







 本文介绍了如何使用Python对txt文件进行数据筛选,通过实例展示了筛选p值小于0.05且foldchange绝对值大于2的行,并输出到新文件。讲解了for-in循环、文件读写、条件判断等基础知识,同时提到了pandas和numpy模块在处理Excel文件时的高效性。
本文介绍了如何使用Python对txt文件进行数据筛选,通过实例展示了筛选p值小于0.05且foldchange绝对值大于2的行,并输出到新文件。讲解了for-in循环、文件读写、条件判断等基础知识,同时提到了pandas和numpy模块在处理Excel文件时的高效性。
之前已经分享完python的数据类型和数据结构了,我认为掌握了这两方面内容其实已经具备使用python进行数据分析的能力了,但实际情况是你经常会发现你看了很多python的基础内容,而当你要使用时还是发现无从下手(哈哈,因为我一开始是这样),那是因为你缺少实战经验,实战才是学习掌握python的最快办法。所以要从零开始学习python,有目的的边查边写能够让你迅速掌握python。在整理写作过程中也发现了一个非常好的python学习资源,介绍的非常详细,链接如下:
Python - 100天从新手到大师
https://github.com/jackfrued/Python-100-Days
这个链接的内容较多,但没有太大的目的性,我今天的主要目的就是利用python进行数据筛选。情况是这样的,我目前有20个.txt文件(假设名为1.txt - 20.txt),各个文件内容如下:
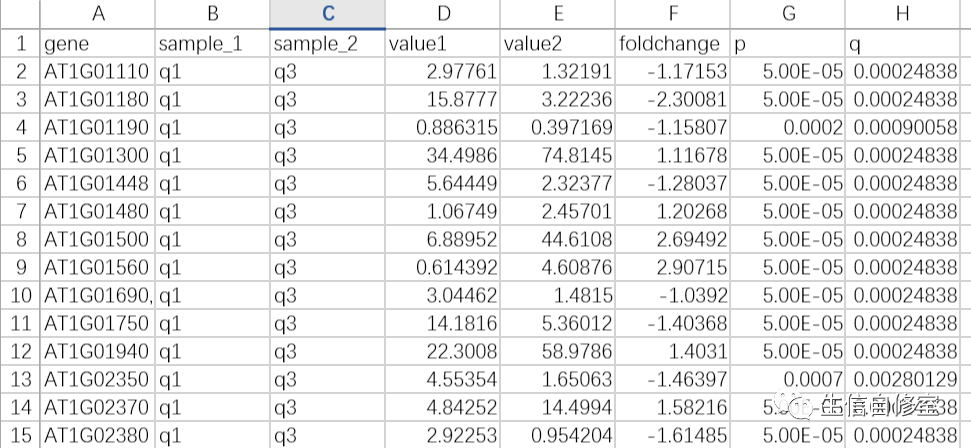
我想筛选每个文件中p小于0.05,foldchange绝对值大于2的所有行,并分别输出(要是熟悉RNA-seq其实就是差异基因的筛选)
代码如下:
#!/usr/bin/env python3
excel_name = []
for i in range(1,4):
excel_name.append(str(i) + '.' + 'txt')
pri 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









