






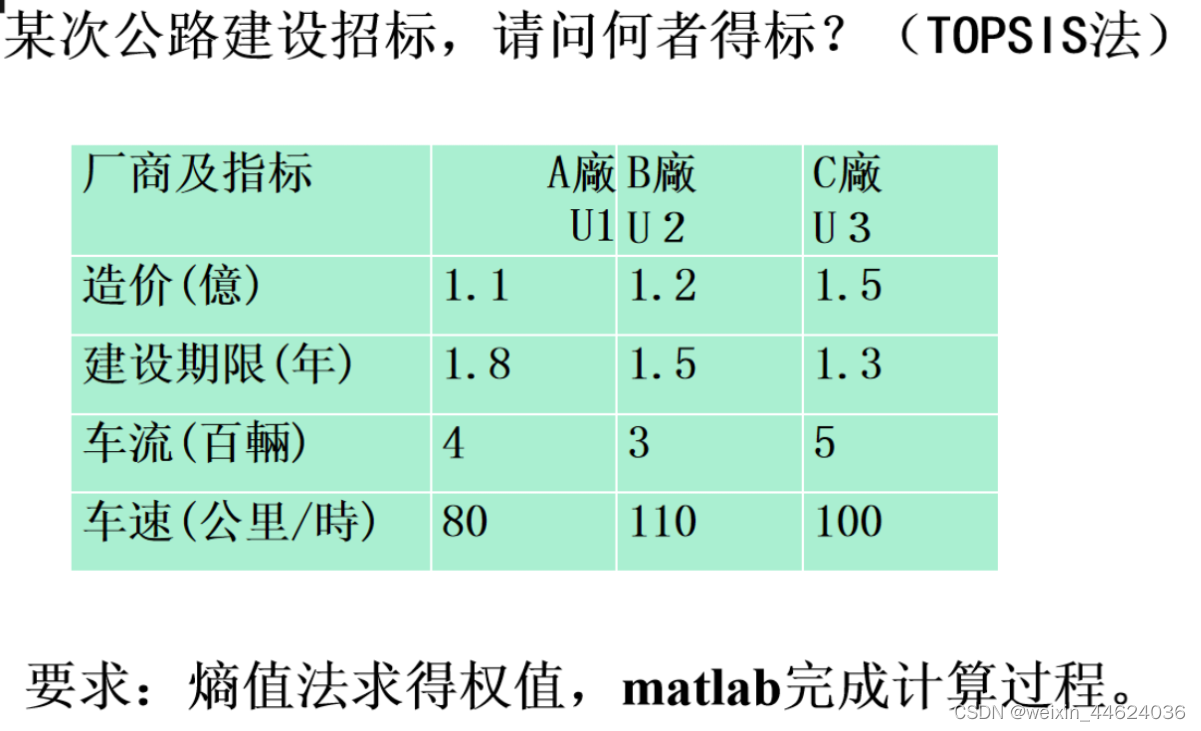
解:
- 定义该方案的决策矩阵
X
X
X:
X = [ 1.1 1.8 4 80 1.2 1.5 3 110 1.5 1.3 5 100 ] X=\left[ \begin{matrix} 1.1& 1.8& 4& 80\\ 1.2& 1.5& 3& 110\\ 1.5& 1.3& 5& 100\\ \end{matrix} \right] X= 1.11.21.51.81.51.343580110100
其中,造价和建设年限为负向指标,车流和车速为正向指标。
采用熵值法确定各指标权重:
-
采用线性比例变换法求决策矩阵的标准化矩阵 Y 1 Y_1 Y1:
Y 1 = [ 1.0000 0.7222 0.8000 0.7273 0.9167 0.8667 0.6000 1.0000 0.7333 1.0000 1.0000 0.9091 ] Y_1=\left[ \begin{matrix} 1.0000& 0.7222& 0.8000& 0.7273\\ 0.9167& 0.8667& 0.6000& 1.0000\\ 0.7333& 1.0000& 1.0000& 0.9091\\ \end{matrix} \right] Y1= 1.00000.91670.73330.72220.86671.00000.80000.60001.00000.72731.00000.9091 -
采用熵值法求解权重,对矩阵 Y 1 Y_1 Y1进行归一化处理,计算归一化矩阵 P P P:
P = [ 0.3774 0.2790 0.3333 0.2759 0.3459 0.3348 0.2500 0.3793 0.2767 0.3863 0.4167 0.3448 ] P=\left[ \begin{matrix} 0.3774& 0.2790& 0.3333& 0.2759\\ 0.3459& 0.3348& 0.2500& 0.3793\\ 0.2767& 0.3863& 0.4167& 0.3448\\ \end{matrix} \right] P= 0.37740.34590.27670.27900.33480.38630.33330.25000.41670.27590.37930.3448 -
计算熵值 e e e(取 k = 0.5 k=0.5 k=0.5):
e = [ 0.5452 0.5450 0.5388 0.5451 ] e=\left[ \begin{matrix} 0.5452& 0.5450& 0.5388& 0.5451\\ \end{matrix} \right] e=[0.54520.54500.53880.5451] -
计算差异系数 g g g:
g = [ 0.4548 0.4550 0.4612 0.4549 ] g=\left[ \begin{matrix} 0.4548& 0.4550& 0.4612& 0.4549\\ \end{matrix} \right] g=[0.45480.45500.46120.4549] -
计算权重 w w w:
w = [ 0.2491 0.2492 0.2526 0.2492 ] w=\left[ \begin{matrix} 0.2491& 0.2492& 0.2526& 0.2492\\ \end{matrix} \right] w=[0.24910.24920.25260.2492]
采用**理想解法(TOPSIS)**确定最有方案:
-
采用向量归一化法求决策矩阵的标准化矩阵 Y 2 Y_2 Y2:
Y 2 = [ 0.4969 0.6718 0.5657 0.4739 0.5421 0.5598 0.4243 0.6516 0.6776 0.4852 0.7071 0.5923 ] Y2=\left[ \begin{matrix} 0.4969& 0.6718& 0.5657& 0.4739\\ 0.5421& 0.5598& 0.4243& 0.6516\\ 0.6776& 0.4852& 0.7071& 0.5923\\ \end{matrix} \right] Y2= 0.49690.54210.67760.67180.55980.48520.56570.42430.70710.47390.65160.5923 -
计算加权标准化矩阵 V V V:
V = [ 0.1238 0.1674 0.1429 0.1181 0.1350 0.1395 0.1072 0.1623 0.1688 0.1209 0.1786 0.1476 ] V=\left[ \begin{matrix} 0.1238& 0.1674& 0.1429& 0.1181\\ 0.1350& 0.1395& 0.1072& 0.1623\\ 0.1688& 0.1209& 0.1786& 0.1476\\ \end{matrix} \right] V= 0.12380.13500.16880.16740.13950.12090.14290.10720.17860.11810.16230.1476
- 确定理想解 V ∗ V^* V∗和负理想解 V − V^- V−:
V ∗ = [ 0.1238 0.1209 0.1786 0.1623 ] V − = [ 0.1688 0.1674 0.1072 0.1181 ] V^*=\left[ \begin{matrix} 0.1238& 0.1209& 0.1786& 0.1623\\ \end{matrix} \right] \\ V^-=\left[ \begin{matrix} 0.1688& 0.1674& 0.1072& 0.1181\\ \end{matrix} \right] V∗=[0.12380.12090.17860.1623]V−=[0.16880.16740.10720.1181]
-
计算各方案到理想解和负理想解的距离 S ∗ S^* S∗和 S − S^- S−:
S ∗ = [ 0.0735 0.0747 0.0474 ] S − = [ 0.0575 0.0623 0.0902 ] S^*=\left[ \begin{matrix} 0.0735\\ 0.0747\\ 0.0474\\ \end{matrix} \right] \\ S^-=\left[ \begin{matrix} 0.0575\\ 0.0623\\ 0.0902\\ \end{matrix} \right] S∗= 0.07350.07470.0474 S−= 0.05750.06230.0902 -
计算各方案的相对贴近度 C C C:
C = [ 0.4388 0.4547 0.6557 ] C=\left[ \begin{matrix} 0.4388\\ 0.4547\\ 0.6557\\ \end{matrix} \right] C= 0.43880.45470.6557 -
找出相对贴近度最大的方案 i b e s t i_{best} ibest:
i b e s t = 3 i_{best}=3 ibest=3
方案 3 3 3的相对贴近度最大,故选择方案 3 3 3,即 C C C厂应该中标。
附:matlab代码
%% 定义该方案的决策矩阵:
X = [1.1,1.8,4,80;
1.2,1.5,3,110;
1.5,1.3,5,100];
%% 采用线性比例变换法求决策矩阵的向量归一标准化矩阵Y1:
Y1 = [min(X(:,1:2)) ./ X(:,1:2),X(:,3:4) ./ max(X(:,3:4))];
% 对矩阵Y1进行归一化处理,计算归一化矩阵P:
P = Y1 ./ sum(Y1,1);
% 计算熵值e:
e = -0.5 * sum(P .* log(P));
% 计算差异系数g:
g = 1 - e;
% 计算权重w:
w = g / sum(g);
%% 采用向量归一化法求决策矩阵的标准化矩阵Y2:
Y2 = X ./ sqrt(sum(X.^2));
% 计算加权标准化矩阵V:
V = w .* Y2;
% 确定理想解V1和负理想解V0:
V1 = [min(V(:,1:2)),max(V(:,3:4))];
V0 = [max(V(:,1:2)),min(V(:,3:4))];
% 计算各方案到理想解和负理想解的距离S1和S0:
S1 = sqrt(sum((V - V1).^2,2));
S0 = sqrt(sum((V - V0).^2,2));
% 计算各方案的相对贴近度C:
C = S0 ./ (S0 + S1);
% 找出相对贴近度最大的方案ibest:
ibest = find(C == max(C));
线性比例变换法和向量归一化法是数据标准化的两种不同方法,各有其特点和应用场景。以下是它们的区别和各自的优缺点:
线性比例变换法
定义:
线性比例变换法(Min-Max Normalization)通过将数据按比例缩放到指定范围(通常是0到1)。
公式:
[ X’ = \frac{X - X_{min}}{X_{max} - X_{min}} ]
优点:
- 保留了原始数据的分布形状。
- 易于理解和实现。
- 适用于数据范围已知且固定的情况。
缺点:
- 对于存在异常值(outliers)的数据,缩放效果会受到极端值的影响。
- 仅适用于线性变化,不适合非线性分布的数据。
向量归一化法
定义:
向量归一化法(Vector Normalization)通过将每个样本的数据标准化为单位向量,即每个样本的各个特征值的平方和为1。
公式:
[ X’ = \frac{X}{\sqrt{\sum X^2}} ]
优点:
- 适用于在同一数量级上的数据。
- 减少了因不同数量级数据引起的影响,保留了方向信息。
- 对于大数据集,计算效率较高。
缺点:
- 对于数据本身的分布没有特别考虑,所有特征都被缩放到单位向量。
- 对于稀疏数据(大多数特征值为0),效果较差。
为什么在这里一个用线性比例变换法,一个用向量归一化法?
在上述决策模型中,采用了线性比例变换法和向量归一化法是基于不同的需求和标准化目的:
-
线性比例变换法:
目的是为了计算权重。在计算权重时,我们需要使用线性比例变换法将数据归一化到0到1的范围内,以便于计算熵值和差异系数。线性比例变换法在这里的优点是能保持数据的比例关系,有利于权重的合理分配。 -
向量归一化法:
目的是为了进行TOPSIS分析。在TOPSIS分析中,向量归一化法将数据标准化为单位向量,确保所有特征在同一数量级上,减少数量级差异对结果的影响。这样可以更有效地计算各方案到理想解和负理想解的距离。
综合应用
综合权重的计算和TOPSIS分析的标准化方法选择,分别采用线性比例变换法和向量归一化法,可以在保留数据原有比例关系的同时,确保不同特征之间的数量级一致性,从而得到更准确和合理的决策结果。


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











