







Circuits -->Sequential Logic -->Finite State Machines
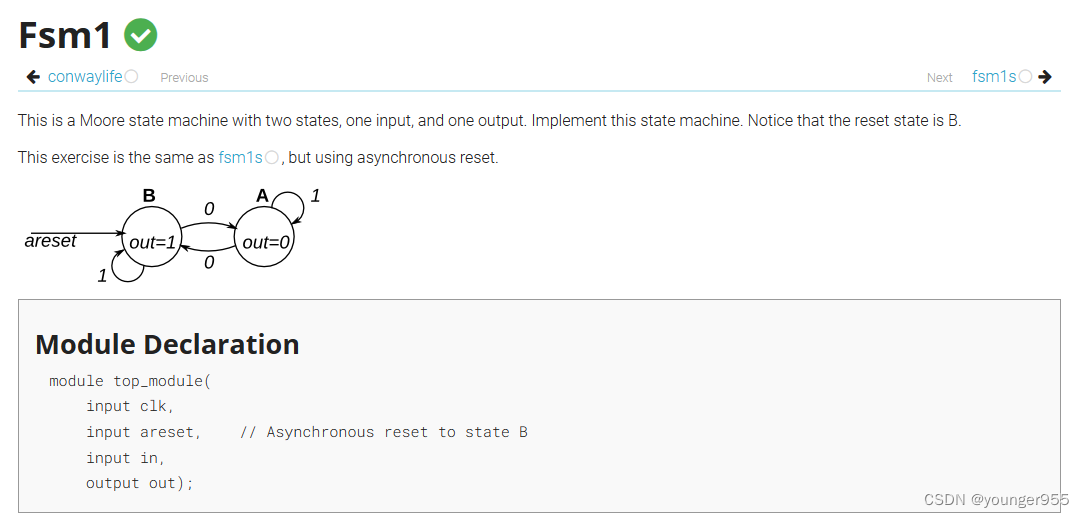
module top_module (
input clk,
input in,
input areset,
output out
);
// Give state names and assignments. I'm lazy, so I like to use decimal numbers.
// It doesn't really matter what assignment is used, as long as they're unique.
parameter A=0, B=1;
reg state; // Ensure state and next are big enough to hold the state encoding.
reg next;
// A finite state machine is usually coded in three parts:
// State transition logic
// State flip-flops
// Output logic
// It is sometimes possible to combine one or more of these blobs of code
// together, but be careful: Some blobs are combinational circuits, while some
// are clocked (DFFs).
// Combinational always block for state transition logic. Given the current state and inputs,
// what should be next state be?
// Combinational always block: Use blocking assignments.
always@(*) begin
case (state)
A: next = in ? A : B;
B: next = in ? B : A;
endcase
end
// Edge-triggered always block (DFFs) for state flip-flops. Asynchronous reset.
always @(posedge clk, posedge areset) begin
if (areset) state <= B; // Reset to state B
else state <= next; // Otherwise, cause the state to transition
end
// Combinational output logic. In this problem, an assign statement is the simplest.
// In more complex circuits, a combinational always block may be more suitable.
assign out = (state==B);
endmodule
(这里不是自己写的,自己写的没保存找不到了)
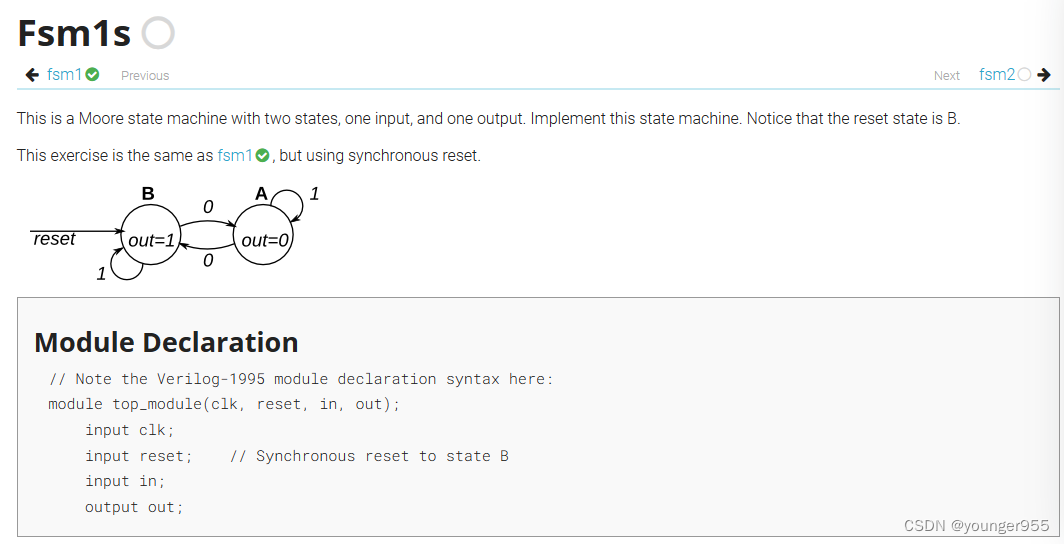
// Note the Verilog-1995 module declaration syntax here:
module top_module(clk, reset, in, out);
input clk;
input reset; // Synchronous reset to state B
input in;
output out;//
reg out;
// Fill in state name declarations
localparam A=1'b0,B=1'b1;
reg present_state, next_state;
always @(posedge clk) begin
if (reset) begin
// Fill in reset logic
present_state <= B;
end
else
// State flip-flops
present_state = next_state;
end
always @(*) begin
case (present_state)
// Fill in state transition logic
A: next_state <= in?A:B;
B: next_state <= in?B:A;
endcase
end
always @(posedge clk or posedge reset) begin
case (present_state)
// Fill in output logic
A: out=1'b0;
B: out=1'b1;
endcase
end
endmodule
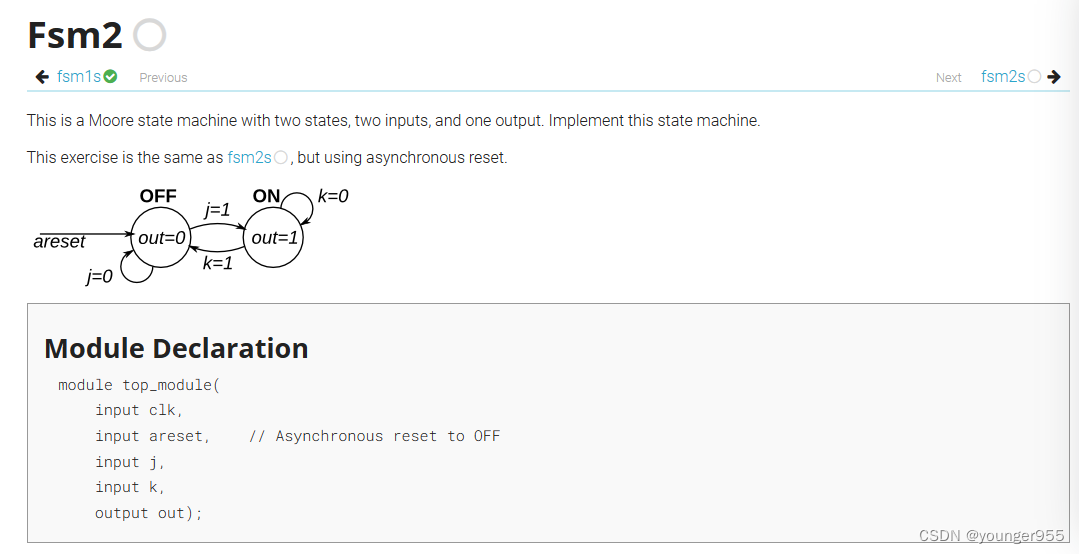
module top_module(
input clk,
input areset, // Asynchronous reset to OFF
input j,
input k,
output out); //
parameter OFF=0, ON=1;
reg state, next_state;
always@(posedge clk, posedge areset)begin
if(areset)
state<=OFF;
else
state<=next_state;
end
always @(*) begin
// State transition logic
case(state)
ON: next_state=k?OFF:ON;
OFF: next_state=j?ON:OFF;
default:next_state=0;
endcase
end
always @(posedge clk, posedge areset) begin
// State flip-flops with asynchronous reset
if(areset)
out<=OFF;
else
case(next_state)
ON: out<=1;
OFF: out<=0;
default:next_state=0;
endcase
end
// Output logic
// assign out = (state == ...);
endmodule
这里always里面的电平敏感 always@(posedge clk, posedge areset)和上一个always@(posedge clk)结果不一样,应该是同步复位和异步复位的区别导致的
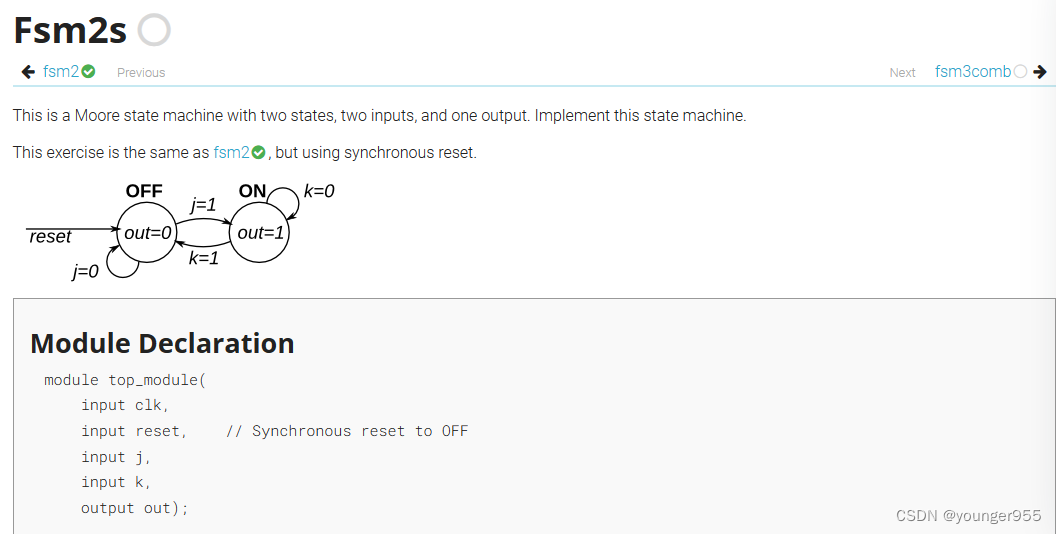
module top_module(
input clk,
input reset, // Synchronous reset to OFF
input j,
input k,
output out); //
parameter OFF=0, ON=1;
reg state, next_state;
always@(posedge clk)begin
if(reset)
state<=OFF;
else
state<=next_state;
end
always @(*) begin
// State transition logic
case(state)
ON: next_state=k?OFF:ON;
OFF: next_state=j?ON:OFF;
default:next_state=0;
endcase
end
always @(posedge clk) begin
// State flip-flops with asynchronous reset
if(reset)
out<=OFF;
else
case(next_state)
ON: out<=1;
OFF: out<=0;
default:next_state=0;
endcase
end
// Output logic
// assign out = (state == ...);
endmodule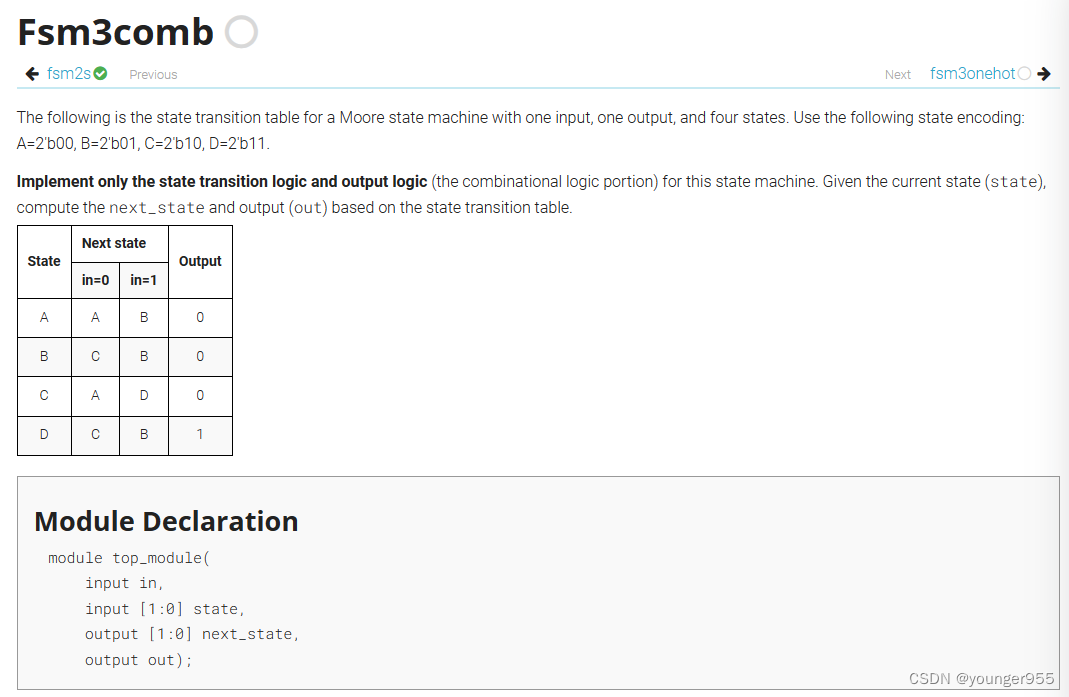
module top_module(
input in,
input [1:0] state,
output [1:0] next_state,
output out); //
parameter A=2'b00, B=2'b01, C=2'b10, D=2'b11;
always @(*)begin
case(state)
A:begin
if(in)
next_state=B;
else
next_state=A;
end
B:begin
if(in)
next_state=B;
else
next_state=C;
end
C:begin
if(in)
next_state=D;
else
next_state=A;
end
D:begin
if(in)
next_state=B;
else
next_state=C;
end
default:next_state=A;
endcase
end
// State transition logic: next_state = f(state, in 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









