







 本文详细介绍了一次数据清洗过程,包括缺失值处理、异常值检测与剔除。通过填充中位数、众数,应用孤立森林算法识别异常,以及自定义规则删除异常数据,确保了数据质量。
本文详细介绍了一次数据清洗过程,包括缺失值处理、异常值检测与剔除。通过填充中位数、众数,应用孤立森林算法识别异常,以及自定义规则删除异常数据,确保了数据质量。
导入数据及所需的包
#coding:utf-8
#导入warnings包,利用过滤器来实现忽略警告语句。
import warnings
warnings.filterwarnings('ignore')
# GBDT
from sklearn.ensemble import GradientBoostingRegressor
# XGBoost
import xgboost as xgb
# LightGBM
import lightgbm as lgb
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.preprocessing import LabelEncoder #特征编码
from sklearn.ensemble import IsolationForest #孤立森林异常值处理
#载入数据
data_train = pd.read_csv('./train_data.csv')
data_train['Type'] = 'Train'
data_test = pd.read_csv('./test_a.csv')
data_test['Type'] = 'Test'
data_all = pd.concat([data_train, data_test], ignore_index=True)
#看一下现在有多少个数据
len(data_train)
41400
数据预处理
在这一阶段只填充部分方便填充的缺失值,剩下的在特征工程阶段处理
先分别看一下data_train和data_test有多少缺失值
print(data_train.isnull().sum())
print(data_test.isnull().sum())
data_train
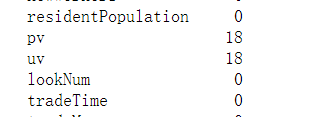
data_test
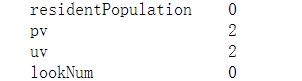
都在pv和uv,加起来一共20个缺失值,应该是官方故意弄成缺失值的,用众数或平均数填上就可以了
data_train.fillna(data_train['pv'].mean(),inplace = True)
data_train.fillna(data_train['uv'].mean(),inplace = True)
data_train['pv'] = data_train['pv'].astype('int')
data_train['uv'] = data_train['uv'].astype('int')
data_test.fillna(data_test['pv'].mean(),inplace = True)
data_test.fillna(data_test['uv'].mean(),inplace = True)
data_test['pv'] = data_test['pv'].astype('int')
data_test['uv'] = data_test['uv'].astype('int')
其他还有孤立值,比如buildYear里的暂无信息也算是缺失值,因为数量不多,可以用众数填上
#将buildYear用众数来填充
buildYearmean = pd.DataFrame(data_train[data_train['buildYear'] != '暂无信息']['buildYear'].mode())
data_train.loc[data_train[data_train['buildYear'] == '暂无信息'].index, 'buildYear'] = buildYearmean.iloc[0, 0]
data_train['buildYear'] = data_train['buildYear'].astype('int') #从object类型转换为int类型
data_train['buildYear']
buildYearmean = pd.DataFrame(data_test[data_test['buildYear'] != '暂无信息']['buildYear'].mode())
data_test.loc[data_test[data_test['buildYear'] == '暂无信息'].index, 'buildYear'] = buildYearmean.iloc[0, 0]
data_test['buildYear'] = data_test['buildYear'].astype('int') #从object类型转换为int类型
data_test['buildYear']
剩下的缺失值,等特种工程中再详细处理
异常值处理
1.使用孤立森林
孤立森林原理及实例:
https://blog.youkuaiyun.com/ChenVast/article/details/82863750
https://blog.youkuaiyun.com/extremebingo/article/details/80108247
建模型、训练、预测
获取预测值为-1的数据的索引
根据索引删除数据
def IF_drop(train):
IForest = IsolationForest(contamination=0.01)
IForest.fit(train["tradeMoney"].values.reshape(-1,1))
y_pred = IForest.predict(train["tradeMoney"].values.reshape(-1,1))
drop_index = train.loc[y_pred==-1].index
print(drop_index)
train.drop(drop_index,inplace=True)
return train
data_train = IF_drop(data_train)

2.自定义删除异常值
drop()函数传入index
def dropData(train):
# 丢弃部分异常值
data.drop(data[(data['region']=='RG00001') & (data['tradeMoney']<1000)&(data['area']>50)].index,inplace=True)
data.drop(data[(data['region']=='RG00001') & (data['tradeMoney']>25000)].index,inplace=True)
data.drop(data[(data['region']=='RG00001') & (data['area']>250)&(data['tradeMoney']<20000)].index,inplace=True)
data.drop(data[(data['region']=='RG00001') & (data['area']>400)&(data['tradeMoney']>50000)].index,inplace=True)
data.drop(data[(data['region']=='RG00001') & (data['area']>100)&(data['tradeMoney']<2000)].index,inplace=True)
data.drop(data[(data['region']=='RG00002') & (data['area']<100)&(data['tradeMoney']>60000)].index,inplace=True)
data.drop(data[(data['region']=='RG00003') & (data['area']<300)&(data['tradeMoney']>30000)].index,inplace=True)
data.drop(data[(data['region']=='RG00003') & (data['tradeMoney']<500)&(data['area']<50)].index,inplace=True)
data.drop(data[(data['region']=='RG00003') & (data['tradeMoney']<1500)&(data['area']>100)].index,inplace=True)
data.drop(data[(data['region']=='RG00003') & (data['tradeMoney']<2000)&(data['area']>300)].index,inplace=True)
data.drop(data[(data['region']=='RG00003') & (data['tradeMoney']>5000)&(data['area']<20)].index,inplace=True)
data.drop(data[(data['region']=='RG00003') & (data['area']>600)&(data['tradeMoney']>40000)].index,inplace=True)
data.drop(data[(data['region']=='RG00004') & (data['tradeMoney']<1000)&(data['area']>80)].index,inplace=True)
data.drop(data[(data['region']=='RG00006') & (data['tradeMoney']<200)].index,inplace=True)
data.drop(data[(data['region']=='RG00005') & (data['tradeMoney']<2000)&(data['area']>180)].index,inplace=True)
data.drop(data[(data['region']=='RG00005') & (data['tradeMoney']>50000)&(data['area']<200)].index,inplace=True)
data.drop(data[(data['region']=='RG00006') & (data['area']>200)&(data['tradeMoney']<2000)].index,inplace=True)
data.drop(data[(data['region']=='RG00007') & (data['area']>100)&(data['tradeMoney']<2500)].index,inplace=True)
data.drop(data[(data['region']=='RG00010') & (data['area']>200)&(data['tradeMoney']>25000)].index,inplace=True)
data.drop(data[(data['region']=='RG00010') & (data['area']>400)&(data['tradeMoney']<15000)].index,inplace=True)
data.drop(data[(data['region']=='RG00010') & (data['tradeMoney']<3000)&(data['area']>200)].index,inplace=True)
data.drop(data[(data['region']=='RG00010') & (data['tradeMoney']>7000)&(data['area']<75)].index,inplace=True)
data.drop(data[(data['region']=='RG00010') & (data['tradeMoney']>12500)&(data['area']<100)].index,inplace=True)
data.drop(data[(data['region']=='RG00004') & (data['area']>400)&(data['tradeMoney']>20000)].index,inplace=True)
data.drop(data[(data['region']=='RG00008') & (data['tradeMoney']<2000)&(data['area']>80)].index,inplace=True)
data.drop(data[(data['region']=='RG00009') & (data['tradeMoney']>40000)].index,inplace=True)
data.drop(data[(data['region']=='RG00009') & (data['area']>300)].index,inplace=True)
data.drop(data[(data['region']=='RG00009') & (data['area']>100)&(data['tradeMoney']<2000)].index,inplace=True)
data.drop(data[(data['region']=='RG00011') & (data['tradeMoney']<10000)&(data['area']>390)].index,inplace=True)
data.drop(data[(data['region']=='RG00012') & (data['area']>120)&(data['tradeMoney']<5000)].index,inplace=True)
data.drop(data[(data['region']=='RG00013') & (data['area']<100)&(data['tradeMoney']>40000)].index,inplace=True)
data.drop(data[(data['region']=='RG00013') & (data['area']>400)&(data['tradeMoney']>50000)].index,inplace=True)
data.drop(data[(data['region']=='RG00013') & (data['area']>80)&(data['tradeMoney']<2000)].index,inplace=True)
data.drop(data[(data['region']=='RG00014') & (data['area']>300)&(data['tradeMoney']>40000)].index,inplace=True)
data.drop(data[(data['region']=='RG00014') & (data['tradeMoney']<1300)&(data['area']>80)].index,inplace=True)
data.drop(data[(data['region']=='RG00014') & (data['tradeMoney']<8000)&(data['area']>200)].index,inplace=True)
data.drop(data[(data['region']=='RG00014') & (data['tradeMoney']<1000)&(data['area']>20)].index,inplace=True)
data.drop(data[(data['region']=='RG00014') & (data['tradeMoney']>25000)&(data['area']>200)].index,inplace=True)
data.drop(data[(data['region']=='RG00014') & (data['tradeMoney']<20000)&(data['area']>250)].index,inplace=True)
data.drop(data[(data['region']=='RG00005') & (data['tradeMoney']>30000)&(data['area']<100)].index,inplace=True)
data.drop(data[(data['region']=='RG00005') & (data['tradeMoney']<50000)&(data['area']>600)].index,inplace=True)
data.drop(data[(data['region']=='RG00005') & (data['tradeMoney']>50000)&(data['area']>350)].index,inplace=True)
data.drop(data[(data['region']=='RG00006') & (data['tradeMoney']>4000)&(data['area']<100)].index,inplace=True)
data.drop(data[(data['region']=='RG00006') & (data['tradeMoney']<600)&(data['area']>100)].index,inplace=True)
data.drop(data[(data['region']=='RG00006') & (data['area']>165)].index,inplace=True)
data.drop(data[(data['region']=='RG00012') & (data['tradeMoney']<800)&(data['area']<30)].index,inplace=True)
data.drop(data[(data['region']=='RG00007') & (data['tradeMoney']<1100)&(data['area']>50)].index,inplace=True)
data.drop(data[(data['region']=='RG00004') & (data['tradeMoney']>8000)&(data['area']<80)].index,inplace=True)
data.loc[(data['region']=='RG00002')&(data['area']>50)&(data['rentType']=='合租'),'rentType']='整租'
data.loc[(data['region']=='RG00014')&(data['rentType']=='合租')&(data['area']>60),'rentType']='整租'
data.drop(data[(data['region']=='RG00008')&(data['tradeMoney']>15000)&(data['area']<110)].index,inplace=True)
data.drop(data[(data['region']=='RG00008')&(data['tradeMoney']>20000)&(data['area']>110)].index,inplace=True)
data.drop(data[(data['region']=='RG00008')&(data['tradeMoney']<1500)&(data['area']<50)].index,inplace=True)
data.drop(data[(data['region']=='RG00008')&(data['rentType']=='合租')&(data['area']>50)].index,inplace=True)
data.drop(data[(data['region']=='RG00015') ].index,inplace=True)
data.reset_index(drop=True, inplace=True)
return data
data_train = dropData(data_train)
还可以自行根据对数据的理解进行部分数据的删除,注意在最后对数据进行索引的重新设置data.reset_index(drop=True, inplace=True)
重新查看data_train数量
40901,大概少了500个数据左右
总结:
数据清洗主要做的是
缺失值的处理:填充(中位数、众数、平均数)、直接删去
异常值:异常值的评估,可以使用箱型图等手段查看异常值的分布水平,然后根据对数据的理解进行自定义删除,还可以用一些无监督的算法如孤立森林等进行查找和删去


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









