




四、窗口函数
0、概述
- 窗口函数只能出现在
select语句中。 - 窗口函数中不能嵌套使用窗口函数和聚合函数。
- 窗口函数不能和同级别的聚合函数一起使用。
| 分类 | 函数 | 功能 |
|---|---|---|
| 聚合函数 | SUM | 对窗口中的数据求和。 |
| 聚合函数 | COUNT | 计算窗口中的记录数。 |
| 聚合函数 | AVG | 对窗口中的数据求平均值。 |
| 聚合函数 | MAX | 计算窗口中的最大值。 |
| 聚合函数 | MIN | 计算窗口中的最小值。 |
| 聚合函数 | MEDIAN | 计算窗口中的中位数。 |
| 排序函数 | ROW_NUMBER | 计算行号。从1开始递增(1,2,3,4)。 |
| 排序函数 | RANK | 计算排名。排名可能不连续(1, 2, 2, 4)。 |
| 排序函数 | DENSE_RANK | 计算排名。排名是连续的(1, 2, 2, 3)。 |
| 排序函数 | PERCENT_RANK | 计算排名。输出百分比格式。 |
| 其它 | CUME_DIST | 计算累计分布。 |
| 排序函数 | NTILE | 将数据顺序切分成N等份,返回数据所在等份的编号(从1到N)。 |
| 统计比较 | FIRST_VALUE | 取当前行所对应窗口的第一条数据的值。 |
| 统计比较 | LAST_VALUE | 取当前行所对应窗口的最后一条数据的值。 |
| 统计比较 | LEAD | 取当前行往后(朝分区尾部方向)第N行数据的值。 |
| 统计比较 | LAG | 取当前行往前(朝分区头部方向)第N行数据的值。 |
| 统计比较 | NTH_VALUE | 取当前行所对应窗口的第N条数据的值。 |
| 其它 | CLUSTER_SAMPLE | 用户随机抽样。返回True表示该行数据被抽中。 |
| 其它 | STDDEV | 计算总体标准差。是STDDEV_POP的别名。 |
| 其它 | STDDEV_SAMP | 计算样本标准差。 |
1、聚合函数
SUM:对窗口中的数据求和。
--计算汇总值
DECIMAL|DOUBLE|BIGINT sum(<colname>)
--计算窗口中expr之和
sum([distinct] <expr>) over ([partition_clause] [orderby_clause] [frame_clause])
-- 聚合函数
select name,sum(distinct age),sum(*) from emp group by name;
-- 开窗函数
select deptno, sal, sum(sal) over (partition by deptno) from emp;
COUNT:计算窗口中的记录数。
-- 计算记录数
bigint count([distinct|all] <colname>)
--计算窗口中的记录数
bigint count(*) over ([partition_clause] [orderby_clause] [frame_clause])
bigint count([distinct] <expr>[,...]) over ([partition_clause] [orderby_clause] [frame_clause])
-- 聚合函数
select name,count(DISTINCT age),count(*) from emp group by name;
-- 开窗函数(指定薪水(sal)为开窗列,不排序,返回当前窗口(相同sal)的从开始行到最后一行的累计计数值。)
select sal, count(sal) over (partition by sal) as count from emp;
AVG:对窗口中的数据求平均值。
--计算平均值
decimal|double avg(<colname>)
--计算窗口中expr的平均值。
double avg([distinct] double <expr>) over ([partition_clause] [orderby_clause] [frame_clause])
decimal avg([distinct] decimal <expr>) over ([partition_clause] [orderby_clause] [frame_clause])
-- 聚合函数
select name,avg(DISTINCT age),avg(*) from emp group by name;
-- 开窗函数(指定部门(deptno)为开窗列,计算薪水(sal)平均值,不排序,返回当前窗口(相同deptno)从开始行到最后一行的累计平均值。)
select deptno, sal, avg(sal) over (partition by deptno) from emp;
MAX:计算窗口中的最大值。
--计算最大值
max(<colname>)
--计算窗口中的最大值
max(<expr>) over([partition_clause] [orderby_clause] [frame_clause])
- colname值为
NULL时,该行不参与计算。 - colname为
BOOLEAN类型时,不允许参与运算。
-- 聚合函数
select name,max(age), from emp group by name;
-- 开窗函数()
select deptno, sal, max(sal) over (partition by deptno) from emp;
MIN:计算窗口中的最小值。
--计算最小值
min(<colname>)
--计算窗口中的最小值
min(<expr>) over([partition_clause] [orderby_clause] [frame_clause])
-- 聚合函数
select name,MIN(age), from emp group by name;
-- 开窗函数
SELECT deptno, sal, MIN(sal) OVER (partition by deptno) FROM emp;
MEDIAN:计算窗口中的中位数。
--计算中位数
double median(double <colname>)
decimal median(decimal <colname>)
--计算窗口中expr的中位数。
median(<expr>) over ([partition_clause] [orderby_clause] [frame_clause])
-- 聚合函数(对所有职工按照部门(deptno)进行分组,计算各部门员工的薪资(sal)中位数。)
select deptno, median(sal) from emp group by deptno;
-- 开窗函数(指定部门(deptno)为开窗列,计算薪水(sal)中位数,返回当前窗口(相同deptno)的中位数。)
select deptno, sal, median(sal) over (partition by deptno) from emp;
2、排序函数
PERCENT_RANK和CUME_DIST差异:
| 特性 | CUME_DIST | PERCENT_RANK |
|---|---|---|
| 值域范围 | (0, 1] | [0, 1] |
| 第一名值 | 不一定是0,视重复值情况而定 | 一定是0 |
| 相同值处理 | 相同值有相同的CUME_DIST | 相同值有相同的PERCENT_RANK |
| 排名参考 | 小于等于当前行的个数 | 排名序号(rank) |
| 使用场景 | 比如计算某个值落入前X%的分布 | 比如计算排名在组内的相对百分比 |
| 计算差异(23行):首行 | 1/2 =0.0436 | (1-1)/(23-1)=0 |
| 计算差异(23行):第2行 | 2/23=0.0870 | (2-1)/(23-1)=0.0456 |
ROW_NUMBER:计算行号。从1开始递增(1,2,3,4)。
row_number() over([partition_clause] [orderby_clause])
SELECT name
,age
,address
,ROW_NUMBER() OVER( PARTITION BY name,age,addressORDER BY etl_time DESC ) AS rn
FROM user_info
RANK:计算排名。排名可能不连续(1, 2, 2, 4)。- RANK是一个窗口函数,用于为结果集中的行分配排名值。
- 相同值的行会获得相同排名,且后续排名会跳过并列的序号(例如:1, 2, 2, 4),因此排名可能不连续。
bigint rank() over ([partition_clause] [orderby_clause])
SELECT name
,age
,address
,rank() OVER( PARTITION BY name,age,addressORDER BY etl_time DESC ) AS rn
FROM user_info
DENSE_RANK:计算排名。排名是连续的(1, 2, 2, 3)。
bigint dense_rank() over ([partition_clause] [orderby_clause])
SELECT name
,age
,address
,DENSE_RANK() OVER( PARTITION BY name,age,addressORDER BY etl_time DESC ) AS rn
FROM user_info
PERCENT_RANK:计算排名。输出百分比格式。
double percent_rank() over([partition_clause] [orderby_clause])
-- 计算员工薪水在组内的百分比排名
select deptno, ename, sal
,percent_rank() over (partition by deptno order by sal desc) as sal_new
from emp;
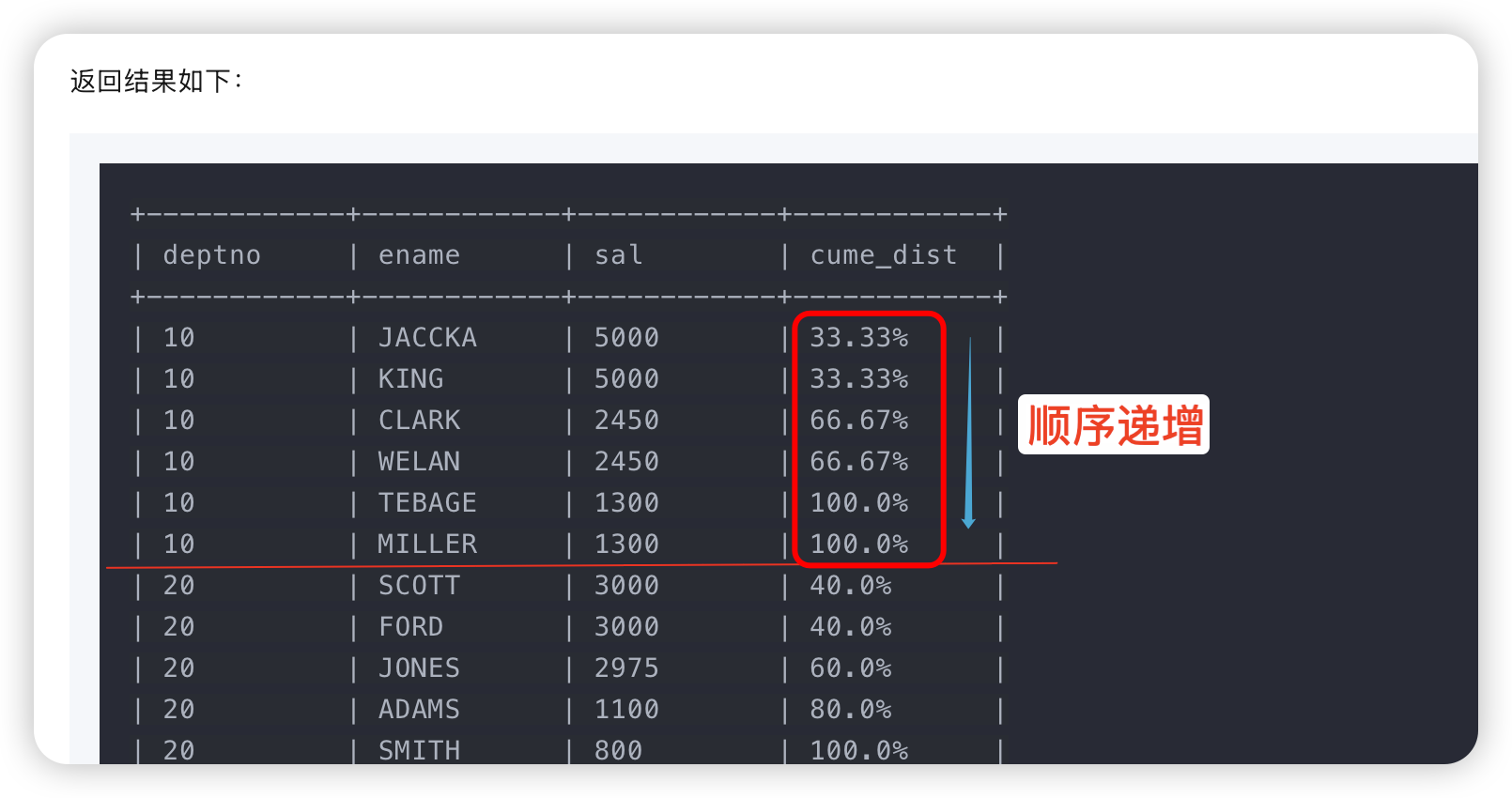
CUME_DIST:计算累计分布。- 求累计分布,相当于求分区中大于等于当前行的数据在分区中的占比。
double cume_dist() over([partition_clause] [orderby_clause])
-- 将所有职工根据部门(deptno)分组(作为开窗列),计算薪水(sal)在同一组内的前百分之几。
select deptno, ename, sal
,cume_dist() over (partition by deptno order by sal desc) as cume_dist
from emp;
NTILE:将数据顺序切分成N等份,返回数据所在等份的编号(从1到N)。- 用于将分区中的数据按照顺序切分成N等份,并返回数据所在等份的编号。
- 如果分区中的数据不能被均匀地切分成N等份时,最前面的等份(编号较小的)会优先多分配1条数据。
bigint ntile(bigint <N>) over ([partition_clause] [orderby_clause])
-- 将所有职工根据部门按薪水(sal)从高到低切分为3组,并获得职工自己所在组的序号。
select deptno, ename, sal
, ntile(3) over (partition by deptno order by sal desc) as nt3
from emp;
3、统计比较
FIRST_VALUE:取当前行所对应窗口的第一条数据的值。
first_value(<expr>[, <ignore_nulls>]) over ([partition_clause] [orderby_clause] [frame_clause])
-- 将所有职工根据部门分组,返回每组中第一条数据
select deptno, ename, sal
, first_value(sal) over (partition by deptno order by sal desc) as first_value
from emp;
LAST_VALUE:取当前行所对应窗口的最后一条数据的值。
last_value(<expr>[, <ignore_nulls>]) over([partition_clause] [orderby_clause] [frame_clause])
-- 将所有职工根据部门分组,返回每组中最后一条数据
select deptno, ename, sal
,last_value(sal) over (partition by deptno order by sal desc) as first_value
from emp;
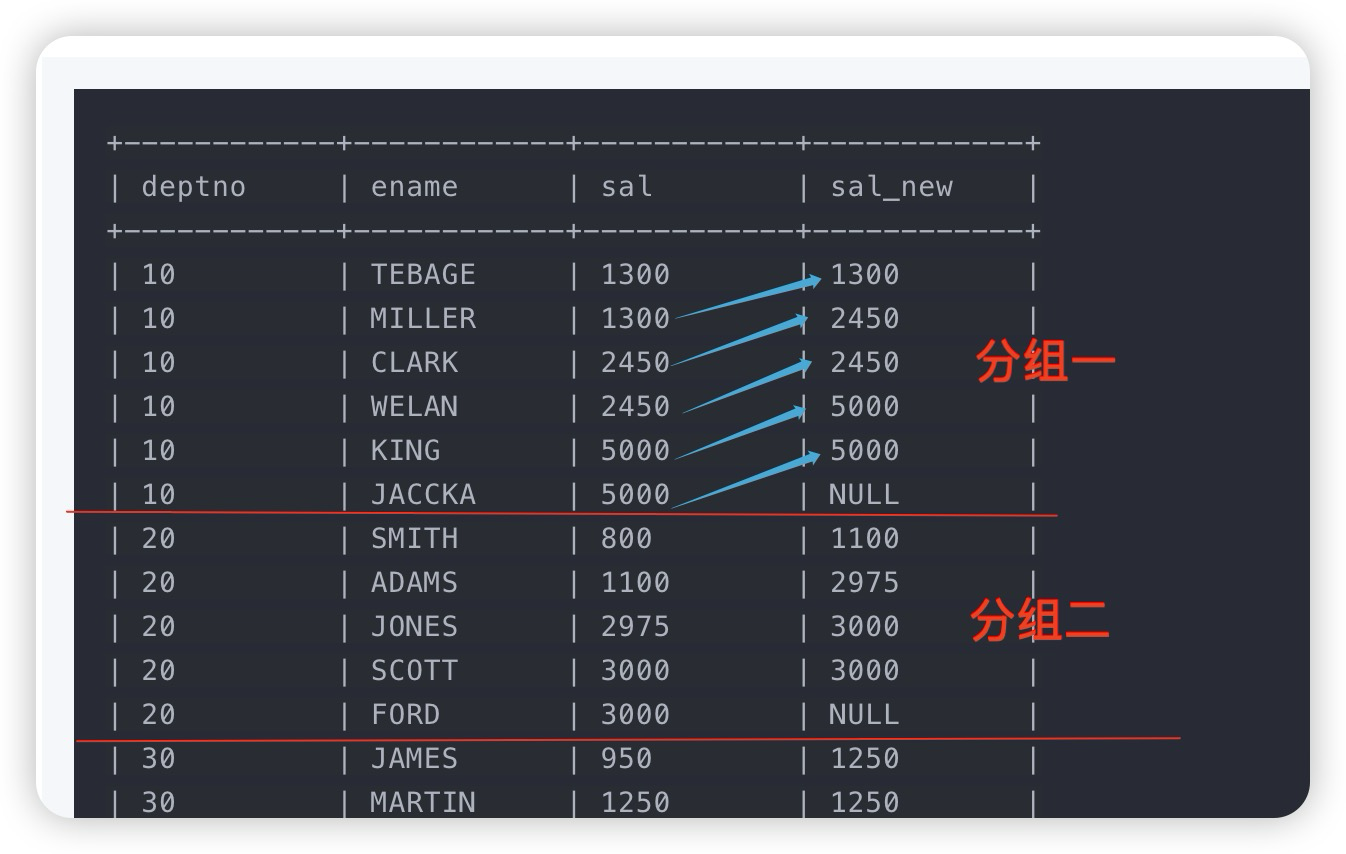
LEAD:取当前行往后(朝分区尾部方向)第N行数据的值。
lead(<expr>[, bigint <offset>[, <default>]]) over([partition_clause] orderby_clause)
-- 将所有职工根据部门(deptno)分组(作为开窗列),每位员工的薪水(sal)做偏移
select deptno, ename, sal, lead(sal, 1) over (partition by deptno order by sal) as sal_new from emp;
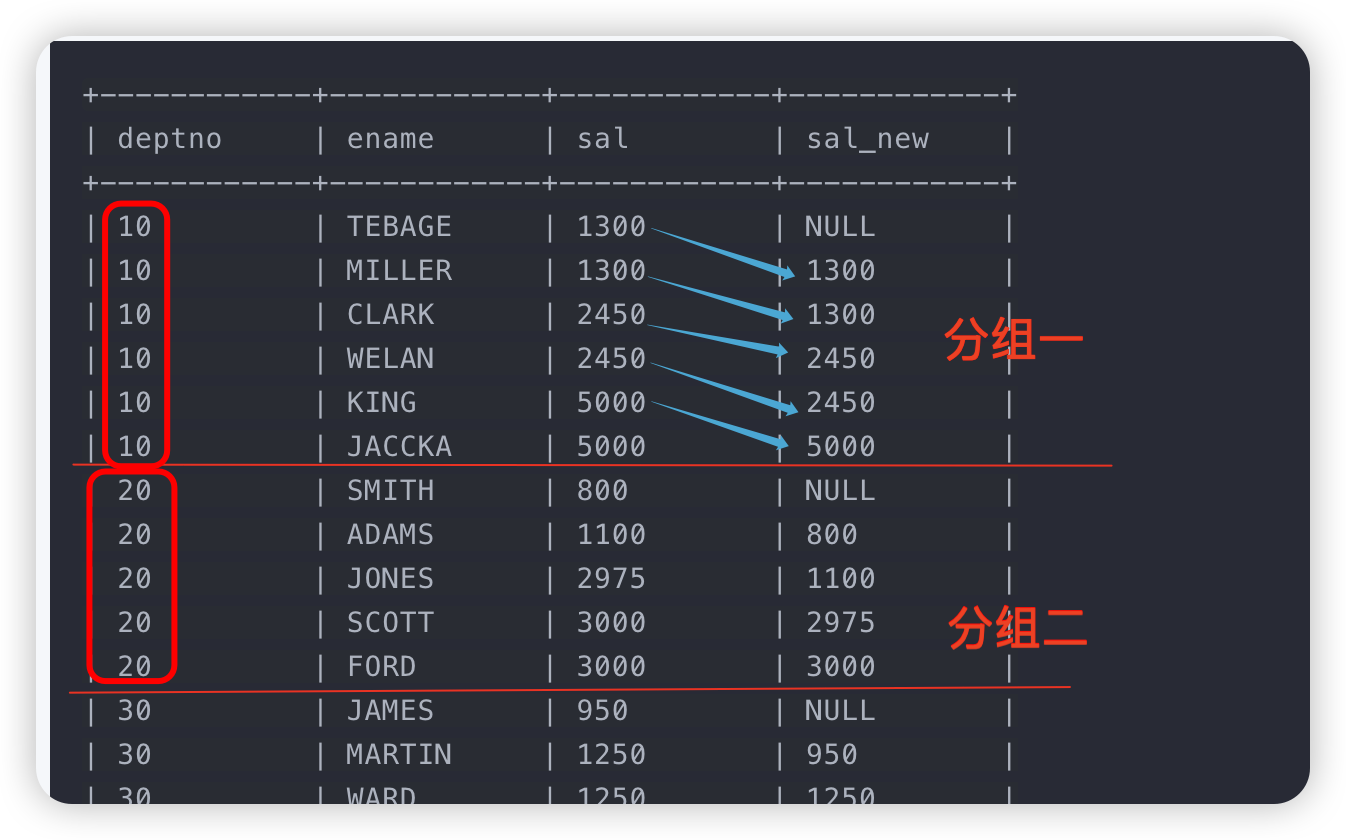
LAG:取当前行往前(朝分区头部方向)第N行数据的值。
lag(<expr>[, bigint <offset>[, <default>]]) over([partition_clause] orderby_clause)
-- 将所有职工根据部门(deptno)分组(作为开窗列),每位员工的薪水(sal)做偏移
select deptno, ename, sal
, lag(sal, 1) over (partition by deptno order by sal) as sal_new
from emp;
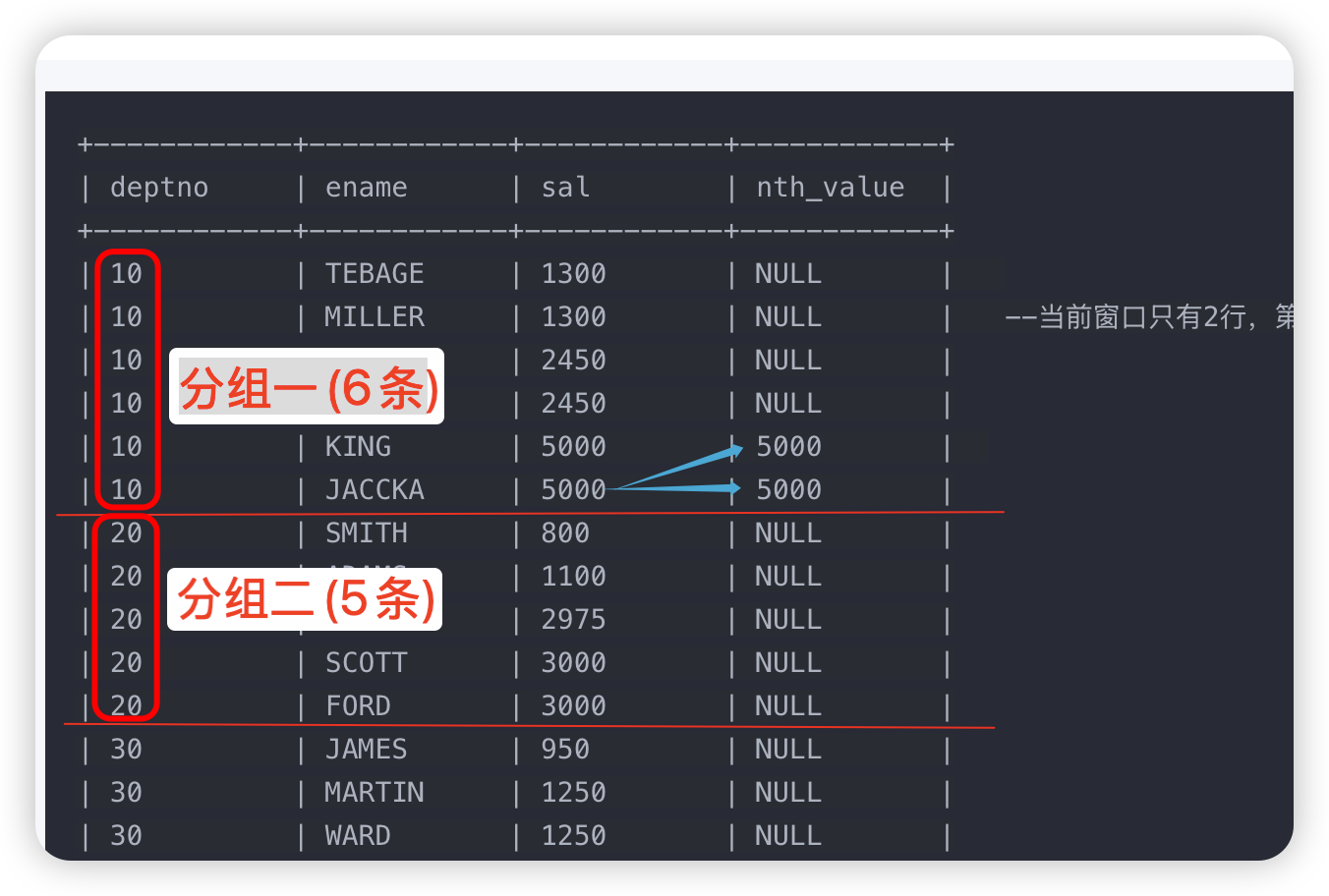
NTH_VALUE:取当前行所对应窗口的第N条数据的值。
nth_value(<expr>, <number> [, <ignore_nulls>]) over ([partition_clause] [orderby_clause] [frame_clause])
-- 将所有职工根据部门分组,返回每组中的第6行数据。
select deptno, ename, sal
, nth_value(sal,6) over (partition by deptno order by sal) as nth_value
from emp;
4、其它
CLUSTER_SAMPLE:用户随机抽样。返回True表示该行数据被抽中。
boolean cluster_sample(bigint <N>) OVER ([partition_clause])
boolean cluster_sample(bigint <N>, bigint <M>) OVER ([partition_clause])
cluster_sample(bigint <N>):表示随机抽取N条数据。cluster_sample(bigint <N>, bigint <M>):表示按比例(M/N)随机抽取。即抽取partition_row_count×M / N条数据。partition_row_count指分区中的数据行数。
select deptno, sal
-- 随机抽取5条数据
, cluster_sample(5) over () as flag
-- 随机抽取约20%的值
, cluster_sample(5, 1) over () as flag
-- 从每组中抽取约20%的值
, cluster_sample(5, 1) over (partition by deptno) as flag
from emp;
STDDEV:计算总体标准差。是STDDEV_POP的别名。
--计算总体标准差
double stddev(double <colname>)
decimal stddev(decimal <colname>)
--计算窗口中expr的总体标准差
double stddev|stddev_pop([distinct] <expr>) over ([partition_clause] [orderby_clause] [frame_clause])
decimal stddev|stddev_pop([distinct] <expr>) over ([partition_clause] [orderby_clause] [frame_clause])
-- 计算所有职工的薪资(sal)的总体标准差。
select stddev(sal) from emp;
-- 与group by配合使用,对所有职工按照部门(deptno)进行分组,计算各部门员工的薪资(sal)总体标准差。
select deptno, stddev(sal) from emp group by deptno;
-- 指定部门(deptno)为开窗列,计算薪水(sal)总体标准差,不排序,返回当前窗口(相同deptno)的累计总体标准差。
select deptno, sal, stddev(sal) over (partition by deptno) from emp;
STDDEV_SAMP:计算样本标准差。
--计算样本标准差
double stddev_samp(double <colname>)
decimal stddev_samp(decimal <colname>)
--计算窗口中expr的标准差
double stddev_samp([distinct] <expr>) over([partition_clause] [orderby_clause] [frame_clause])
decimal stddev_samp([distinct] <expr>) over([partition_clause] [orderby_clause] [frame_clause])
-- 指定部门(deptno)为开窗列,计算薪水(sal)样本标准差,不排序,返回当前窗口(相同deptno)的累计样本标准差。
select deptno, sal, stddev_samp(sal) over (partition by deptno) from emp;
-- 指定部门(deptno)为开窗列,计算薪水(sal)样本标准差,并排序,返回当前窗口(相同deptno)从开始行到当前行的累计样本标准差。
select deptno, sal, stddev_samp(sal) over (partition by deptno order by sal) from emp;
-- 计算所有职工的薪资(sal)的样本标准差。
select stddev_samp(sal) from emp;
-- 与group by配合使用,对所有职工按照部门(deptno)进行分组,计算各部门员工的薪资(sal)样本标准差。
select deptno, stddev_samp(sal) from emp group by deptno;


















 1889
1889

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











