







 超级会员免费看
超级会员免费看
 SadTalker AI模型结合图片和音频,能自动生成人物说话的3D运动视频。它通过ExpNet和PoseVAE学习音频与面部表情、头部姿势的对应关系。模型支持英语和中文,可在本地或Google Colab上运行,需要Python 3.8以上、预训练模型及相关库。合成的视频可保存,同时提供选项保留完整人体图片。
SadTalker AI模型结合图片和音频,能自动生成人物说话的3D运动视频。它通过ExpNet和PoseVAE学习音频与面部表情、头部姿势的对应关系。模型支持英语和中文,可在本地或Google Colab上运行,需要Python 3.8以上、预训练模型及相关库。合成的视频可保存,同时提供选项保留完整人体图片。

SadTalker模型是一个使用图片与音频文件自动合成人物说话动画的开源模型,我们自己给模型一张图片以及一段音频文件,模型会根据音频文件把传递的图片进行人脸的相应动作,比如张嘴,眨眼,移动头部等动作。
SadTalker,它从音频中生成 3DMM 的 3D 运动系数(头部姿势、表情),并隐式调制一种新颖的 3D 感知面部渲染,用于生成说话的头部运动视频。
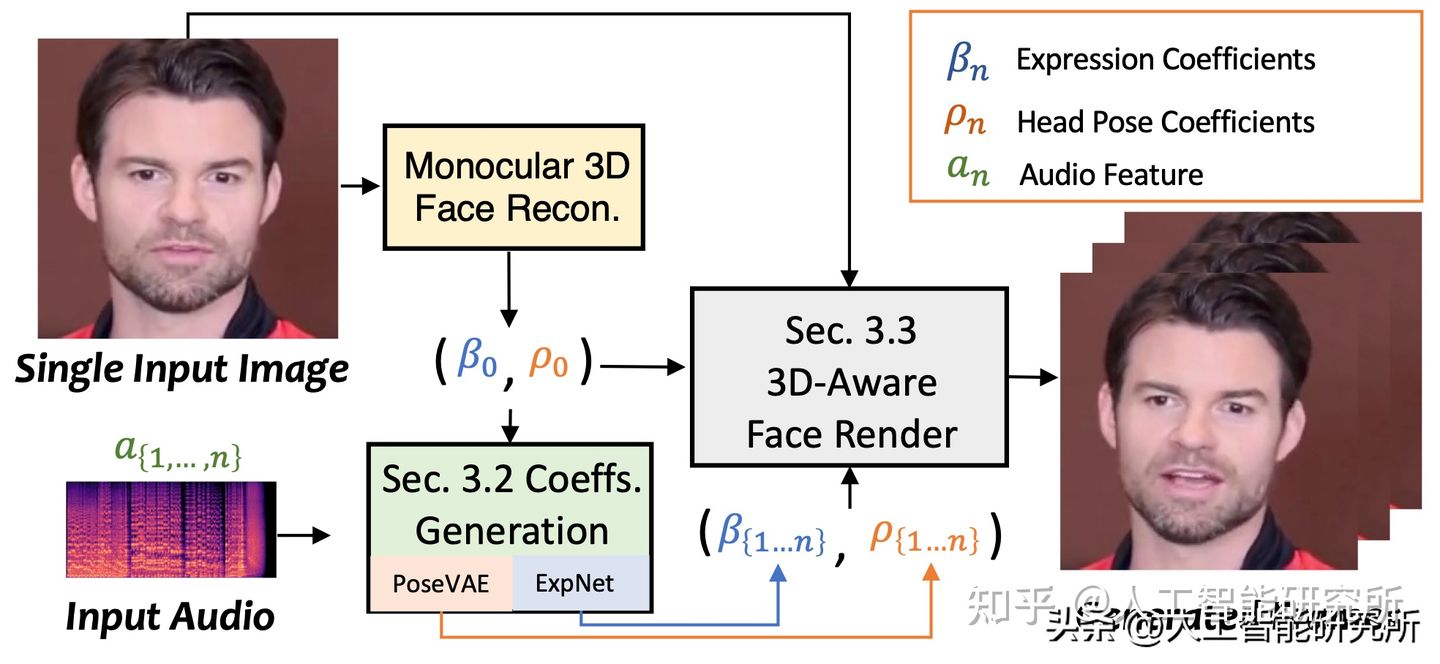
为了学习真实的运动,SadTalker分别对音频和不同类型的运动系数之间的联系进行显式建模。 准确地说,SadTalker提出 ExpNet模型,通过提取运动系数和3D渲染的面部运动来从音频中学习准确的面部表情。 至于头部姿势,SadTalker通过PoseVAE 以合成不同风格的头部运动。
模型不仅支持英文,还支持中文,我们可以直接hugging face上面来体验
https://huggingface.co/spaces/vinth
 订阅专栏 解锁全文
订阅专栏 解锁全文



















 977
977

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











