




 本文介绍了SadTalker的安装过程,包括ffmpeg的下载与配置,以及如何在WebUI上安装插件。详细解释了参数设置,如选择合适的源图片、音频输入、图像预处理方法和面部增强选项,以实现自然的面部语音合成视频。
本文介绍了SadTalker的安装过程,包括ffmpeg的下载与配置,以及如何在WebUI上安装插件。详细解释了参数设置,如选择合适的源图片、音频输入、图像预处理方法和面部增强选项,以实现自然的面部语音合成视频。
SadTalker可以根据一张图片、一段音频,合成面部说这段语音的视频。图片需要真人或者接近真人。
安装ffmpeg
下载地址:
下载ffmpeg-git-full.7z 后解压,将解压后的目录\bin添加到环境变量的Path中。
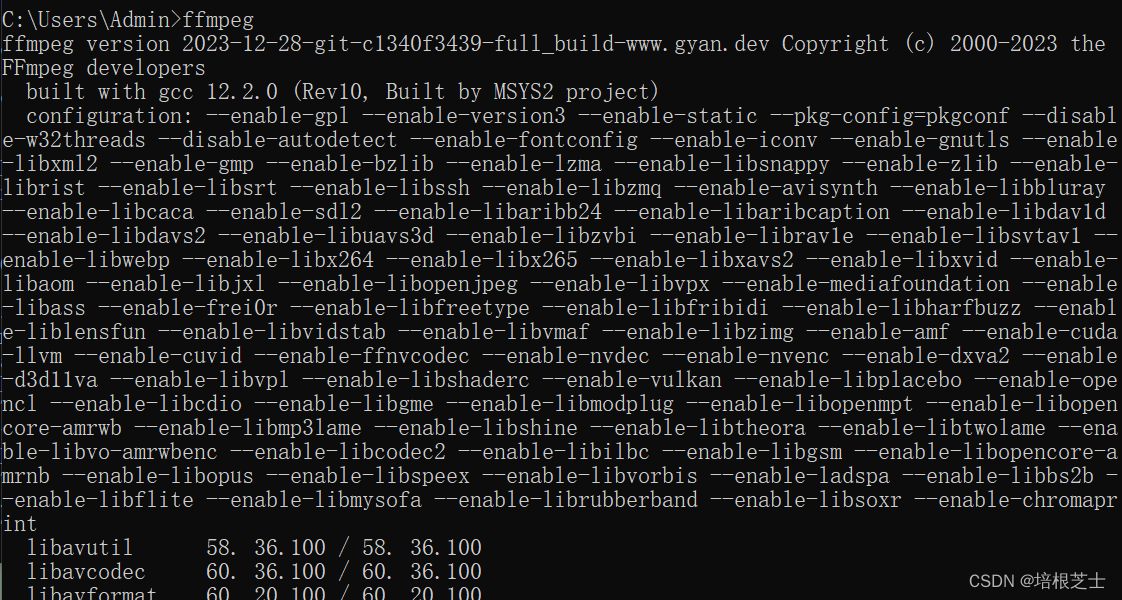
在终端输入ffmpeg命令,查看ffmpeg是否安装成功。
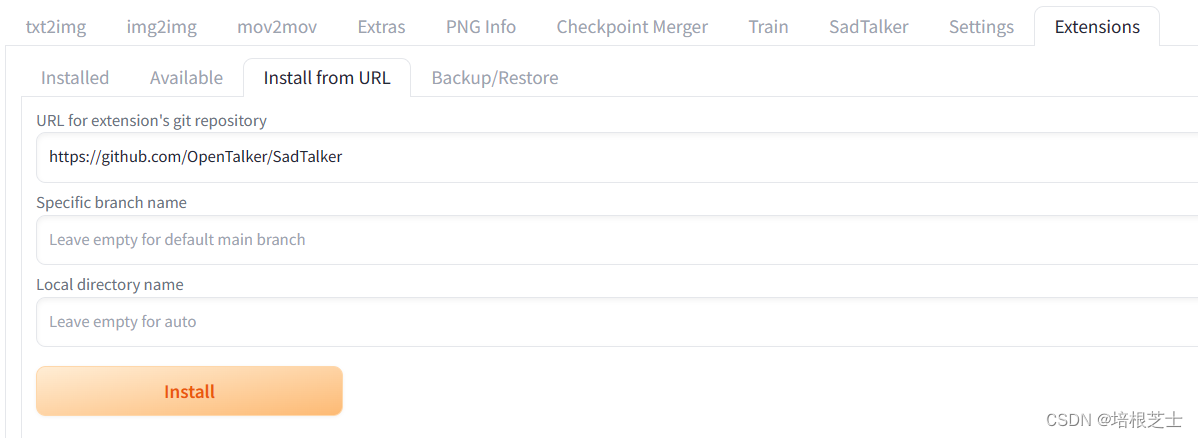
安装SadTalker插件
在WebUI的extensions选项卡下,使用“Install from URL”安装SadTalker插件。
插件地址:
下载checkpoint
下载地址:
将下载下来的checkpoint放入stable-diffusion-webui/extensions/SadTalker/checkpoints/目录下。
使用SadTalker
重新启动WebUI,可以看到多出来一个SadTalker选项卡。
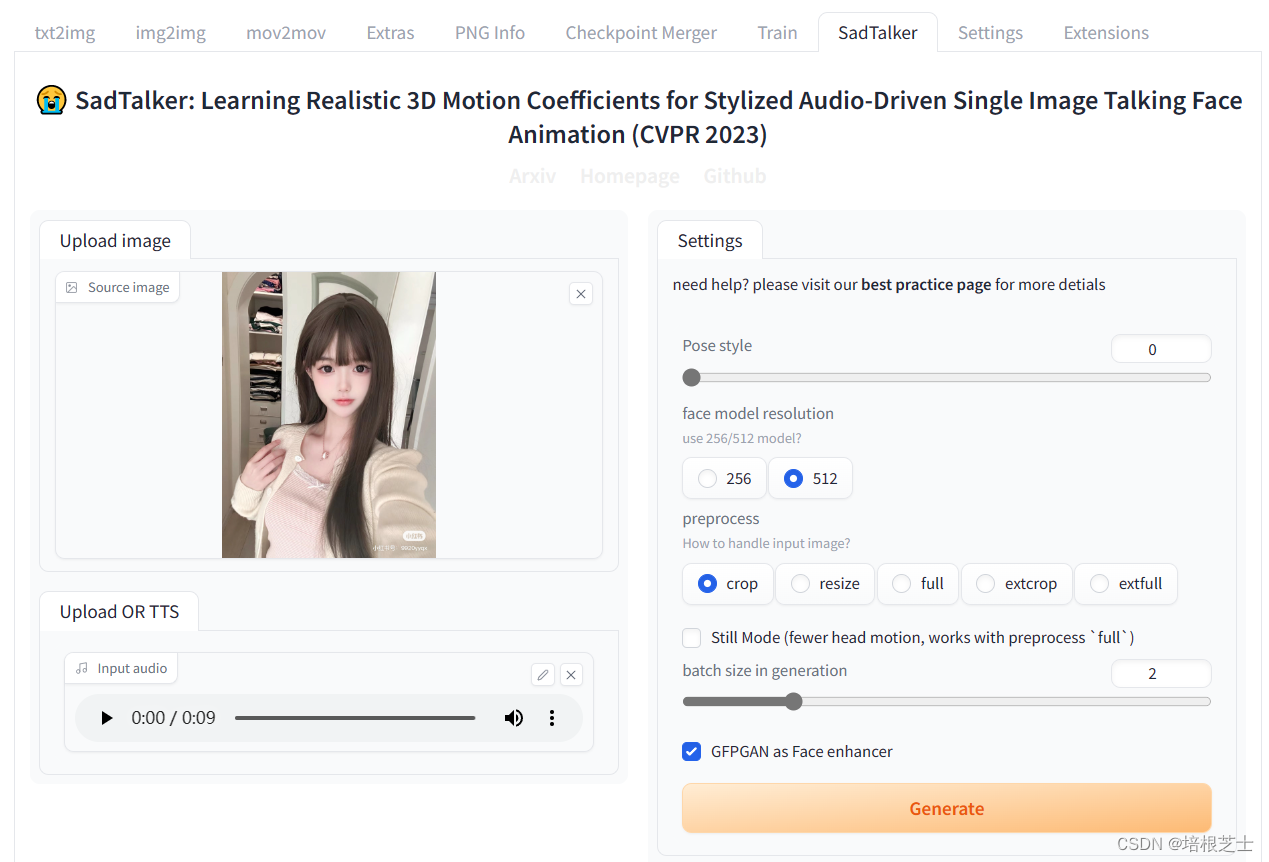
参数说明:
- Source image,原始图片,最好是大头,不然会显得不自然
- Input audio,输入音频,使用SadTalker示例的音频测试(\extensions\SadTalker\examples\driven_audio)
- preprocess,图像预处理方式,crop(剪裁), resize(重置大小), full(原图),其中crop根据面部关键点生成的表情和动画相对逼真,前提是不要全图,看起来会很怪
- Still Mode (fewer head motion, works with preprocess `full`),使用与原始图像相同的姿势,减少头部运动。这个选项在full(原图)的时候很有必要,优化人物头部运动,生成的视频更加自然。
- GFPGAN as Face enhancer,勾选上, 可以获得更好的面部质量



















 1258
1258

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









