






最近在进行点云目标检测方面论文工作,对于PointRcnn虽然readme已经写得很清楚了,但是复现过程中依然会遇到很多问题,以下是我对与readme的重述和对整个程序运行流程的一些说明。
论文链接:
PointRCNN paper
code:
PointRCNN code
环境要求
Linux (tested on Ubuntu 14.04/16.04)
Python 3.6+
PyTorch 1.0
依赖包easydict 、tqdm、tensorboardX 、fire、numba、pyyaml、scikit-image 、shapely
数据准备
PointRcnn使用的Data是KITTI数据集,KITTI数据集可以在官网上进行下载,官网地址:
KITTI数据集链接
下载红箭头标注的数据集,分别是image_2,velodyne,calib,以及label.
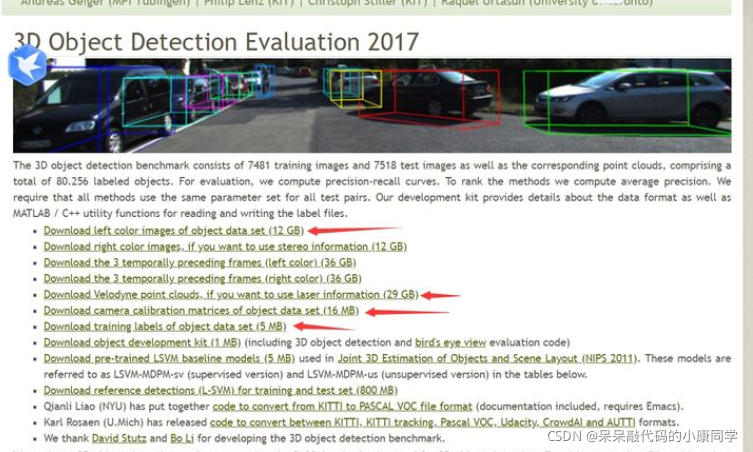
推荐迅雷下载,下载速度比较快。
然后按照如下所示的结构组织Data的结构,将准备好的数据集放入object文件夹中,并将其放在PointRcnn文件的KITTI/object下
PointRCNN
├── data
│ ├── KITTI
│ │ ├── ImageSets
│ │ ├── object
│ │ │ ├──training
│ │ │ ├──calib
│ │ │ ├──velodyne
│ │ │ ├──label_2
│ │ │ ├──image_2
│ │ │ ├──testing
│ │ │ ├──calib
│ │ │ ├──velodyne
│ │ │ ├──image_2
├── lib
├── pointnet2_lib
├── tools
使用时本人数据集中未包含plane,所以要将plane使用部分代码注释掉。
程序准备
1 克隆源程序,其中“–recursive”很重要.
git clone --recursive https://github.com/sshaoshuai/PointRCNN.git
2 配置依赖包
conda install pytorch==1.0.0 torchvision==0.2.1 cuda100 -c pytorch
pip install easydict
pip install tqdm
pip insatll tensorboardX
pip install fire
pip install numba
pip install pyyaml
pip install scikit-image
pip install shapely
3 安装pointnet2_lib, iou3d, roipool3d库
cd命令进入PointRcnn目录 ,运行
sh build_and_install.sh
组织数据
PointRCNN
├── data
│ ├── KITTI
│ │ ├── ImageSets
│ │ ├── object
│ │ │ ├──training
│ │ │ ├──calib
│ │ │ ├──velodyne
│ │ │ ├──label_2
│ │ │ ├──image_2
│ │ │ ├──testing
│ │ │ ├──calib
│ │ │ ├──velodyne
│ │ │ ├──image_2
├── lib
├── pointnet2_lib
├── tools
至此前期准备工作完毕
程序运行
训练模型
Step1 进入tools文件夹:
cd /home/seeta-yuzoye/PointRCNN/tools
Step2 准备数据
python generate_gt_database.py --class_name 'Car' --split train
Step3 第一阶段训练:(生成checkpoint_epoch_200.pth)
CPU训练(200次迭代)
python train_rcnn.py --cfg_file cfgs/default.yaml --batch_size 16 --train_mode rpn --epochs 200
多GPU进行训练(200次迭代)
CUDA_VISIBLE_DEVICES=0,1 python train_rcnn.py --cfg_file cfgs/default.yaml --batch_size 16 --train_mode rpn --epochs 200 --mgpus
Step4 第二阶段训练(用step3生成的checkpoint_epoch_200.pth进行训练)
CPU训练(70次迭代)
python train_rcnn.py --cfg_file cfgs/default.yaml --batch_size 4 --train_mode rcnn --epochs 70 --ckpt_save_interval 2 --rpn_ckpt ../output/rpn/default/ckpt/checkpoint_epoch_200.pth
多GPU训练(70次迭代)
CUDA_VISIBLE_DEVICES=0,1 python train_rcnn.py --cfg_file cfgs/default.yaml --batch_size 4 --train_mode rcnn --epochs 70 --ckpt_save_interval 2 --rpn_ckpt ../output/rpn/default/ckpt/checkpoint_epoch_200.pth --mgpus
Test Model
Quick demo
用预训练模型进行测试(PointRCNN.pth文件)
将PointRCNN.pth文件放在tools文件夹下
python eval_rcnn.py --cfg_file cfgs/default.yaml --ckpt PointRCNN.pth --batch_size 1 --eval_mode rcnn --set RPN.LOC_XZ_FINE False
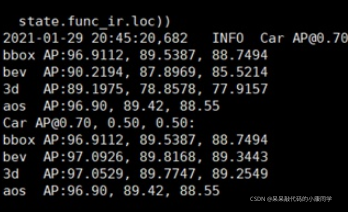
运行之后,查看rcnn文件夹会eval里面会出现pred的预测文件,可以后续做可视化生成预测框用
用最终模型进行测试
此处readme添加的模型文件是checkpoint_epoch_200.pth,而最终测试需要的的文件在…/output/rcnn/ckp目录下,因此我们修改命令
python eval_rcnn.py --cfg_file cfgs/default.yaml --ckpt ../output/rcnn/ckpt/checkpoint_epoch_70.pth --batch_size 4 --eval_mode rcnn
Eval所有checkpoint
python eval_rcnn.py --cfg_file cfgs/default.yaml --eval_mode rcnn --eval_all
可能出现的问题
1、plane数据集未使用,代码无法运行。
解决方法:将数据增强部分代码注释掉然后在进行运行。
2、在test model时出现卡住没有反应的问题,一开始以为是服务器卡了,后来发现是numba包的版本问题。
解决方法如下:
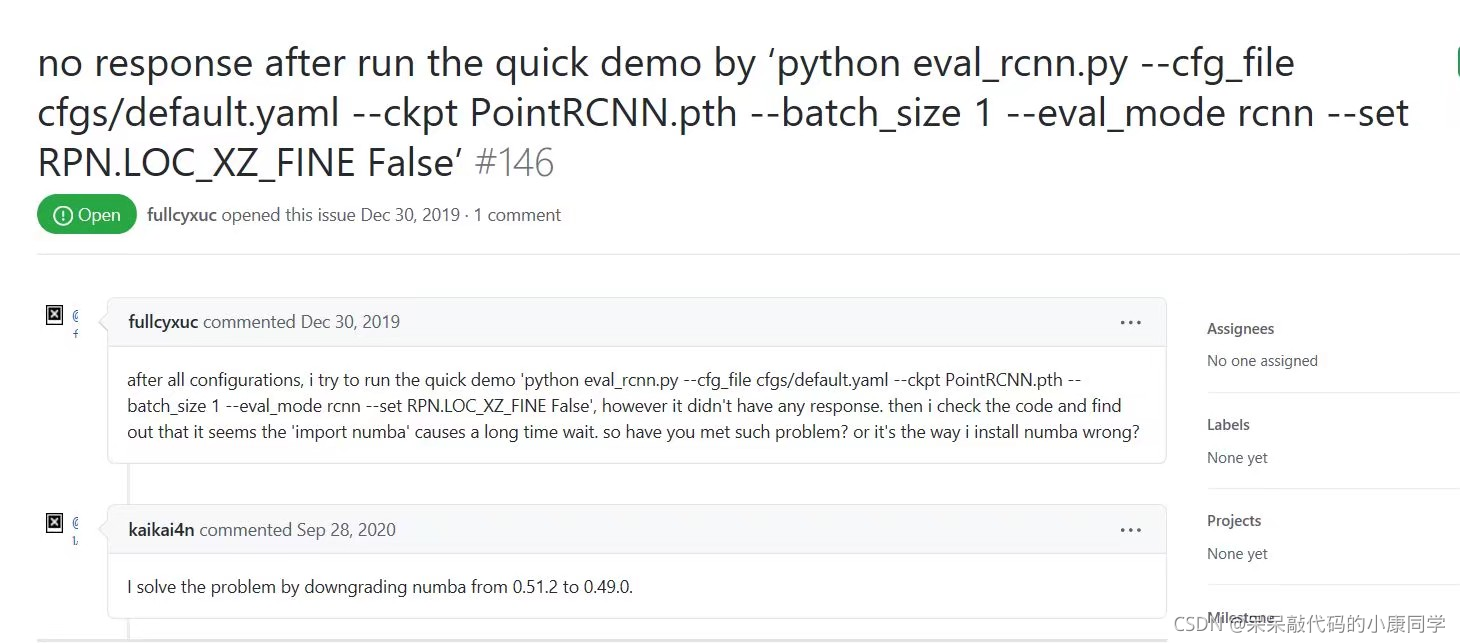
将numba包从0.51.2降级到0.49.0
总结
如何跑通PointRcnn的代码,引用请注明来源,如有错误欢迎指正。一起学习,共同进步。


















 267
267

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











