返回一个随机整型数,范围从低(包括)到高(不包括),即[low, high)
if flip == 1:
img = cv2.flip(img, 1)
label_img = cv2.flip(label_img, 1)
scale = np.random.uniform(low=0.7, high=2.0) # 从一个均匀分布[low,high)中随机采样
new_img_h = int(scale*self.new_img_h)
new_img_w = int(scale*self.new_img_w)
img = cv2.resize(img, (new_img_w, new_img_h),
interpolation=cv2.INTER_NEAREST) # (shape: (new_img_h, new_img_w, 3))
label_img = cv2.resize(label_img, (new_img_w, new_img_h),
interpolation=cv2.INTER_NEAREST) # (shape: (new_img_h, new_img_w))
# 从img和label中随机选取一个256*256的裁剪框
start_x = np.random.randint(low=0, high=(new_img_w - 256))
end_x = start_x + 256
start_y = np.random.randint(low=0, high=(new_img_h - 256))
end_y = start_y + 256
img = img[start_y:end_y, start_x:end_x] # (shape: (256, 256, 3))
label_img = label_img[start_y:end_y, start_x:end_x] # (shape: (256, 256))
# 标准化img图像
img = img/255.0
img = img - np.array([0.485, 0.456, 0.406])
img = img/np.array([0.229, 0.224, 0.225]) # (shape: (256, 256, 3))
img = np.transpose(img, (2, 0, 1)) # (shape: (3, 256, 256))
img = img.astype(np.float32)
img = torch.from_numpy(img) # (shape: (3, 256, 256))
label_img = torch.from_numpy(label_img) # (shape: (256, 256))
return (img, label_img)
def __len__(self):
return self.num_examplesPart 2 构建网络
本文中的网络流程与图3类似,但部分不同。输入图像后,首先经过无fully connected layer, avg pool, layer 4与layer 5的resnet18,再经过4个类似图3中的BottleNeck结构(本文中的BottleNeck为2个BN后的3*3卷积与1个BN后的1*1卷积结果相加),经过ASPP层后upsample输出。
import torchvision.models as models
def make_layer(block, in_channels, channels, num_blocks, stride=1, dilation=1):
strides = [stride] + [1]*(num_blocks - 1) # (stride == 2, num_blocks == 4 --> strides == [2, 1, 1, 1])
blocks = []
for stride in strides:
blocks.append(block(in_channels=in_channels, channels=channels, stride=stride, dilation=dilation))
in_channels = block.expansion*channels
layer = nn.Sequential(*blocks) # (*blocks: call with unpacked list entires as arguments)
return layer
class BasicBlock(nn.Module):
expansion = 1
def __init__(self, in_channels, channels, stride=1, dilation=1):
super(BasicBlock, self).__init__()
out_channels = self.expansion*channels
self.conv1 = nn.Conv2d(in_channels, channels, kernel_size=3, stride=stride, padding=dilation, dilation=dilation, bias=False)
self.bn1 = nn.BatchNorm2d(channels)
self.conv2 = nn.Conv2d(channels, channels, kernel_size=3, stride=1, padding=dilation, dilation=dilation, bias=False)
self.bn2 = nn.BatchNorm2d(channels)
if (stride != 1) or (in_channels != out_channels):
conv = nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=stride, bias=False)
bn = nn.BatchNorm2d(out_channels)
self.downsample = nn.Sequential(conv, bn)
else:
self.downsample = nn.Sequential()
def forward(self, x):
# (x has shape: (batch_size, in_channels, h, w))
out = F.relu(self.bn1(self.conv1(x))) # (shape: (batch_size, channels, h, w) if stride == 1, (batch_size, channels, h/2, w/2) if stride == 2)
out = self.bn2(self.conv2(out)) # (shape: (batch_size, channels, h, w) if stride == 1, (batch_size, channels, h/2, w/2) if stride == 2)
out = out + self.downsample(x) # (shape: (batch_size, channels, h, w) if stride == 1, (batch_size, channels, h/2, w/2) if stride == 2)
out = F.relu(out) # (shape: (batch_size, channels, h, w) if stride == 1, (batch_size, channels, h/2, w/2) if stride == 2)
return out
class ResNet_BasicBlock_OS8(nn.Module):
def __init__(self, num_layers):
super(ResNet_BasicBlock_OS8, self).__init__()
if num_layers == 18:
resnet = models.resnet18()
# load pretrained model:
resnet.load_state_dict(torch.load("/home/luyx/zk/Cityscapes/MANYTESTS/DeepLabV3+/deeplabv3-master/deeplabv3-master/pretrained_models/resnet/resnet18-5c106cde.pth"))
# remove fully connected layer, avg pool, layer4 and layer5:
self.resnet = nn.Sequential(*list(resnet.children())[:-4])
num_blocks_layer_4 = 2
num_blocks_layer_5 = 2
print ("pretrained resnet, 18")
self.layer4 = make_layer(BasicBlock, in_channels=128, channels=256, num_blocks=num_blocks_layer_4, stride=1, dilation=2)
self.layer5 = make_layer(BasicBlock, in_channels=256, channels=512, num_blocks=num_blocks_layer_5, stride=1, dilation=4)
def forward(self, x):
# (x has shape (batch_size, 3, h, w))
# pass x through (parts of) the pretrained ResNet:
c3 = self.resnet(x) # (shape: (batch_size, 128, h/8, w/8)) (it's called c3 since 8 == 2^3)
output = self.layer4(c3) # (shape: (batch_size, 256, h/8, w/8))
output = self.layer5(output) # (shape: (batch_size, 512, h/8, w/8))
return outputASPP
class ASPP(nn.Module):
def __init__(self, num_classes):
super(ASPP, self).__init__()
self.conv_1x1_1 = nn.Conv2d(512, 256, kernel_size=1)
self.bn_conv_1x1_1 = nn.BatchNorm2d(256)
self.conv_3x3_1 = nn.Conv2d(512, 256, kernel_size=3, stride=1, padding=6, dilation=6)
self.bn_conv_3x3_1 = nn.BatchNorm2d(256)
self.conv_3x3_2 = nn.Conv2d(512, 256, kernel_size=3, stride=1, padding=12, dilation=12)
self.bn_conv_3x3_2 = nn.BatchNorm2d(256)
self.conv_3x3_3 = nn.Conv2d(512, 256, kernel_size=3, stride=1, padding=18, dilation=18)
self.bn_conv_3x3_3 = nn.BatchNorm2d(256)
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.conv_1x1_2 = nn.Conv2d(512, 256, kernel_size=1)
self.bn_conv_1x1_2 = nn.BatchNorm2d(256)
self.conv_1x1_3 = nn.Conv2d(1280, 256, kernel_size=1) # (1280 = 5*256)
self.bn_conv_1x1_3 = nn.BatchNorm2d(256)
self.conv_1x1_4 = nn.Conv2d(256, num_classes, kernel_size=1)
def forward(self, feature_map):
# (feature_map has shape (batch_size, 512, h/16, w/16)) (assuming self.resnet is ResNet18_OS16 or ResNet34_OS16. If self.resnet instead is ResNet18_OS8 or ResNet34_OS8, it will be (batch_size, 512, h/8, w/8))
feature_map_h = feature_map.size()[2] # (== h/16)
feature_map_w = feature_map.size()[3] # (== w/16)
out_1x1 = F.relu(self.bn_conv_1x1_1(self.conv_1x1_1(feature_map))) # (shape: (batch_size, 256, h/16, w/16))
out_3x3_1 = F.relu(self.bn_conv_3x3_1(self.conv_3x3_1(feature_map))) # (shape: (batch_size, 256, h/16, w/16))
out_3x3_2 = F.relu(self.bn_conv_3x3_2(self.conv_3x3_2(feature_map))) # (shape: (batch_size, 256, h/16, w/16))
out_3x3_3 = F.relu(self.bn_conv_3x3_3(self.conv_3x3_3(feature_map))) # (shape: (batch_size, 256, h/16, w/16))
out_img = self.avg_pool(feature_map) # (shape: (batch_size, 512, 1, 1))
out_img = F.relu(self.bn_conv_1x1_2(self.conv_1x1_2(out_img))) # (shape: (batch_size, 256, 1, 1))
out_img = F.upsample(out_img, size=(feature_map_h, feature_map_w), mode="bilinear") # (shape: (batch_size, 256, h/16, w/16))
out = torch.cat([out_1x1, out_3x3_1, out_3x3_2, out_3x3_3, out_img], 1) # (shape: (batch_size, 1280, h/16, w/16))
out = F.relu(self.bn_conv_1x1_3(self.conv_1x1_3(out))) # (shape: (batch_size, 256, h/16, w/16))
out = self.conv_1x1_4(out) # (shape: (batch_size, num_classes, h/16, w/16))
return outDeeplabv3将上述结构融合
class DeepLabV3(nn.Module):
def __init__(self, model_id, project_dir):
super(DeepLabV3, self).__init__()
self.num_classes = 20
self.model_id = model_id
self.project_dir = project_dir
self.create_model_dirs()
self.resnet = ResNet18_OS8()
self.aspp = ASPP(num_classes=self.num_classes)
def forward(self, x):
# (x has shape (batch_size, 3, h, w))
h = x.size()[2]
w = x.size()[3]
feature_map = self.resnet(x) # (shape: (batch_size, 512, h/8, w/8))
output = self.aspp(feature_map) # (shape: (batch_size, num_classes, h/16, w/16))
output = F.upsample(output, size=(h, w), mode="bilinear") # (shape: (batch_size, num_classes, h, w))
return output
def create_model_dirs(self):
self.logs_dir = self.project_dir + "/training_logs"
self.model_dir = self.logs_dir + "/model_%s" % self.model_id
self.checkpoints_dir = self.model_dir + "/checkpoints"
if not os.path.exists(self.logs_dir):
os.makedirs(self.logs_dir)
if not os.path.exists(self.model_dir):
os.makedirs(self.model_dir)
os.makedirs(self.checkpoints_dir)·未完待续·

















 6936
6936

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









