







 本章深入探讨Python的结构化类型,包括元组、范围、列表及其可变性。重点介绍了元组的用法,列表的不可变性,以及如何克隆和使用列表推导。同时,讲解了函数作为一等对象的特性,如高阶函数map的运用。此外,还阐述了字符串、元组、范围和列表的异同,以及字典的使用,强调字典的无序性和键的可散列性要求。
本章深入探讨Python的结构化类型,包括元组、范围、列表及其可变性。重点介绍了元组的用法,列表的不可变性,以及如何克隆和使用列表推导。同时,讲解了函数作为一等对象的特性,如高阶函数map的运用。此外,还阐述了字符串、元组、范围和列表的异同,以及字典的使用,强调字典的无序性和键的可散列性要求。
typora-copy-images-to: Python 编程导论
文章目录
Python 编程导论 Chapter 5 —— 结构化类型、可变性与高阶函数
-
python的标准库中拥有一个小的内建类型集合,用来处理数值数据、字符串、布尔值以及日期和时间。这类的‘单值’类型有时候被称为标量类型
-
int、float 是标量类型,这种类型的对象没有可以访问的内部结构
-
str 是一种结构化的非标量的类型,我们可以使用索引提取单个字符,也可以通过分片操作获取子字符串
-
本章会介绍其他的3种——list、range、dict
5.1 元组
-
元组:是一些元素的不可变有序序列
-
元组中的元素不一定是字符,单个元素可以是任意类型
-
要想表示包含 1 的单元素元组,我们应该写成 (1,)
t1 = (1, 'two', 3)
t2 = (t1, 3.25, 1, 'two')
# 返回一个元组,包含t1 和 t2的公约数
def intersect(t1, t2):
result = ()
for e in t1:
if e in t2:
result += (e,)
return result
print(intersect(t1,t2))
- 序列和多重赋值
- 如果你知道一个序列(元组字符串)的长度,那么可以使用Python中的多重赋值语句方便地
提取单个元素
x, y = (3, 4)
# x 被绑定到3 , y 会被绑定到 4
a, b, c = 'xyz'
# a被绑定到x ,b被绑定到y,c被绑定到z
def findExtremeDivisors(n1, n2) :
"""假设n1和n2是正整数
返回一个元组,包含n1和n2的最小公约数和最大公约数,最小公约数大于1,
如果没有公约数,返回(None,None)"""
minVal, maxVal = None, None
for i in range(2,min(n1,n2) + 1) : # 必须加1,因为不然不包含了,遍历从2开始
if n1%i == 0 and n2%i == 0 : #余数都为0的情况下,判断minVal是否有值,如果没有值,则加入minVal,否则成为maxVal
if minVal == None :
minVal = i
maxVal = i
return (minVal, maxVal)
5.2 范围
- range 函数的三个参数,start 、 stop 、step
- range(0, 7, 2) == range(0, 8, 2) 的值就是 True ,但 range(0, 7, 2) == range(6, -1, -2) 的值则是 False,虽然包含同样的整数,但是顺序不同
5.3 列表与可变性
L = ['I did it all', 4, 'love']
for i in range(len(L)):
print(L[i])
# 输入为:
I did it all
4
love
# 中括号还可以用于表示 list 类型字面量、列表索引和列表切片
表达式 [1, 2, 3, 4][1:3][1]
# 输出为 3
- 列表和元组的区别在于元组不可变
- 注意使对象发生变化以及将对象赋给变量是不同的,变量仅仅是一个名称,在python中就是贴在对象上的标签
Techs = ['MIT', 'Caltech']
Ivys = ['Harvard', 'Yale', 'Brown']
Univs = [Techs, Ivys]
Univs1 = [['MIT', 'Caltech'], ['Harvard', 'Yale', 'Brown']]
Techs.append('RPI')
# append 方法具有副作用。它不创建一个新列表,而是通过向列表 Techs 的末尾添加一个新元素——字符串 'RPI' ——改变这个已有的列表
# 当一个列表追加到另一个列表时,append 会保持原来的结构,列表的联结操作,使用extend函数
L1 = [1,2,3]
L2 = [4,5,6]
L3 = L1 + L2
print('L3 =', L3)
L1.extend(L2)
print('L1 =', L1)
L1.append(L2)
print('L1 =', L1)
# 会输出:
L3 = [1, 2, 3, 4, 5, 6]
L1 = [1, 2, 3, 4, 5, 6]
L1 = [1, 2, 3, 4, 5, 6, [4, 5, 6]]
# 操作符 + 确实没有副作用,它会创建并返回一个新的列表。相反, extend 和 append都会改变 L1

5.3.1 克隆
- 我们通常应该尽量避免修改一个正在进行遍历的列表
def removeDups(L1, L2):
"""假设L1和L2是列表,
删除L2中出现的L1中的元素"""
for e1 in L1:
if e1 in L2:
L1.remove(e1)
L1 = [1,2,3,4]
L2 = [1,2,5,6]
removeDups(L1, L2)
print('L1 =', L1)
# 修改了列表,改变了索引,因此,结果会出错
避免这种问题的方法是使用切片操作克隆(即复制)这个列表,并使用 for e1 in L1[:]这种写法
5.3.2 列表推导
L = [x**2 for x in range(1,7)]
print(L)
output : [1, 4, 9, 16, 25, 36]
mixed = [1, 2, 'a', 3, 4.0]
print([x**2 for x in mixed if type(x) == int])
# 列表推导中的 for 从句后面可以有一个或多个 if 语句和 for 语句
5.4 函数对象
- 函数是一等对象,可以出现在表达式中,如作为赋值语句的右侧项或作为函数的实参;函数可
以是列表中的元素 - 使用函数作为实参可以实现一种名为高阶编程的编码方式:
def applyToEach(L,f):
"""假设L是列表,f是函数
将f(e)应用到L的每个元素,并用返回值替换原来的元素"""
for i in range(len(L)):
L[i] = f(L[i])
# 对列表L中的每一个元素,都套用f的函数
L = [1, -2, 3.33]
print('L =', L)
print('Apply abs to each element of L.') # 绝对值
applyToEach(L, abs)
print('L =', L)
print('Apply int to each element of', L) # 整数
applyToEach(L, int)
print('L =', L)
print('Apply factorial to each element of', L) # 阶乘
applyToEach(L, factR)
print('L =', L)
print('Apply Fibonnaci to each element of', L) # 斐波那契
applyToEach(L, fib)
print('L =', L)
- Python 中有一个内置的高阶函数MAP
- map 函数被设计为与 for 循环结合使用
for i in map(fib, [2, 6, 4]):
print(i)
L1 = [1, 28, 36]
L2 = [2, 57, 9]
for i in map(min, L1, L2):
print(i)
# map 的第一个参数可以是具有n个参数的函数, 在这种情况下,它后面必须跟随着n个有序集合(这些集合的长度都一样)
- Python 还支持匿名函数,即没有绑定名称的函数,使用保留字lambda
lambda <sequence of variable names>: <expression>
# lambda 会返回一个函数,表达式经常用作高阶函数的参数
L = []
for i in map(lambda x, y: x**y, [1 ,2 ,3, 4], [3, 2, 1, 0]):
L.append(i)
print(L) # 返回x的y平方
5.5 字符串、元组、范围与列表
-
四种不同的序列类型:str、tuple、range、list
-
以下是异同,以及通用的操作:
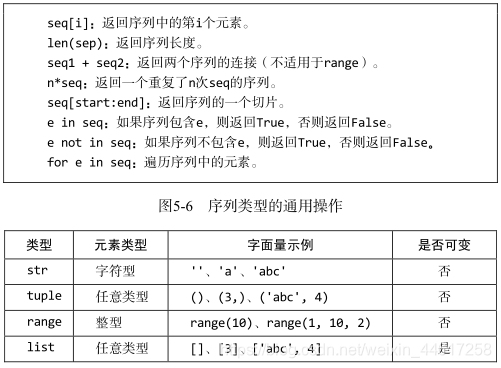
-
元组的优势:
- 不可变的,因此别名对它来说不是什么问题
- 可以作为字典中的键
-
字符串的内置方法举例:字符串是不可改变的,因此以下方法都只返回一个值:

- split 是比较重要的内置方法之一,使用两个字符串作为参数
print('My favorite professor--John G.--rocks'.split(' '))
print('My favorite professor--John G.--rocks'.split('-'))
print('My favorite professor--John G.--rocks'.split('--'))
输出:
['My', 'favorite', 'professor--John', 'G.--rocks']
['My favorite professor', '', 'John G.', '', 'rocks']
['My favorite professor', 'John G.', 'rocks']
第二个参数可选,如果省略,则使用任意空白字符组成的字符串拆分第一个字符串
5.6 字典
- 将字典看作一个键/值对的集合
- 元素编写方法是键加冒号再加上值
monthNumbers = {'Jan':1, 'Feb':2, 'Mar':3, 'Apr':4, 'May':5,
1:'Jan', 2:'Feb', 3:'Mar', 4:'Apr', 5:'May'}
print('The third month is ' + monthNumbers[3])
dist = monthNumbers['Apr'] - monthNumbers['Jan']
print('Apr and Jan are', dist, 'months apart')
输出:
The third month is Mar
Apr and Jan are 3 months apart
# 增加一个项目
monthNumbers['June'] = 6
# 改变一个项目
monthNumbers['May'] = 'V'
# 列出所有的键
monthNumbers = {'Jan':1, 'Feb':2, 'Mar':3, 'Apr':4, 'May':5,
1:'Jan', 2:'Feb', 3:'Mar', 4:'Apr', 5:'May'}
keys = []
for e in monthNumbers:
keys.append(str(e))
print(keys)
keys.sort()
print(keys)
-
dict中的项目是无序的,不能通过索引引用,这就是为什么 monthNumbers[1] 确定无疑地指
向键为 1 的项目,而不是第二个项目 -
字典是可变的
-
并非所有的对象都可以用作字典键:键必须是一个可散列类型的对象。如果一个类型具有以下
两条性质,就可以说它是“可散列的”:- 具有__ hash __ 方法,可以将一个这种类型的对象映射为一个 int 值,而且对于每一个对象,
由 hash 返回的值在这个对象的生命周期中是不变的; - 具有__ eq __ 方法,可以比较两个对象是否相等
- 具有__ hash __ 方法,可以将一个这种类型的对象映射为一个 int 值,而且对于每一个对象,
-
常用的字典操作:



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









