







整体流程
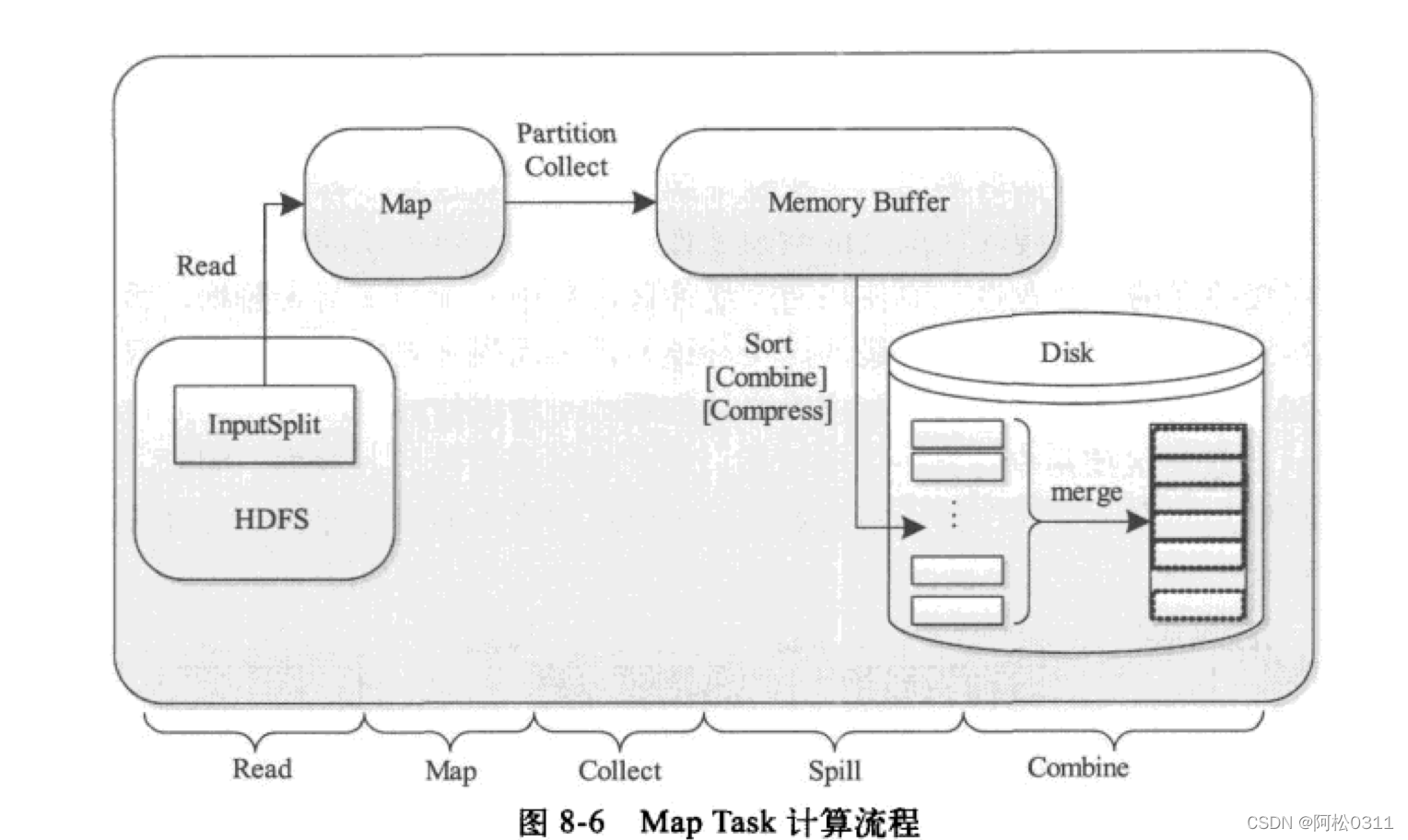
五个阶段
- Read阶段:Map Task通过用户编写的RecordReader,从输入InputSplit中解析出一个个key/value
- Map阶段:该阶段主要是将解析出的key/value交给用户编写的map()函数处理,并产生一系列新的key/value
- collect阶段:在用户编写的map()函数中,当数据处理完成后,会调用OutputCollectior.collect()输出结果,该函数会将生成的key/value分片(调用Pattitioner),并写入一个环形缓冲区中
- Spill阶段:”溢写“,当环形缓冲区满后, 将数据落盘,生成一个临时文件,落盘之前会对数据进行一次本地排序,在必要时对数据进行合并、压缩等操作
- Combine阶段:将临时文件进行合并,确保最终生成一个数据文件
Map Task最重要的部分是输出结果在内存和磁盘中的组织方式,具体设计Collect、Spill、Combine三个阶段。
Collect过程
跟一下源码
进入Map Task的run方法:
@Override
public void run(final JobConf job, final TaskUmbilicalProtocol umbilical)
throws IOException, ClassNotFoundException, InterruptedException {
this.umbilical = umbilical;
if (isMapTask()) {
// If there are no reducers then there won't be any sort. Hence the map
// phase will govern the entire attempt's progress.
//判断是否有reduce task,如果没有,就不需要sort
if (conf.getNumReduceTasks() == 0) {
mapPhase = getProgress().addPhase("map", 1.0f);
} else {
// If there are reducers then the entire attempt's progress will be
// split between the map phase (67%) and the sort phase (33%).
mapPhase = getProgress().addPhase("map", 0.667f);
sortPhase = getProgress().addPhase("sort", 0.333f);
}
}
//report参数
TaskReporter reporter = startReporter(umbilical);
//是否使用新api
boolean useNewApi = job.getUseNewMapper();
initialize(job, getJobID(), reporter, useNewApi);
// check if it is a cleanupJobTask
if (jobCleanup) {
runJobCleanupTask(umbilical, reporter);
return;
}
if (jobSetup) {
runJobSetupTask(umbilical, reporter);
return;
}
if (taskCleanup) {
runTaskCleanupTask(umbilical, reporter 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 350
350

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









