







 本文介绍了批量归一化在全连接层和卷积层的应用,以及预测时的处理方式。接着,讨论了深度学习中的残差网络,解释了残差块的设计原理和实现。此外,还详细阐述了稠密连接网络DenseNet的结构,包括其特有的concat连接和稠密块计算方式,并提供了相关代码示例。
本文介绍了批量归一化在全连接层和卷积层的应用,以及预测时的处理方式。接着,讨论了深度学习中的残差网络,解释了残差块的设计原理和实现。此外,还详细阐述了稠密连接网络DenseNet的结构,包括其特有的concat连接和稠密块计算方式,并提供了相关代码示例。
批量归一化
批量归一化(BatchNormalization)
对输入的标准化(浅层模型)
处理后的任意一个特征在数据集中所有样本上的均值为0、标准差为1。
标准化处理输入数据使各个特征的分布相近
批量归一化(深度模型)
利用小批量上的均值和标准差,不断调整神经网络中间输出,从而使整个神经网络在各层的中间输出的数值更稳定。
1.全连接层的批量归一化
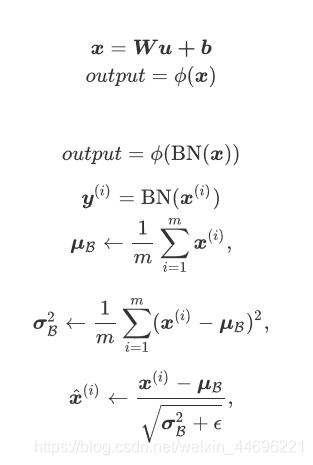
前两条公式是一个全连接层的普通实现方式,批量归一化的过程处在两条公式之间,对输出层维度的i个x计算μ和σ,然后计算新的x(i),再通过激活函数得到输出
这⾥ϵ > 0是个很小的常数,保证分母大于0
卷积层的批量归一化
位置:卷积计算之后、应⽤激活函数之前。
如果卷积计算输出多个通道,我们需要对这些通道的输出分别做批量归一化,且每个通道都拥有独立的拉伸和偏移参数。
计算:对单通道,batchsize=m,卷积计算输出=pxq
对该通道中m×p×q个元素同时做批量归一化,使用相同的均值和方差。
预测时的批量归一化
训练:以batch为单位,对每个batch计算均值和方差。
预测:用移动平均估算整个训练数据集的样本均值和方差。
代码部分
import time
import torch
from torch import nn, optim
import torch.nn.functional as F
import torchvision
import sys
sys.path.append("/home/kesci/input/")
import d2lzh1981 as d2l
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
def batch_norm(is_training, X, gamma, beta, moving_mean, moving_var, eps, momentum):
# 判断当前模式是训练模式还是预测模式
if not is_training:
# 如果是在预测模式下,直接使用传入的移动平均所得的均值和方差
X_hat = (X - moving_mean) / torch.sqrt(moving_var + eps)
else:
assert len(X.shape) in (2, 4)
if len(X.shape) == 2:
# 使用全连接层的情况,计算特征维上的均值和方差
mean = X.mean(dim=0)
var = ((X - mean) ** 2).mean(dim=0)
else:
# 使用二维卷积层的情况,计算通道维上(axis=1)的均值和方差。这里我们需要保持
# X的形状以便后面可以做广播运算
mean = X.mean(dim=0, keepdim=True).mean(dim=2, keepdim=True).mean(dim=3, keepdim=True)
var = ((X - mean) ** 2).mean(dim=0, keepdim=True).mean(dim=2, keepdim=True).mean(dim=3, keepdim=True)
# 训练模式下用当前的均值和方差做标准化
X_hat = (X - mean) / torch.sqrt(var + eps)
# 更新移动平均的均值和方差
moving_mean = momentum * moving_mean + (1.0 - momentum) * mean
moving_var = momentum * moving_var + (1.0 - momentum) * var
Y = gamma * X_hat + beta # 拉伸和偏移
return Y, moving_mean, moving_var在函数的基础上写成类的形式方便调用
class BatchNorm(nn.Module):
def __init__(self, num_features, num_dims):
super(BatchNorm, self).__init__()
if num_dims == 2:
shape = (1, num_features) #全连接层输出神经元
else:
shape  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 7536
7536

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









