







 本文介绍了在Python中处理包含中文的json数据时如何读写文件和替换中文字段。重点讲解了使用json.dumps和json.loads的方法,以及在处理中文字段时需要注意的编码问题。
本文介绍了在Python中处理包含中文的json数据时如何读写文件和替换中文字段。重点讲解了使用json.dumps和json.loads的方法,以及在处理中文字段时需要注意的编码问题。
在做项目的过程中,有时候我们需要用json文件来直观的反应某种隐射关系。
json的数据结构类似于词典(dict)
这里总结下最近在写入json的过程中遇到的问题:
1.读写文件
json的主要方法有两种json.dumps和json.loads。详细说明可阅读这篇文章(https://www.cnblogs.com/bigberg/p/6430095.html)
这里我们定义一个名为data的词典(dict)
data = {'132070106': {'1005': '112', '1054': '147'}, '1132070101': {'1003': '106', '1006': '105'}}(1)通过dumps命令可以将其转换成字符串
dat1 = json.dumps(data)
type(dat1)
#输出格式是str这里我们查看一下转化后的dat1的格式,可见所有的key和value都被双引号注明(这里一定要区别于单引号)
'{"132070106": {"1005": "112", "1054": "147"}, "1132070101": {"1003": "106", "1006": "105"}}'(2)写入文件res.json,其中indent = 4可以在结果中自动转换成json格式,结果如下图
with open('res.json', 'w') as f:
json.dump(data, f,indent=4)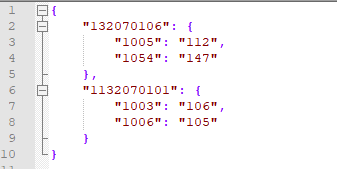
(3)如果我们想把字符串格再转化为dict,需要用到json.loads
dat2 = json.loads(dat1)输出结果和data一致
{'1132070101': {'1003': '106', '1006': '105'},
'132070106': {'1005': '112', '1054': '147'}}2.替换中文字段
在实际项目中为便于处理,我们一般会用某个中文字段的code或id来进行分析,然而最终向产品经理导出结果的时候却需要将code(或者id)转换成中文,便于阅读。
(1)替换中文
例如,这里我们把data转换成str后,并将key替换为中文
dat3 = str(data).replace('1132070101','南京').replace('132070106','徐州')
dat3
#输出结果为
"{'徐州': {'1005': '112', '1054': '147'}, '南京': {'1003': '106', '1006': '105'}}"(2)处理报错
这时如果我再把dat3转换为dict会提示出错,报错提示:期待的字段名称应该包裹在双引号中,不是单引号
json.loads(dat3)
JSONDecodeError: Expecting property name enclosed in double quotes: line 1 column 2 (char 1)这里我们可以联系上面1(1)中dat1的结果,因此为了可以在替换成中文字段后继续转换为词典,有必要将单引号替换为双引号。
dat4 = str(dat3).replace("'", '"')
dat4
#dat4的结果为
'{"徐州": {"1005": "112", "1054": "147"}, "南京": {"1003": "106", "1006": "105"}}'再次尝试转换为词典
dat5 = json.loads(dat4)
dat5
#dat5的输出结果,格式dict
{'南京': {'1003': '106', '1006': '105'}, '徐州': {'1005': '112', '1054': '147'}}(3)写入中文json文件
由于json中有中文,所以需要注明编码格式encoding及ensure_ascii
with open('result.json', 'w',encoding='utf-8') as f:
json.dump(dat5, f,ensure_ascii=False,indent = 4)最终结果如下
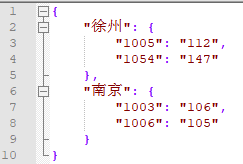
写入成功

















 3611
3611

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









