






 本文详细介绍了VGG-16神经网络模型,包括其分块结构、卷积层与池化操作的特点,以及如何通过Dropout和ReLU防止过拟合。此外,文中还展示了模型的训练过程,包括权重初始化和使用FashionMNIST数据集进行训练的方法。
本文详细介绍了VGG-16神经网络模型,包括其分块结构、卷积层与池化操作的特点,以及如何通过Dropout和ReLU防止过拟合。此外,文中还展示了模型的训练过程,包括权重初始化和使用FashionMNIST数据集进行训练的方法。
VGG模型于2014年诞生于Visual Geometry Group 实验室,是ILSVRC 2014的亚军。应用广泛,可以作为如目标检测,实例分割等骨架。通常说的VGG是VGG-16(13层卷积+3层全链接)。接下来均已VGG-16D为例子。
下面完整代码从:GitHub - wangy-w/VGG-16-Study-Notes
VGG-16D网络结构
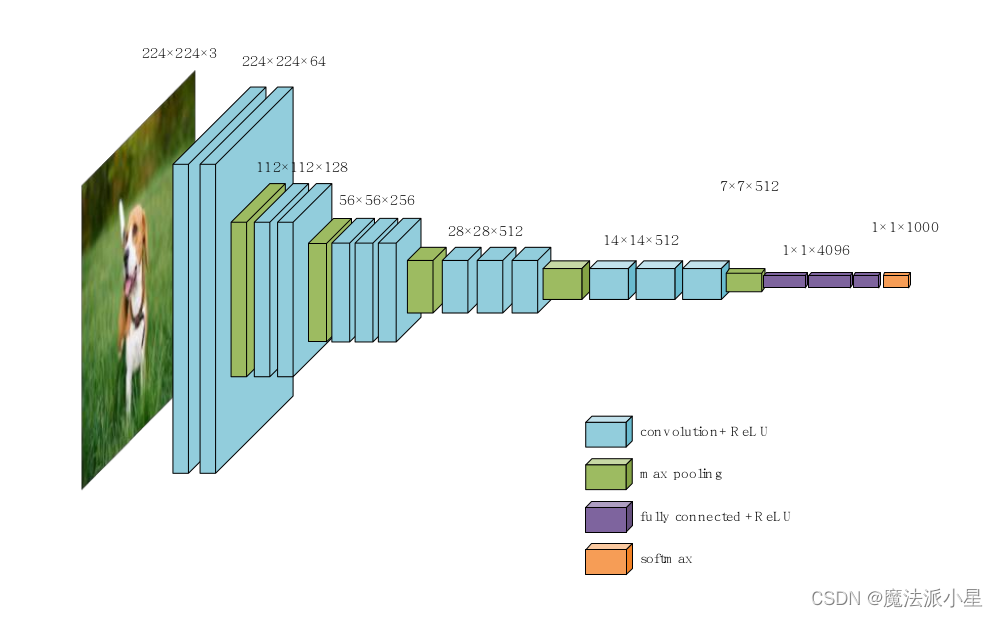
VGG-16D的网络特点:
1.VGG的网络结构是分块的,每一个块内的卷积层结构是相同的。每一块的卷积是用来增加特征的,使得通道数上升。每一块的输入输出尺寸是保持一致的。
2.池化操作采用最大池化操作。池化是用来修改特征图的表现,如平滑等等。在池化的过程中,通道数是保持不变的,但特征图的分辨率是缩小的。在VGG-16池化操作将特征图的尺寸缩小了一半。
3.采用较小尺寸的卷积核,在每一块都是3*3。
5个VGG BLOCK保持输入输出一致的秘密:
输入与输出特征图之间分辨率的关系:
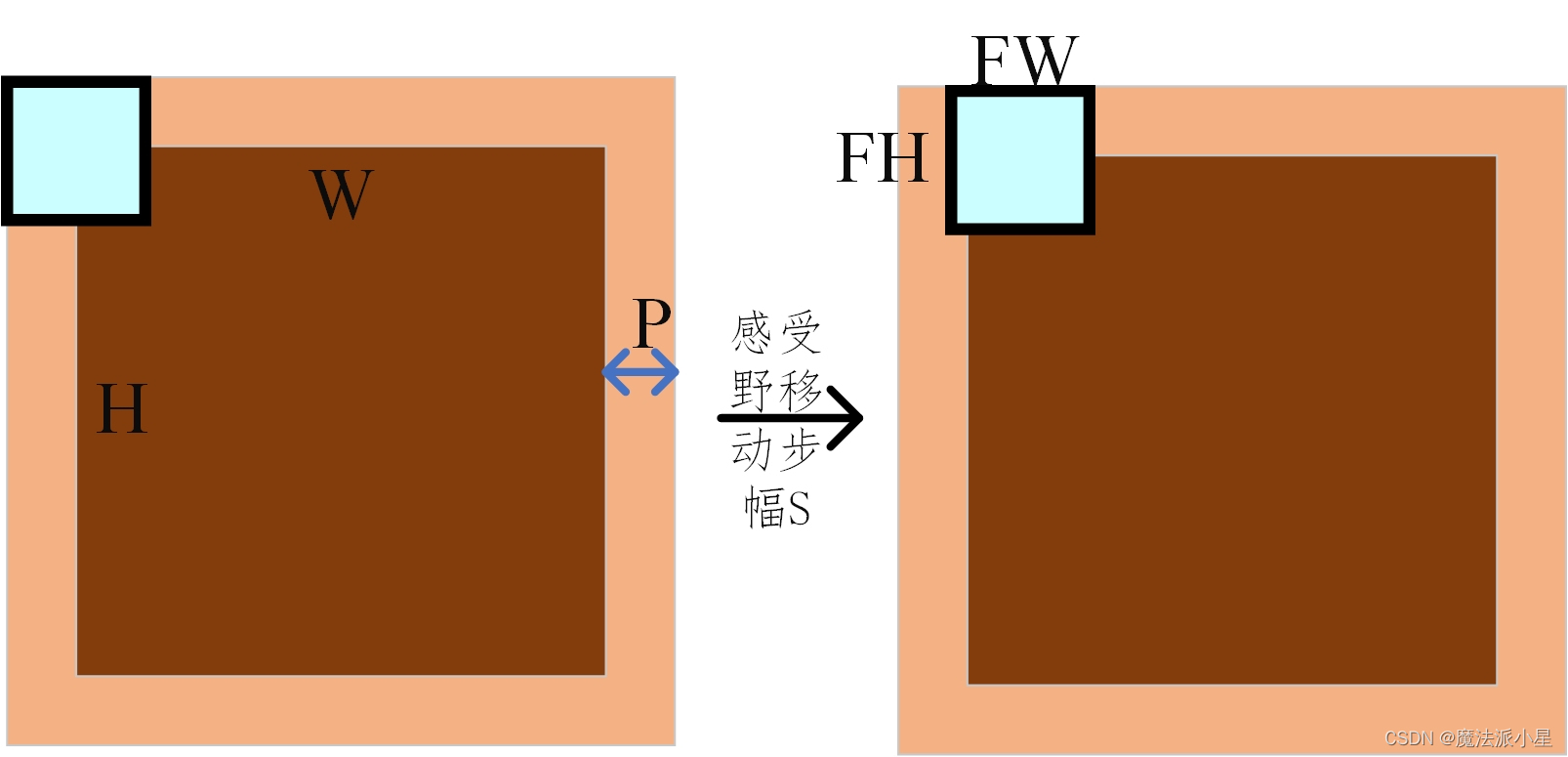
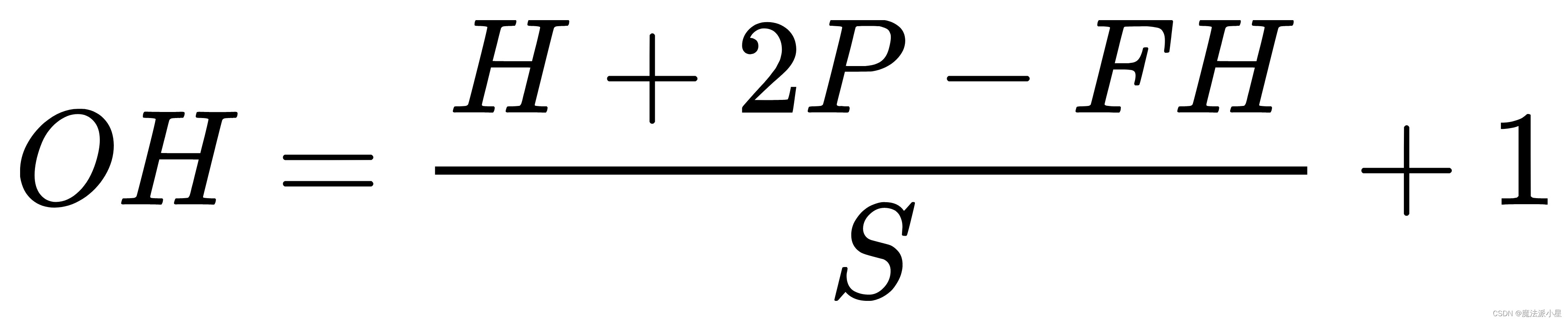
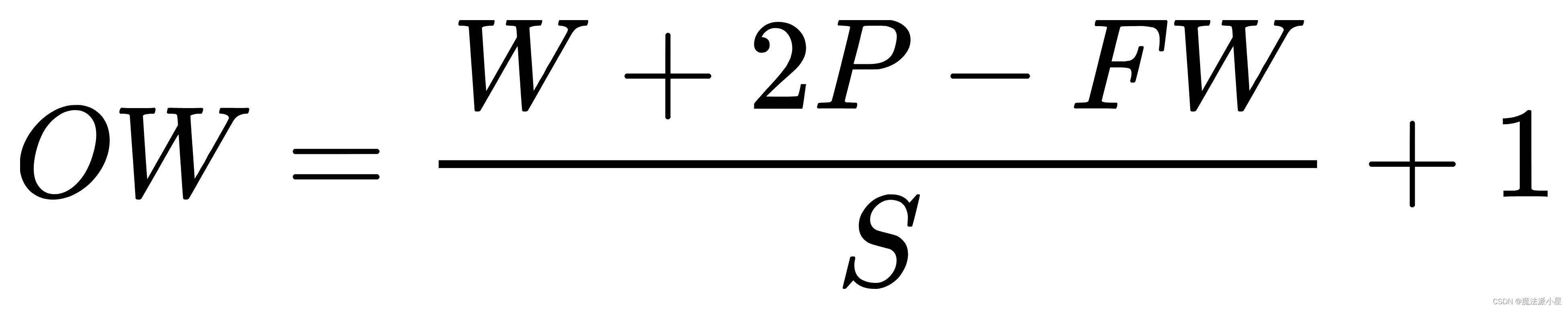
H,W分别为输入特征图高与宽;OH,OW分别为输出特征图高与宽;FH与FW分别为卷积核或者池化感受野的高与宽;P是输入特征图的填充值;S为卷积核与特征图进行卷积时移动的步长。
在卷积块中卷积核 3*3,保证每一次卷积核与特征图卷积移动的步长为1,输入特征图的填充为2。
在池化块中池化感受野2*2,保证每一次池化与特征图卷积移动的步长为2,输入特征图的填充为0。
全链接层的输入:
经过上面的一系列卷积与池化等操作,我们需要对特征图进行展平的操作,将他送入到全链接网络当中,按照网络结构和上面的公式可以计算出输入全连接层的特征图7 * 7 * 512,展平后变成类似于一列25088个参数向量,送入全连接层。
全连接层:
共有三层,神经元个数分别是4096,4096,1000。为了防止过拟合,在前两层使用Dropout的操作,随机失活一些神经元。除此之外,在前两层还使用了ReLU。最后一层使用softmax输出1000个分类。
输出通道数:
输出通道数只与卷积核的数量有关,和输入的通道数量没有关系。
比如输入(20,20,3)这是一张三通道的图,经过一次卷积生成一个(20,20,64),说明有64个(3,3,3)的卷积核对其进行操作。
训练:
权重初始化,以解决训练不收敛。有时添加权重初始化操作也不行,考虑修改batch_size的大小。
模型代码:
import torch
from torch import nn
from torchsummary import summary #torchsummary可以打印网络结构和参数
'''
首先模型初始化
建立正向传播的过程
VGG网络是按照块进行搭建的
'''
class VGG16(nn.Module):
def __init__(self):
super(VGG16,self).__init__()
'''
in_channels:输入特征图通道数
out_channels:输出特征图尺寸
kernel_size:卷积核或者池化感受野的尺寸
padding:填充的尺寸
stride:步长
'''
#Sequential()允许按顺序添加各种神经网络层,如第一块有两个卷积层还有一个池化 将这些添加到这里面
self.block1 = nn.Sequential(
#我采用的数据集是灰度图,所以输入通道数量是1。在Conv2d中默认填充padding = 0,步长stride = 1。
nn.Conv2d(in_channels=1,out_channels=64,kernel_size=3,padding=1),
nn.ReLU(),
nn.Conv2d(in_channels=64,out_channels=64,kernel_size=3,padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2,stride=2)
)
self.block2 = nn.Sequential(
nn.Conv2d(in_channels=64,out_channels=128,kernel_size=3,padding=1),
nn.ReLU(),
nn.Conv2d(in_channels=128,out_channels=128,kernel_size=3,padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2,stride=2)
)
self.block3 = nn.Sequential(
nn.Conv2d(in_channels=128,out_channels=256,kernel_size=3,padding=1),
nn.ReLU(),
nn.Conv2d(in_channels=256,out_channels=256,kernel_size=3,padding=1),
nn.ReLU(),
nn.Conv2d(in_channels=256,out_channels=256,kernel_size=3,padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2,stride=2)
)
self.block4 = nn.Sequential(
nn.Conv2d(in_channels=256,out_channels=512,kernel_size=3,padding=1),
nn.ReLU(),
nn.Conv2d(in_channels=512,out_channels=512,kernel_size=3,padding=1),
nn.ReLU(),
nn.Conv2d(in_channels=512,out_channels=512,kernel_size=3,padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2,stride=2)
)
self.block5 = nn.Sequential(
nn.Conv2d(in_channels=512,out_channels=512,kernel_size=3,padding=1),
nn.ReLU(),
nn.Conv2d(in_channels=512,out_channels=512,kernel_size=3,padding=1),
nn.ReLU(),
nn.Conv2d(in_channels=512,out_channels=512,kernel_size=3,padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2,stride=2)
)
#全连接层中的操作
'''
线性全连接层
in_features:输入参数
out_features:输出参数(该层神经元的个数)
'''
self.block6= nn.Sequential(
#平展操作
nn.Flatten(),
nn.Linear(in_features=7*7*512,out_features=4096),
nn.ReLU(),
#随机失活一些神经元
nn.Dropout(p=0.5),
nn.Linear(in_features=4096,out_features=4096),
nn.ReLU(),
nn.Dropout(p=0.5),
#针对于我的数据集是做是个分类,输出定为10
nn.Linear(in_features=4096,out_features=10)
)
#权重初始化,防止不收敛
#权重初始化,防止不收敛 对卷积神经网络和全链接网络要有不同的权重初始化方法
#同时批次也是很重要的,有时候批次小了,也不收敛
for m in self.modules():
'''
isinstance(object, classinfo)
object:要检查的对象。
classinfo:类名(可以是单个类或类的元组)。
'''
if isinstance(m,nn.Conv2d):
#凯明初始化 ,卷积初始化w
nn.init.kaiming_normal_(m.weight,nonlinearity='relu')
if m.bias is not None:
#将偏置指定为0
nn.init.constant_(m.bias,0)
elif isinstance(m,nn.Linear):
#采用正太分布初始化 均值为0,方差0.01
nn.init.normal_(m.weight,0,0.01)
if m.bias is not None:
#将偏置指定为0
nn.init.constant_(m.bias,0)
#定义前向传播过程
def forward(self,x):
x = self.block1(x)
x = self.block2(x)
x = self.block3(x)
x = self.block4(x)
x = self.block5(x)
x = self.block6(x)
return x
#该部分仅仅为了验证网络搭建的没问题
if __name__ == "__main__":
#定义一个设备
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
#print(device)
model = VGG16().to(device)#对于上面的类的实例化 并且放到设备里面
#显示一下模型每一层的参数数量
print(summary(model,input_size=(1,224,224)))训练代码:
from torchvision.datasets import FashionMNIST
from torchvision import transforms
import torch.utils.data as Data
import torch
from torch import nn
import numpy as np
import matplotlib.pyplot as plt
from model import VGG16
import copy
import time
import pandas as pd
#在训练部分使用FashionMNIST数据集,里面是一堆服装
def train_val_data_process():
train_data = FashionMNIST(root='./data',
train=True,
transform=transforms.Compose([transforms.Resize(size = 224),transforms.ToTensor()]),
download=True
)
train_data,val_data = Data.random_split(train_data,[round(0.8*len(train_data)),round(0.2*len(train_data))])
train_dataloader =Data.DataLoader(dataset = train_data,
batch_size = 32,
shuffle = True,
num_workers= 2,
)
val_dataloader =Data.DataLoader(dataset = val_data,
batch_size = 32,
shuffle = True,
num_workers= 2,
)
return train_dataloader,val_dataloader
def train_model_process(model,train_dataloader,val_dataloader,num_epochs):
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
optimizer = torch.optim.Adam(model.parameters(),lr = 0.001) #定义优化器,基于梯度下降法的优化器 更新参数
criterion = nn.CrossEntropyLoss()#交叉熵损失函数,在分类里面。在回归模型中,使用均方差
model = model.to(device)#模型放入训练设备当中
best_model_wts = copy.deepcopy(model.state_dict())
#初始化参数
best_acc = 0.0#最高准确度
train_loss_all = []#训练集损失值列表
val_loss_all = []#验证集损失值列表
train_acc_all = []#训练集准确度列表
val_acc_all = []#验证集准确度列表
since = time.time()
for epoch in range(num_epochs):
print("Epoch {}/{}".format(epoch,num_epochs -1))
print("-"*10)
'''
初始化损失值与准确度
需要train_num 计算本轮所有图片计算出的损失值与准确度的平均值
'''
train_loss = 0.0
train_corrects =0
val_loss = 0.0
val_corrects =0
#训练集与验证集的样本数量
train_num = 0
val_num=0
#b_y是标签
for step,(b_x,b_y) in enumerate(train_dataloader):
b_x = b_x.to(device)
b_y =b_y.to(device)
#设置模型为训练模式
model.train()
output = model(b_x)#前向传播 输入一个batch 输出为一个batch 其是一个32行的10列的向量 多少行取决数据定义一捆里面有多少张
pre_lab = torch.argmax(output,dim = 1)#取十个输出的最大索引 dim表示不同维度。特别的在dim=0表示二维矩阵中的列,dim=1在二维矩阵中的行 生成一个128维的列向量
loss = criterion(output,b_y) #用到每一个标签的概率
#将梯度复位为零
optimizer.zero_grad()
#反响传播计算
loss.backward()
#更新网络参数
optimizer.step()
#对损失值的累加,loss.item()单个样本的平均损失值
train_loss += loss.item()*b_x.size(0)
train_corrects += torch.sum(pre_lab == b_y.data)
train_num += b_x.size(0)
'''
验证集合没有方向传播的过程
'''
for step,(b_x,b_y) in enumerate(val_dataloader):
b_x =b_x.to(device)
b_y = b_y.to(device)
output = model(b_x)
pre_lab = torch.argmax(output,dim = 1)
loss = criterion(output,b_y)
val_loss += loss.item()*b_x.size(0)
val_corrects += torch.sum(pre_lab == b_y.data)
val_num += b_x.size(0)
#train_loss / train_num 一个轮次的平均loss值
train_loss_all.append(train_loss / train_num)
val_loss_all.append(val_loss / val_num)
train_acc_all.append(train_corrects.double().item() / train_num)
val_acc_all.append(val_corrects.double().item() / val_num)
print('{} Train Loss: {:.4f} Train Acc{:.4f}'.format(epoch,train_loss_all[-1],train_acc_all[-1]))
print('{} Val Loss: {:.4f} Val Acc{:.4f}'.format(epoch,val_loss_all[-1],val_acc_all[-1]))
#训练的再好也是有答案的学习,在验证集上表现好,才是真的好参数
if val_loss_all[-1] > best_acc:
#保存最高准确度
best_acc = val_loss_all[-1]
#保存最好参数
best_model_wts = copy.deepcopy(model.state_dict())
use_time = time.time() - since
print("训练和验证耗费的时间:{:.0f}min{:.0f}s".format(use_time //60,use_time%60))
#选择最优参数,保存最优参数的模型model.load_state_dict(best_model_wts)
torch.save(model.state_dict(best_model_wts),'best_model.pth')
#或者这个代码改编成 torch.save(best_model_wts,'best_model.pth')
#可以用dataframe格式保存这些数据epoch,训练损失值,验证集损失值,训练精度,验证损失值
train_process = pd.DataFrame(data = {"epoch":range(num_epochs),
"train_loss_all":train_loss_all,
"val_loss_all":val_loss_all,
"train_acc_all":train_acc_all,
"val_acc_all":val_acc_all})
return train_process
def matplot_acc_loss(train_process):
plt.figure(figsize=(12,4))
plt.subplot(1,2,1)
#'-ro'表示节点用圆圈表示 红色的;'-bs'表示节点用方块表示,蓝色。
plt.plot(train_process["epoch"],train_process.train_loss_all,'ro-',label = "train loss")
plt.plot(train_process["epoch"],train_process.val_loss_all,'bs-',label = "val loss")
plt.legend()
plt.xlabel("epoch")
plt.ylabel("loss")
plt.subplot(1, 2, 2)
plt.plot(train_process["epoch"],train_process.train_acc_all,'ro-',label = "train acc")
plt.plot(train_process["epoch"],train_process.val_acc_all,'bs-',label = "val acc")
plt.legend()
plt.xlabel("epoch")
plt.ylabel("acc")
plt.show()
if __name__ == "__main__":
#将模型实例化
VGG = VGG16()
#加载数据集
train_dataloader,val_dataloader = train_val_data_process()
train_process = train_model_process(VGG,train_dataloader,val_dataloader,20)
matplot_acc_loss(train_process)

















 4155
4155

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









