







 本文详细介绍了RPN(Region Proposal Network)架构,包括Anchor的生成、Proposals的选择以及损失函数的计算。RPN在目标检测中起到关键作用,通过在不同大小的feature map上生成和选择Anchor来产生提案。文章还探讨了FPN在RPN中的应用,并展示了RPN网络在PyTorch中的实现细节,包括候选框的产生和正负样本的选择策略。
本文详细介绍了RPN(Region Proposal Network)架构,包括Anchor的生成、Proposals的选择以及损失函数的计算。RPN在目标检测中起到关键作用,通过在不同大小的feature map上生成和选择Anchor来产生提案。文章还探讨了FPN在RPN中的应用,并展示了RPN网络在PyTorch中的实现细节,包括候选框的产生和正负样本的选择策略。
RPN(Region Proposal Network)
引言
由于
RPN架构
RPN
- Anchor 的生成方法
- 如何选择 anchor 做为 proposals
- loss 的计算, 在计算 loss 之前需要从 anchor 中选择正负样本
其实RPN本身就可以做为目标检测的 Head
Anchor 生成
那么 proposal是如何产生的呢?是通过 RPNHead对 Anchor 的预测得分和位置回归得到的。Anchor 是在 feature_map 的 每一个位置生成多个不同大小不同长宽比的矩形框。而且对于不同层的 feature_map 他们的感受野是不一样的,所以设置的 anchor 的大小也不一样 比如下面的参数定义了在五层不同大小的feature_map 上生成的 anchor 大小分别为 32,64,256,512。 这里是对应到输入图像大小上的边长。由于 anchor 的生成是提前定义的,所以相当于超参数一样,所以也有些方法来改进 这里的anchor 的生成方法。
Proposals 的选择
PRNHead会预测在 feanture_map 的每个点上给每一个 anchor 预测一个前景得分。同时还会预测对应的位置。Proposal 的选择有两步,第一步是在每一层的 feature_map 上选择一定数量得分最高的 anchor, 然后对所有的选择做 NMS,NMS的结果选择前 n 个作为最终的 proposal。
逻辑相对简单,但是在pytorch 里相当于要遍历每张图的每个 feature_map,还有就是一些特殊情况的处理,比如对超出图像边缘的 anchor 做剪切等。
loss 的计算
要计算 loss 就需要有标注数据, 这里的预测对象是 anchor 的得分和位置回归,我们有的是真实目标的位置和标签。所以在 Fast R-CNN中,定了一个策略(规则)来对所有的 anchor 打上标签。策略和 iou相关,这里的可以简单看下 iou的计算方法,其想法是假设他们相交,尝试去计算相交区域的左上角和右下角,当这个区域有边小于零的时候表示他们不相交区域为 0。
area1 = box_area(boxes1)
area2 = box_area(boxes2)
lt = torch.max(boxes1[:, None, :2], boxes2[:, :2]) # [N,M,2]
rb = torch.min(boxes1[:, None, 2:], boxes2[:, 2:]) # [N,M,2]
wh = (rb - lt).clamp(min=0) # [N,M,2]
inter = wh[:, :, 0] * wh[:, :, 1] # [N,M]
iou = inter / (area1[:, None] + area2 - inter)
return iou
有了样本还需要计算回归的目标参数,然后再计算 loss,loss的计算和proposals的生成是没有直接相关的,通过 loss的反向传播来修改得分来得到更好的 proposal 所以很多计算都只是在训练过程中用到,比如对 anchor 打上标签的操作。
接下来的内容最好联系下图Faster R-CNN网络进行学习
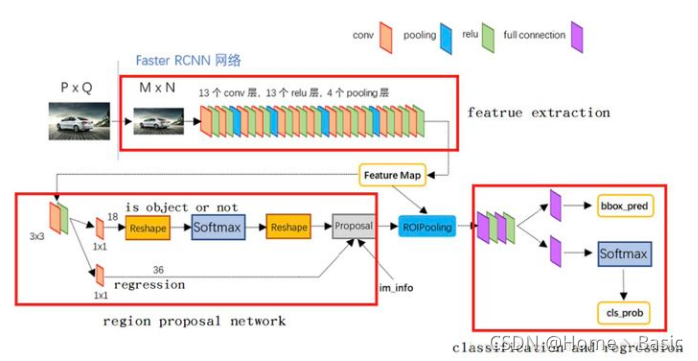
先在图像上进行完特征提取操作后,得到FPN的结果,结果即FPN最终经过3x3卷积融合输出后的几层特征图,即得上图中的Feature Map。接着,在FPN的结果Feature Map上进行操作:像Faster R-CNN中的RPN一样,先在上进行3×3的卷积操作,然后在此结果上,两支并行的1×1卷积核分别卷积出来分类(前背景)与框位置信息(xywh)。
然后我们把RPN的结果拿出来进行RoIpooling后进行分类。
RPN即一个用于目标检测的一系列滑动窗口。具体地,RPN是先进行3×3,然后跟着两条并行的1×1卷积,分布产生前背景分类和框位置回归,我们把这个组合叫做网络头部network head。
FPN for RPN
RPN即一个用于目标检测的一系列滑动窗口。具体地,RPN是先进行3×3,然后跟着两条并行的1×1卷积,分布产生前背景分类和框位置回归,我们把这个组合叫做网络头部network head。
但是前背景分类与框位置回归是在anchor的基础上进行的,简言之即我们先人为定义一些框,然后RPN基于这些框进行调整即可。在SSD中anchor叫prior,更形象一些。为了回归更容易,anchor在Faster R-CNN中预测了3种大小scale,宽高3种比率ratio{1:1,1:2,2:1},共3*3=9种anchor框。
在FPN中我们同样用了一个3×3和两个并行的1×1,但是是在每个level上都进行了RPN这种操作。既然FPN已经有不同大小的特征scale了,那么我们就没必要像Faster R-CNN一样采用3种大小scale的anchor了,因此固定每层特征图对应的anchor尺寸,再采用3种比率的框就行。也就是说,作者在每一个金字塔层级应用了单尺度的anchor,{P2, P3, P4, P5, P6}分别对应的anchor尺度为{32*32, 64*64, 128*128, 256*256, 512*512 },当然目标不可能都是正方形,因此仍然使用三种比例```{1:2, 1:1, 2:1}````,所以金字塔结构中共有15种anchors。
RPN网络对于正负样本的选择
RPN网络在训练时需要有anchor是前景或背景的标签。因此,需要对anchor进行label分类,将其分为正负样本。其原理和Faster R-CNN里一样。
具体方法如下:anchor与gt的IoU>0.7就是正样本(label=1),IoU<0.3是负样本(label=0),其余介于0.3和0.7直接抛弃,不参与训练(label=-1)。例如,在Faster R-CNN中拿256个anchors训练后得到W×H×9个roi。
此外,每个级level的头部的参数是共享的,共享的原因是实验验证出来的。实验证明,虽然每级的feature大小不一样,但是共享与不共享头部参数的准确率是相似的。这个结果也说明了其实金字塔的每级level都有差不多相似的语义信息,而不是普通网络那样语义信息区别很大。
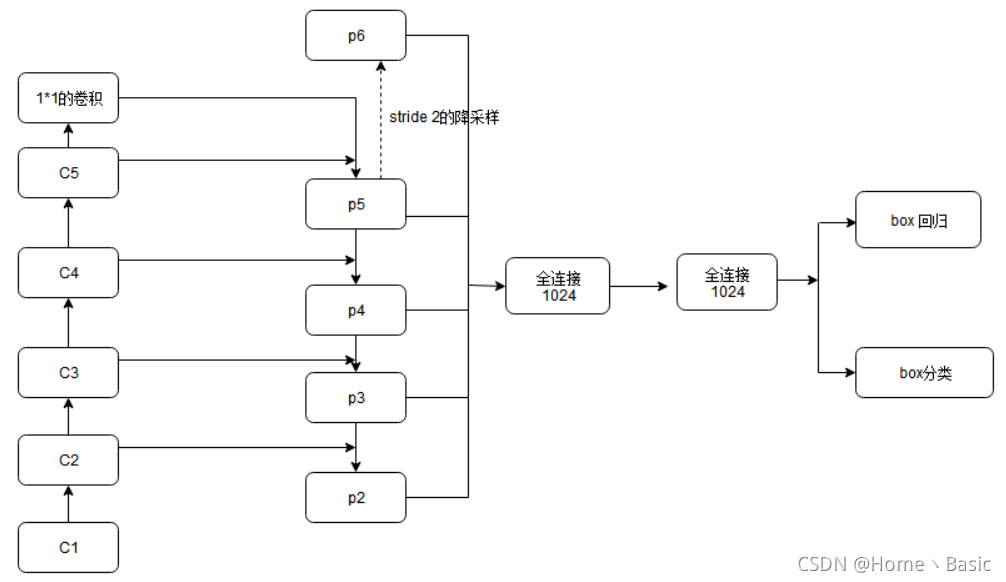
FPN for Fast R-CNN
RPN网络提取到特征后,Fast R-CNN用RoIpool抽取出RoI后进行分类,Fast R-CNN中RoIpooling用来提取特征。Fast R-CNN在单scale特征上有好的表现。为了使用FPN,需要把各个scale的RoI赋给金字塔级level。Fast R-CNN中的ROI Pooling层使用RPN的结果和特征图作为输入。经过特征金字塔,我们得到了许多特征图,作者认为,不同层次的特征图上包含的物体大小也不同,因此,不同尺度的ROI,使用不同特征层作为ROI pooling层的输入。大尺度ROI就用后面一些的金字塔层,比如P5;小尺度ROI就用前面一点的特征层,比如P4。
对于原图上W×H 的RoI,需要选择一层的feature map来对他RoIpooling,选择的feature map的层数P_k的选择依据是:
224是ImageNet预训练的大小,k0是基准值,设置为5或4,代表P5层的输出(原图大小就用P5层),W和H是ROI区域的长和宽,假设ROI是112 * 112的大小,那么k = k0-1 = 5-1 = 4,意味着该ROI应该使用P4的特征层。k值做取整处理。这意味着如果RoI的尺度变小(比如224的1/2),那么它应该被映射到一个精细的分辨率水平。
import torch
import torch.nn.functional as F
import torch.nn as nn
class FPN(nn.Module):
def __init__(self,in_channel_list,out_channel):
super(FPN, self).__init__()
self.inner_layer=[]
self.out_layer=[]
for in_channel in in_channel_list:
self.inner_layer.append(nn.Conv2d(in_channel,out_channel,1))
self.out_layer.append(nn.Conv2d(out_channel,out_channel,kernel_size=3,padding=1))
# self.upsample=nn.Upsample(size=, mode='nearest')
def forward(self,x):
head_output=[]
corent_inner=self.inner_layer[-1](x[-1])
head_output.append(self.out_layer[-1](corent_inner))
for i in range(len(x)-2,-1,-1):
pre_inner=corent_inner
corent_inner=self.inner_layer[i](x[i])
size=corent_inner.shape[2:]
pre_top_down=F.interpolate(pre_inner,size=size)
add_pre2corent=pre_top_down+corent_inner
head_output.append(self.out_layer[i](add_pre2corent))
return list(reversed(head_output))
if __name__ == '__main__':
fpn=FPN([10,20,30],5)
x=[]
x.append(torch.rand(1, 10, 64, 64))
x.append(torch.rand(1, 20, 16, 16))
x.append(torch.rand(1, 30, 8, 8))
c=fpn(x)
print(c)
RPN架构及其Pytorch实现
如下图是Faster R-CNN给出的RPN结构:
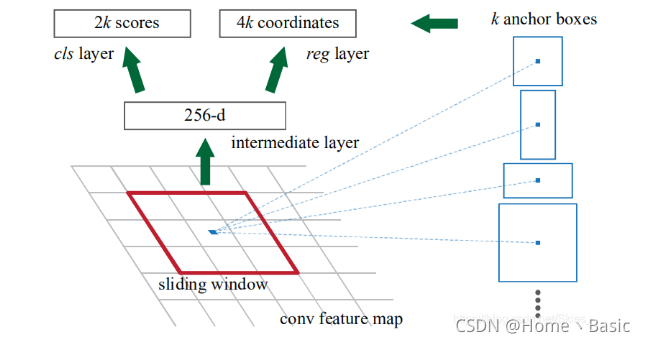
基于RPN产生~20k个候选框
先来看产生这H×W×9个Anchor的代码。
首先针对特征图的左上角顶点产生 9 个 Anchor。
# 针对特征图左上角顶点产生anchor
def generate_base_anchor(base_size=16, ratios=None, anchor_scale=None):
"""
这里假设得到的特征图的大小为w×h,每个位置共产生9个anchor,所以一共产生的anchor
数为w×h×9。原论文中anchor的比例为1:2、2:1和1:1,尺度为128、256和512(相对于
原图而言)。所以在16倍下采样的特征图的上的实际尺度为8、16和32。
"""
# anchor的比例和尺度
if anchor_scale is None:
anchor_scale = [8, 16, 32]
if ratios is None:
ratios = [0.5, 1, 2]
# 特征图的左上角位置映射回原图的位置
py = base_size / 2
px = base_size / 2
# 初始化变量(9,4),这里以特征图的最左上角顶点为例产生anchor
base_anchor & 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 142
142

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









