







 本文详细介绍了Apache Flink中的关键转换算子,包括map、flatMap、filter、keyBy、rolling aggregation、reduce、split/select、connect/coMap、union等,通过示例展示了如何使用这些算子处理和分析数据流。
本文详细介绍了Apache Flink中的关键转换算子,包括map、flatMap、filter、keyBy、rolling aggregation、reduce、split/select、connect/coMap、union等,通过示例展示了如何使用这些算子处理和分析数据流。
Flink 之 Transform转换算子
文章目录
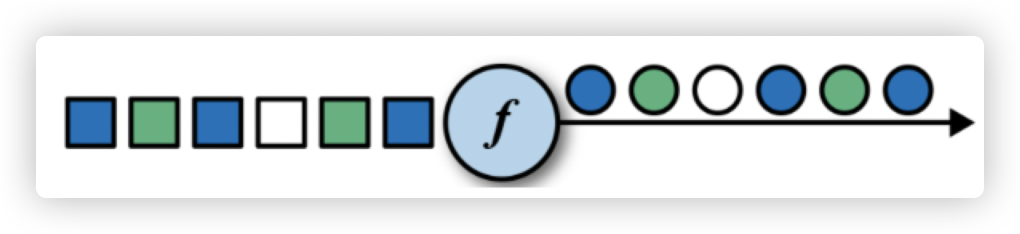
1. map
-
作用: 对输入元素进行映射转换。
-
示例:
import org.apache.flink.streaming.api.scala.{DataStream, StreamExecutionEnvironment} import org.apache.flink.api.scala._ object TestMap { def main(args: Array[String]): Unit = { // 创建执行环境 val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment // 创建输入的 DateStream val input: DataStream[Int] = env.fromElements[Int](1,2,3,4) // 使用 map 对输入进行处理,得到结果 val output: DataStream[Int] = input.map(data => data + 1) // 输出结果 output.print() // 2 3 4 5 // 执行任务 env.execute() } }
2. flatMap
-
作用: 与
map(func)类似,但是每一个输入可以被映射成0或多个输出元素。 -
示例:
import org.apache.flink.streaming.api.scala.{DataStream, StreamExecutionEnvironment} import org.apache.flink.api.scala._ object TestFlatMap { def main(args: Array[String]): Unit = { // 创建运行环境 val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment // 创建DS输入 val input: DataStream[String] = env.fromCollection(List("a b", "c d")) // 通过 flatMap 对数据进行切割 val output: DataStream[String] = input.flatMap(strs => strs.split(" ")) // 将结果输出 output.print() // a b c d // 执行任务 env.execute() } }
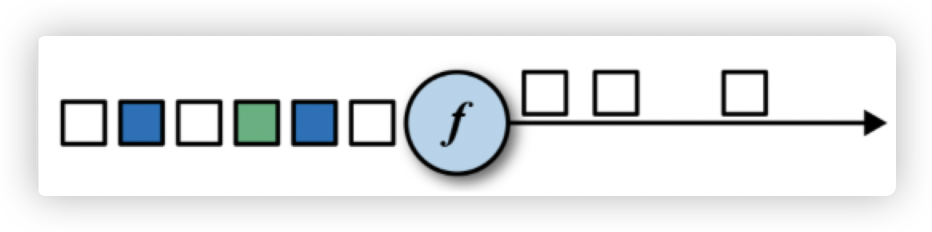
3. filter
-
作用: 过滤数据。
-
示例:
import org.apache.flink.streaming.api.scala.{DataStream, StreamExecutionEnvironment} import org.apache.flink.api.scala._ object TestFilter { def main(args: Array[String]): Unit = { // 创建运行环境 val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment // 创建 DS 输入 val input: DataStream[String] = env.fromElements("xiaohong","xiaoming","mingming","xiaozhang") // 过滤掉不含 "xiao" 的字符串 val output: DataStream[String] = input.filter(_.contains("xiao")) // 输出结果 output.print() // 执行任务 env.execute() } }
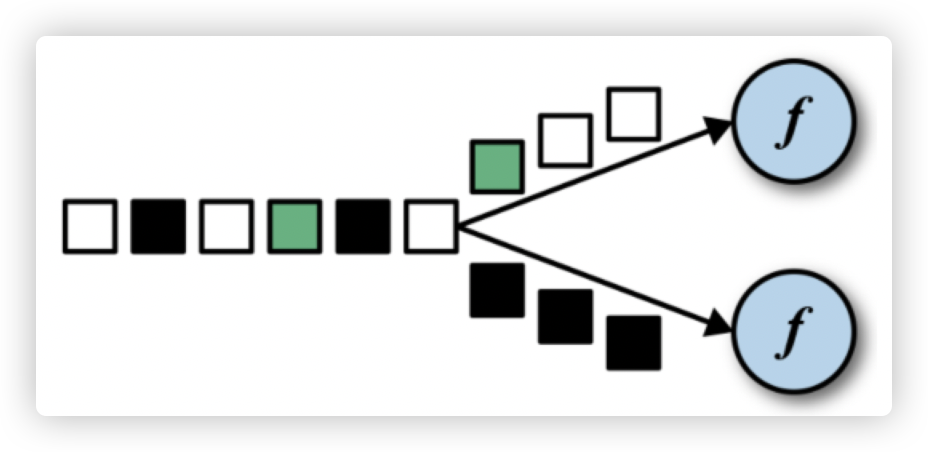
4. keyBy
-
作用:
DataStream → KeyedStream逻辑地将一个流拆分成不相交的分区,每个分区包含具有相同key的元素,在内部以hash的形式实现的。 -
示例:
import org.apache.flink.api.java.tuple.Tuple import org.apache.flink.api.scala._ import org.apache.flink.streaming.api.scala.{DataStream, KeyedStream, StreamExecutionEnvironment} object TestKeyBy { def main(args: Array[String]): Unit = { // 创建执行环境 val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment // 创建 DS val input: DataStream[(Int, String)] = env.fromElements(Tuple2(1,"a"), Tuple2(2,"b"), Tuple2(3,"c"), Tuple2(2,"a")) // 根据元组的第一个元素分流 val output: KeyedStream[(Int, String), Tuple] = input.keyBy(0) // 输出结果 output.print() // 执行任务 env.execute() } } -
注意: 以下类型无法作为
key。POJO 类(Java简单对象) 且 没有实现hashCode函数。- 任意形式的数组类型。
5. 滚动聚合算子(Rolling Aggregation)
- 这些算子可以针对
keyedStream的每一个支流做聚合。sum()min()max()minBy()maxBy()
6. reduce
-
作用:
KeyedStream → DataStream:一个分组数据流的聚合操作,合并当前的元素和上次聚合的结果,产生一个新的值,返回的流中包含每一次聚合的结果,而不是只返回最后一次聚合的最终结果。 -
示例:
val textPath = "/Users/zgl/Documents/IdeaProjects/FlinkTutorial/src/sensors.txt" val input: DataStream[String] = env.readTextFile(textPath) val output: DataStream[SensorReading] = input.map(line => { val fields = line.split(",") SensorReading(fields(0).trim, fields(1).trim.toLong, fields(2).trim.toDouble) }) .keyBy("id") .reduce((x, y) => SensorReading(x.id, x.timestamp+1, y.temperature))
7. split 和 select
7.1 split
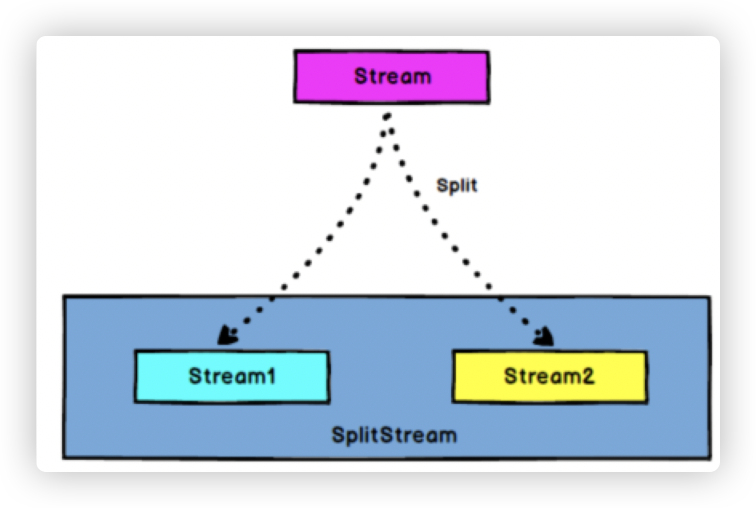
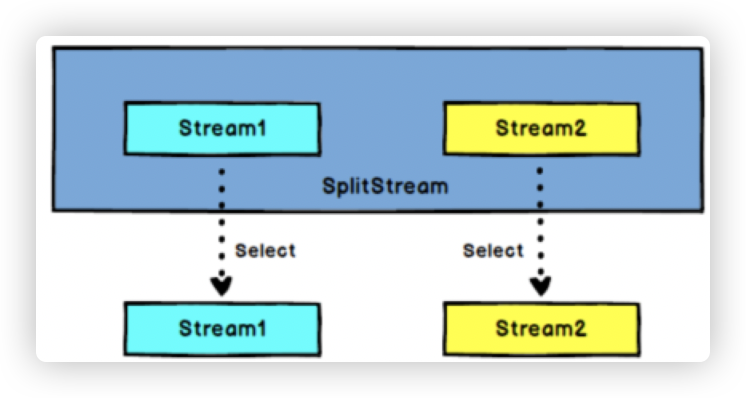
- 作用:
DataStream → SplitStream:根据某些特征把一个DataStream拆分成两个或者多个DataStream。
7.2 select
-
作用:
SplitStream→DataStream:从一个SplitStream中获取一个或者多个DataStream。 -
示例:
import com.guli.source.SensorReading import org.apache.flink.api.scala._ import org.apache.flink.streaming.api.scala.{DataStream, SplitStream, StreamExecutionEnvironment} object TestSplit_Select { def main(args: Array[String]): Unit = { val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment val input: DataStream[SensorReading] = env.fromCollection(List( SensorReading("sensor_1", 1547718199, 35.80018327300259), SensorReading("sensor_6", 1547718201, 15.402984393403084), SensorReading("sensor_7", 1547718202, 6.720945201171228), SensorReading("sensor_10", 1547718205, 38.101067604893444) )) val splitStream: SplitStream[SensorReading] = input.split( sensorData => if (sensorData.temperature > 30) Seq("high") else Seq("low")) val highStream: DataStream[SensorReading] = splitStream.select("high") val lowStream: DataStream[SensorReading] = splitStream.select("low") val allStream: DataStream[SensorReading] = splitStream.select("high", "low") highStream.print() //lowStream.print() //allStream.print() env.execute() } }
8. connect 和 coMap
8.1 connect
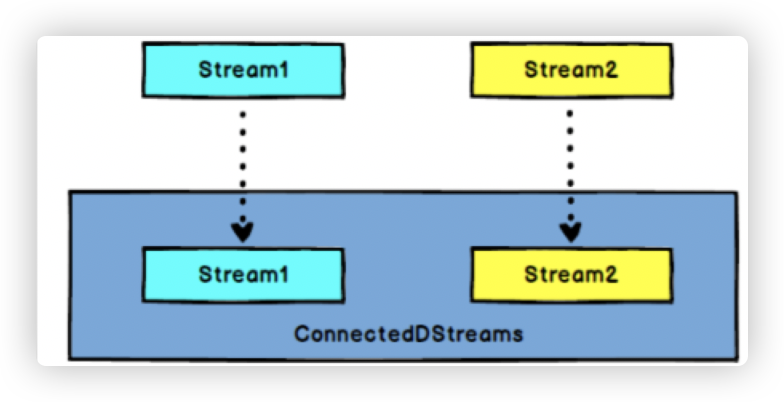
- 作用:
DataStream,DataStream → ConnectedStreams:连接两个保持他们类型的数据流,两个数据流被Connect之后,只是被放在了一个同一个流中,内部依然保持各自的数据和形式不发生任何变化,两个流相互独立。
8.2 coMap 、 coFlatMap
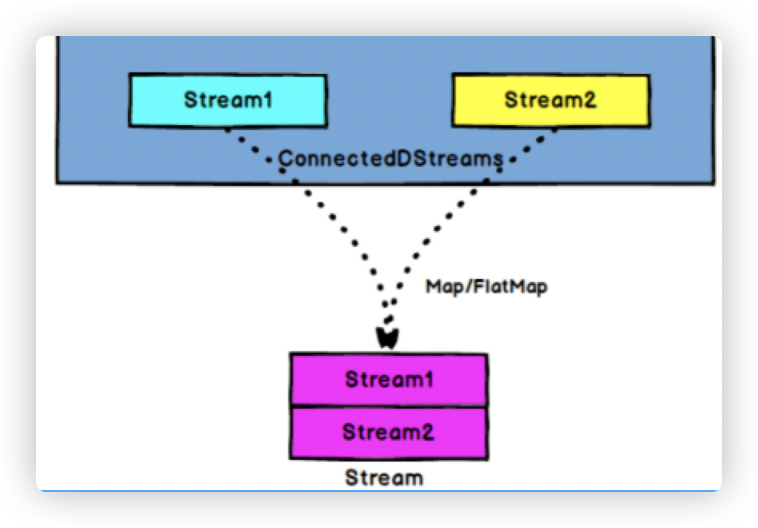
-
作用:
ConnectedStreams → DataStream:作用于ConnectedStreams上,功能与map和flatMap一样,对ConnectedStreams中的每一个Stream分别进行map和flatMap处理。 -
示例:
val warning = highStream.map( sensorData => (sensorData.id, sensorData.temperature) ) val connected = warning.connect(lowStream) val coMap = connected.map(warningData => (warningData._1, warningData._2, "warning"), lowData => (lowData.id, "healthy") )
9. union
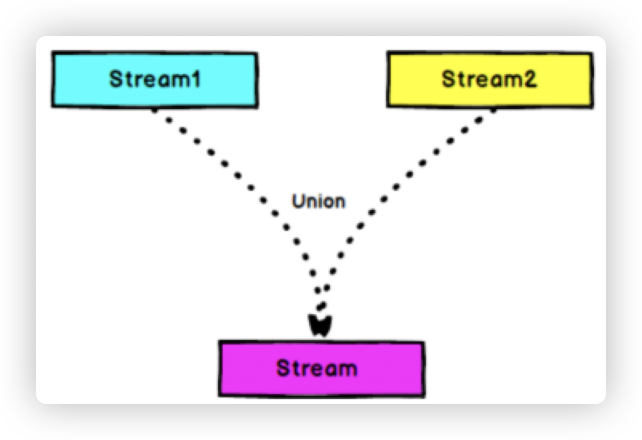
-
** 作用: **
DataStream → DataStream:对两个或者两个以上的DataStream进行union操作,产生一个包含所有DataStream元素的新DataStream。 -
示例:
//合并以后打印 val unionStream: DataStream[StartUpLog] = appStoreStream.union(otherStream) unionStream.print("union:::")
10. connect 和 union 的区别
-
Union之前两个流的类型必须是一样,Connect可以不一样,在之后的coMap中再去调整成为一样的。 -
Connect只能操作两个流,Union可以操作多个。

















 3366
3366

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









