 Pandas Excel 多条件筛选与多Sheet保存
Pandas Excel 多条件筛选与多Sheet保存







在今天的工作中,又遇到了一些小问题。都是关于pandas操作excel的。
一是多条件筛选数据,二是将数据写入excel,但是要保存在同一个工作簿的多个sheet。
先上一个完整代码

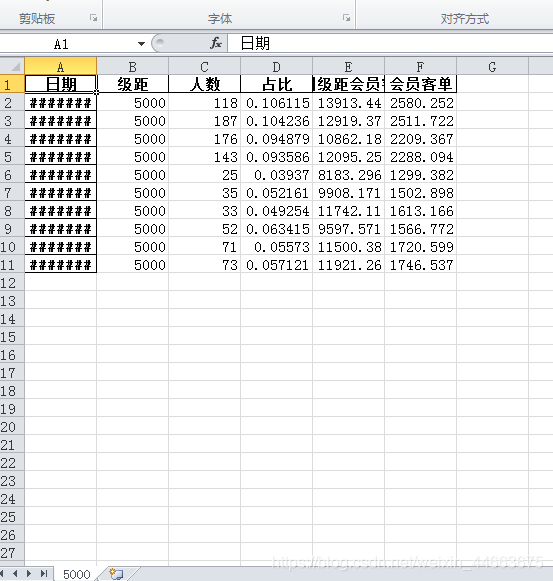
源数据是这样的:
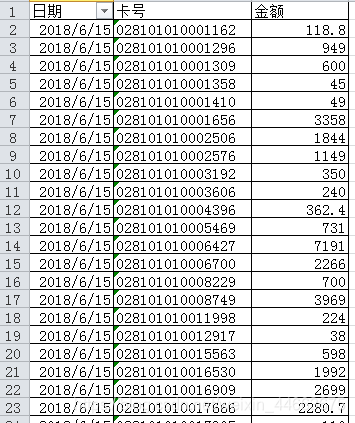
得到的结果是:
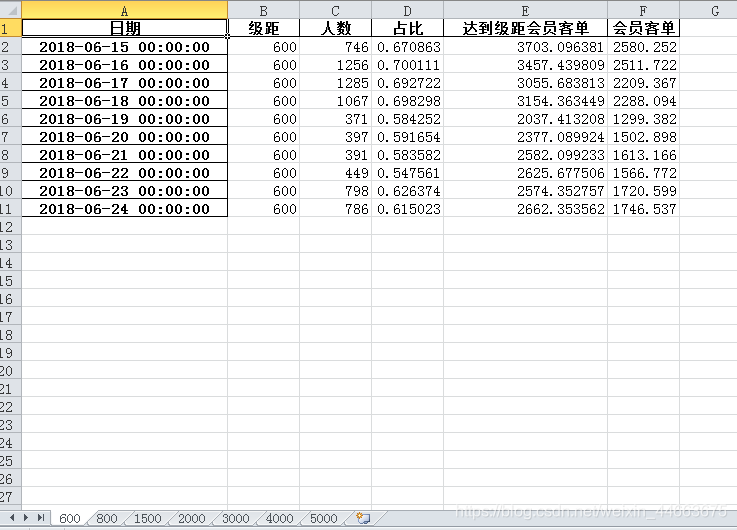
我在做的是,得到不同级距(门槛)下‘人数’,‘占比’,‘达到级距会员客单’,‘会员客单’,并循环保存在同一个工作簿下的不同工作表内。
现在说一下我遇到的问题:
1、pandas多条件筛选
如果我采用下面的代码,就是将&,换为and,就会出现错误,因为在pandas.dataframe的bool筛选时,我们不能使用and和or,只能用&和|
详见https://blog.youkuaiyun.com/wx0628/article/details/87365629
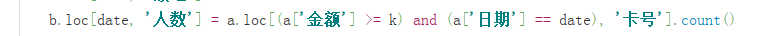

2、数据存储在一个工作簿的多个excel
如果我们保存代码的文件写成下面的代码,按理说是可以实现保存在不同sheet的,但是我们会发现,最终我们只得到5000这个级距的,因为前面的文件都被覆盖了,但是如果我们加上writer=pd.ExcelWriter(‘C:\Users\Administrator\Desktop\门槛.xlsx’),再b.to_excel(writer,sheet_name=str(k)),就能实现保存在不同sheet了。
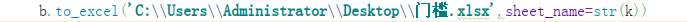
 本文介绍了使用Pandas进行Excel文件多条件筛选的方法,避免使用and/or等逻辑运算符,并解决了如何将不同数据集保存到同一Excel文件的不同Sheet中的问题。
本文介绍了使用Pandas进行Excel文件多条件筛选的方法,避免使用and/or等逻辑运算符,并解决了如何将不同数据集保存到同一Excel文件的不同Sheet中的问题。

















 2716
2716

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









