









一、贝叶斯调优
# 参考: https://www.cnblogs.com/yangruiGB2312/p/9374377.html
from sklearn.datasets import make_classification
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import cross_val_score
import numpy as np
from bayes_opt import BayesianOptimization
# 不调参的结果: 产生随机分类数据集,10个特征, 2个类别
x, y = make_classification(n_samples=1000,n_features=10,n_classes=2)
# x表示数据,y表示数据特征,如果是二分类,就代表是0还是是1
rf = RandomForestClassifier()
# print(np.mean(cross_val_score(rf, x, y, cv=20, scoring='roc_auc'))) # 0.9857199999999999
# 调参先定义一个目标函数,放入我们希望优化的参数
# 输出为模型交叉验证5次的AUC均值,作为目标函数
# 由于bayes优化只能优化连续超参数,因此要加上int()转为离散超参数
def rf_cv(n_estimators, min_samples_split, max_features, max_depth):
val = cross_val_score(
RandomForestClassifier(n_estimators=int(n_estimators),
min_samples_split=int(min_samples_split),
max_features=min(max_features, 0.999), # float
max_depth=int(max_depth),
random_state=2
),
x, y, scoring='roc_auc', cv=5 # 交叉验证五次的auc值
).mean()
return val
# 示例化一个bayes优化对象
rf_bo = BayesianOptimization(
rf_cv,
{'n_estimators': (10, 250),
'min_samples_split': (2, 25),
'max_features': (0.1, 0.999),
'max_depth': (5, 15)}
)
# 第一个参数是我们的优化目标函数,第二个参数是我们所需要输入的超参数名称,以及其范围。超参数名称必须和目标函数的输入名称一一对应。
rf_bo.maximize() # 进行bayes优化 图片如下
rf_bo.maximize() # 输出:
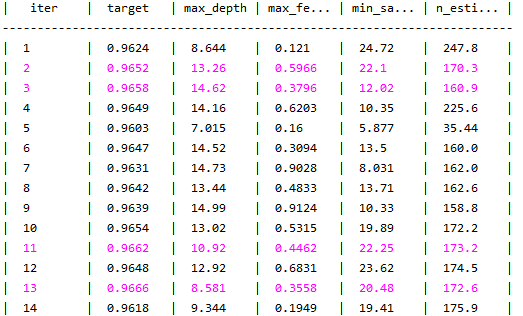
print(rf_bo)
print(rf_bo.res)
求得最优解:
lst = []
for i in rf_bo.res:
lst.append(i['target'])
idx = lst.index(max(lst))
print("最优解: ", rf_bo.res[idx])

二、贝叶斯调优中给定的x_train,y_train格式
x, y = make_classification(n_samples=1000,n_features=10,n_classes=2)
# print("x: ", x)
# print("y: ", y)
x: [[-0.45729536 1.87189733 -0.15822285 ... 1.14633518 -0.34184748
-0.3381224 ]
[ 0.91191611 -1.95601821 -0.14220887 ... -0.69966786 -1.44179576
0.92680861]
[-2.41549883 0.05592119 -0.77123278 ... 1.04856482 0.19166089
0.27461997]
...
[-0.44009857 -0.62424227 -1.30796643 ... 0.98661767 -2.25306041
0.14912735]
[-0.63530235 -1.87410427 -0.97032254 ... -1.03849148 -0.1722573
0.19310018]
[ 1.31295692 0.3418732 -0.23368177 ... -0.35426307 -1.21393446
-1.24867578]]
y: [1 1 1 0 1 1 0 1 1 1 0 1 0 0 1 1 1 0 0 0 1 1 0 0 0 0 1 0 1 1 0 0 1 0 0
0 1 1 0 1 0 0 0 1 0 1 1 0 0 0 0 1 1 0 0 0 1 0 0 1 0 0 1 1 0 1 0 0 1 1 1 0
0]
三、将论文数据中的x_train,y_train变为适用贝叶斯调优的参数
这里x_test,y_test都用不上,所以可以注释
# 将原来数据中的x_train,y_train 变为与调优参数格式一致的x, y
# 考虑正负样本的数目是否要相等??目前用的数据3,相差较大
from sklearn.datasets import make_classification
import numpy as np
import os
from keras.preprocessing import sequence
def create_data_list(dict_path, data_path):
with open(os.path.join(dict_path), 'r', encoding='utf-8') as f_data:
dict_txt = eval(f_data.readlines()[0]) # 读取all_data_dict.txt整个数值,eval是用字典的方式读取
with open(os.path.join(data_path), 'r', encoding='utf-8') as f_data:
lines = f_data.readlines()
x_train, y_train = [], []
x_test, y_test = [], []
i = 0
for line in lines:
title = line.split(",")[-1] # 选取文本
lab = line.split(",")[0] # 选取标签 "\t"表示空格
label = np.dtype('int64').type(int(lab))
lst = []
if i % 8 == 0: # 20%验证集
for s in title:
temp = str(dict_txt[s])
lst.append(int(temp))
x_test.append(lst)
y_test.append(label)
else:
for s in title:
temp = str(dict_txt[s])
lst.append(int(temp))
x_train.append(lst)
y_train.append(label)
i += 1
# 转换为numpy形式
x_train = np.array(x_train)
y_train = np.array(y_train)
# x_test = np.array(x_test)
# y_test = np.array(y_test)
return x_train, y_train, x_test, y_test
data_path = "02train.tsv"
dict_path = "02all_data_dict.txt"
x_train, y_train, x_test, y_test = create_data_list(dict_path, data_path)
maxword = 20
x_train = sequence.pad_sequences(x_train, maxlen=maxword) # 如果长度不够给定的maxword,就用0在前面填充
x_test = sequence.pad_sequences(x_test, maxlen=maxword) # 将序列转化为经过填充以后的一个新序列
x, y = x_train, y_train
print("x_train: ", x_train)
# [[ 900 1877 2379 ... 2582 1577 1581]
# [1860 3864 2934 ... 2041 3605 1581]
# [ 0 0 0 ... 1577 1577 1581]
# ...
# [3570 3215 657 ... 3794 1885 1581]
# [2751 1877 1620 ... 3224 1577 1581]
# [ 0 0 0 ... 387 3936 1581]]
print("y_train: ", y_train)
# [1 1 1 ... 0 0 0]
四、交叉验证中函数所需参数
sklearn.cross_validation.cross_val_score(estimator, X, y=None, scoring=None, cv=None, n_jobs=1, verbose=0, fit_params=None, pre_dispatch=‘2*n_jobs’)
estimator:数据对象
X:数据
y:预测数据
soring:调用的方法
cv:交叉验证生成器或可迭代的次数
n_jobs:同时工作的cpu个数(-1代表全部)
verbose:详细程度
fit_params:传递给估计器的拟合方法的参数
pre_dispatch:控制并行执行期间调度的作业数量。减少这个数量对于避免在CPU发送更多作业时CPU内存消耗的扩大是有用的。
from sklearn import datasets, linear_model
from sklearn.cross_validation import cross_val_score
diabetes = datasets.load_diabetes()
X = diabetes.data[:150]
y = diabetes.target[:150]
lasso = linear_model.Lasso()
print(cross_val_score(lasso, X, y))
# [ 0.33150734 0.08022311 0.03531764]


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









