







前言
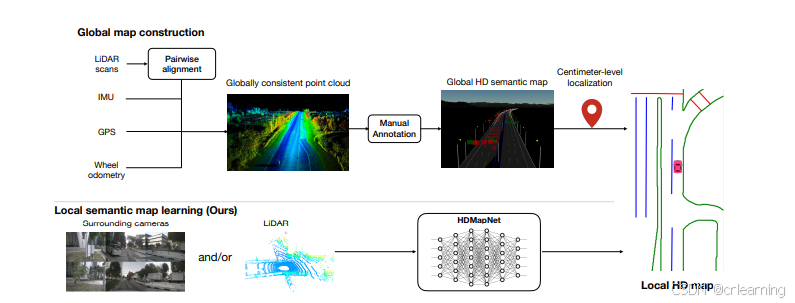
在自动驾驶技术领域,高清地图(HD Map)作为感知和规划的重要基础,其构建往往需要大量人工数据采集和标注,效率低下且难以实时更新。而 HDMapNet 则提出了一种全新的解决方案——通过端到端的神经网络直接从传感器数据(摄像头图像和激光雷达点云)中预测矢量化的地图元素,实现在线动态构建高清地图。本文将从模型原理、模块设计、有效性及性能表现等方面对 HDMapNet 进行详细解析。
1. 什么是 HDMapNet?
HDMapNet 是一个在线高清地图构建模型,其核心思想在于利用深度神经网络从多模态传感器数据中直接预测鸟瞰视角(BEV)下的地图元素,如车道线、道路边界和人行横道等。传统方法大多依赖栅格化表示和繁琐的手工标注,而 HDMapNet 则采用矢量化的地图表示,既节省存储又便于下游任务的处理,从而大幅提升了实时性和精度。
2. 模型架构与各模块详解
HDMapNet 的整体架构可以分为以下几个主要模块,各模块协同工作,共同完成从传感器数据到矢量化地图的转换任务。
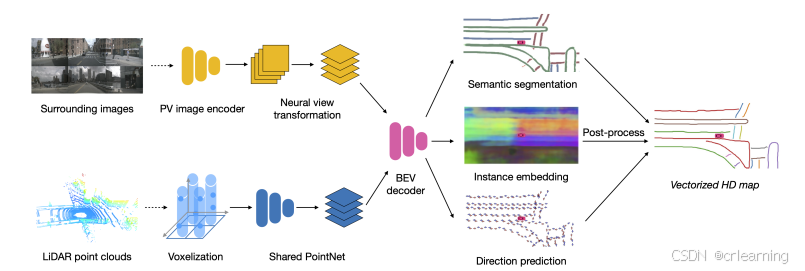
2.1 图像编码器
-
功能:
从多摄像头采集的图像中提取丰富的语义特征,形成透视视角下的特征图,用于后续融合特征。 -
实现方式:
采用卷积神经网络(Resnet)对图像进行深度特征提取,保证后续处理时信息的充分表达。
2.2 神经视图转换器
-
功能:
将图像编码器提取的透视视角特征转换为鸟瞰视角的表示,这是构建高清地图的关键一步。 -
实现方式:
利用神经网络自动学习视角转换过程,结合几何投影和特征变换,有效实现从摄像头视角到 BEV 视角的映射。(BEVFormer,LSS)
2.3 点云编码器
-
功能:
针对激光雷达采集的稀疏三维点云数据进行处理,提取准确的距离和形状信息。 -
实现方式:
将点云数据转换为与鸟瞰视角相匹配的特征表示,为后续的多模态融合提供几何信息支持。(PointNet)
2.4 地图元素BEV解码器
-
功能:
融合经过视角转换后的图像特征与点云特征,直接预测矢量化的地图元素。 -
实现方式:
利用解码器模块将高维融合特征映射为精确的地图元素,包括车道线、道路边界、人行横道等。采用回归与分类相结合的策略,实现对位置与形状的精准预测。
2.5 损失函数
三个预测结果分支,语义分割、实例分割、直接预测
-
语义分割损失
这部分采用交叉熵损失或加权的交叉熵来应对类别不平衡问题。 -
实例分割损失
这部分损失函数通常由两个组成部分构成,分别称为方差损失(Variance Loss)和距离损失(Distance Loss),具体定义如下:
1、方差损失
目的:拉近同一实例内的像素特征:让属于同一车道(或其他地图元素)的像素,其对应的实例嵌入尽可能接近。
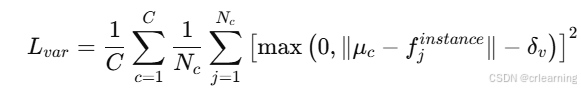
2、方差损失
目的:拉开不同实例间的特征距离:让来自不同地图实例的像素嵌入彼此区分开,保持足够的间隔。
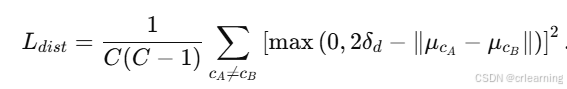
-
直接预测(回归)损失
对于直接预测地图元素的关键几何参数(例如控制点坐标、曲线参数等),则使用回归损失,比如 Smooth L1 Loss 或 L1 Loss。这部分损失保证了在预测地图元素形状和位置时的精确度。
3. 模块有效性解析:为什么 HDMapNet 能够 Work?
3.1 多模态数据互补
图像数据提供了丰富的语义信息,而激光雷达数据在距离测量与物体形状方面具有高精度优势。两者的有效融合使得即使在单一传感器受限的情况下,模型依然能获取全面环境信息,从而提高整体鲁棒性。
3.2 高效的神经视图转换
传统视角转换往往依赖于手工设计的几何规则,而神经视图转换器通过端到端学习,不仅简化了流程,还能更好地适应复杂环境的非线性变化,确保从透视图到鸟瞰图的准确映射。
3.3 端到端的训练策略
模型整体采用端到端训练,各模块在训练过程中可以协同优化,降低了各环节之间的误差累积,最终使得地图元素预测更加精准,整体性能稳步提升。
3.4 矢量化表示的优越性
直接预测矢量化地图元素不仅避免了传统栅格化表示可能带来的信息损失,而且更适合下游任务(如路径规划和运动预测),实现精细控制和高效决策。
4. 实验效果与性能评估
4.1可视化结果对比
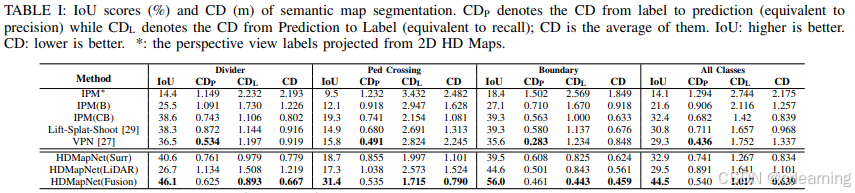
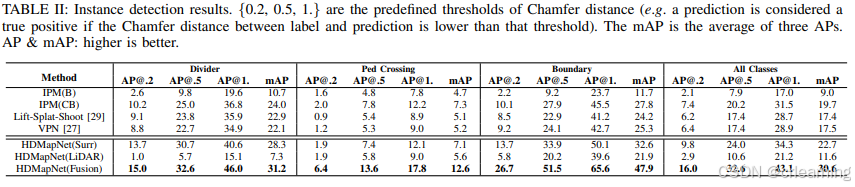
最下方为HDMapNet不同数据方式的可视化结果,可见融合多传感器的效果最佳。

4.2 实验指标对比



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











