







HyCoRec: Hypergraph-Enhanced Multi-Preference Learning for Alleviating Matthew Effect in CRS 论文阅读
文章信息:

发表于:ACL 2024
原文链接:https://aclanthology.org/2024.acl-long.138/
源码:https://github.com/zysensmile/HyCoRec
Abstract
马太效应(Matthew Effect)是推荐系统(RSs)中一个众所周知的问题,即“富者愈富,贫者愈贫”,其中热门商品被过度曝光,而不太受欢迎的商品则经常被忽视。大多数方法在静态或接近静态的推荐场景中研究马太效应。然而,当用户与系统进行交互时,马太效应会随着时间的推移而不断放大。为了解决这些问题,我们提出了一种新的范式,即基于超图增强的多偏好学习以缓解对话式推荐中的马太效应(HyCoRec),旨在减轻对话式推荐中的马太效应。具体而言,HyCoRec致力于通过学习多方面的偏好(即商品、实体、词汇、评论和知识方面的偏好)来缓解马太效应,从而在用户与系统进行对话时,有效地生成对话任务中的响应,并在推荐任务中准确预测商品。在两个基准数据集上进行的大量实验验证了HyCoRec在缓解马太效应方面取得了新的最先进性能,并展示了其优越性。
1 Introduction
对话式推荐系统(Conversational Recommender Systems, CRSs)通过与用户进行迭代对话来提供个性化推荐(Qin等,2023;Li等,2023;Mishra等,2023),这一技术已被广泛应用于多个领域,如音乐推荐(Epure和Hennequin,2023)和在线电子商务(Liu等,2023)。然而,CRSs常常面临一个显著的问题,即马太效应(Liu和Huang,2021),这种现象可以描述为“富者愈富,贫者愈贫”。这表明,在过去数据中受欢迎的商品或类别在后续推荐中获得更多的曝光,而较不受欢迎的商品或类别则往往被忽视或忽略。
近来,许多研究致力于在静态或相对静态的离线推荐场景中探讨马太效应(Liu和Huang,2021;Anderson等,2020;Hansen等,2021)。这些离线研究努力挖掘马太效应显现背后的潜在原因,并已识别出两个关键因素。其中一个原因(Anderson等,2020;Hansen等,2021;Liang等,2021;Zheng等,2021a)是,那些偏好较为狭窄且缺乏多样性的个体更容易陷入马太效应的桎梏。另一个原因(Zheng等,2021b)则是严重的流行度偏差,即热门商品持续获得过度的曝光,而不太受欢迎的商品则曝光不足。尽管这些方法无疑为理解马太效应现象提供了宝贵的见解,但它们直接忽视了动态用户-系统反馈循环所带来的负面影响。最近,Gao等人(Gao等,2023)探索了动态用户-系统交互中的马太效应,但其研究缺乏通过自然语言对话实现的实时用户参与。
尽管现有方法取得了一定成效,但大多数方法仍面临两大局限。1) 交互模式。许多方法旨在静态推荐场景中缓解马太效应,而未考虑用户-系统反馈循环(Zhang等,2021)。实际上,随着用户与系统动态交互的持续,马太效应会逐渐放大。更糟糕的是,这种放大不可避免地会导致一系列严重问题,如信息茧房(Steck,2018)和回声室效应(Ge等,2020)。因此,考虑动态的用户-系统交互对于缓解马太效应至关重要。2) 偏好学习。先前的研究(Anderson等,2020;Hansen等,2021;Liang等,2021;Zheng等,2021a)表明,缓解马太效应的关键在于学习多样化的用户偏好。因此,许多方法利用多元外部知识图谱(KGs)来建模多方面的偏好。但传统知识图谱的边仅限于连接两个顶点(即因素),将偏好学习限制在成对交互中。然而,用户关系表现出复杂的多因素性,例如用户对一件服装的偏好同时涉及颜色、品牌、款式和质地等多个因素。因此,扩展顶点数量以学习多样化偏好显得尤为重要。
为了解决这些问题,我们提出了一种新范式,即基于超图增强的多偏好学习以缓解对话式推荐中的马太效应(HyCoRec)。该范式由超图增强的多偏好学习和超图感知的对话式推荐系统两部分组成。前者旨在建模多方面的偏好,具体包括商品层面、实体层面、词汇层面、评论层面和知识层面的偏好。它通过利用基于商品的超图、基于实体的超图、基于词汇的超图、商品评论和知识图谱来学习和推导这些偏好,从而缓解对话式推荐中的马太效应。后者则侧重于在用户与系统交互时利用这些多方面的偏好。具体而言,多方面的偏好被用于在对话任务中准确预测下一轮对话内容,并在推荐任务中有效生成多样化的商品预测。通过整合和利用这些多方面的偏好,系统旨在提供精准且多样化的推荐,以满足用户的个性化偏好和需求,从而在用户持续与系统交互的过程中缓解马太效应。实验结果表明,在两个基准数据集上,HyCoRec在性能上优于所有对比基线,并在缓解马太效应方面表现出显著优势。
总体而言,我们的主要贡献包括:
-
据我们所知,这是首次通过建模多方面的用户偏好(即商品层面、实体层面、词汇层面、评论层面和知识层面的偏好)来缓解对话式推荐系统中的马太效应。
-
我们提出了一种新颖的端到端框架HyCoRec,该框架采用多方面的偏好,在对话任务中有效生成响应,并在推荐任务中准确预测商品。
-
在两个基于对话式推荐系统的数据集上,定量和定性的实验结果展示了HyCoRec的优越性能及其在缓解马太效应方面的有效性。
2 Related Work
2.1 Conversational Recommender System
对话式推荐系统(Conversational Recommender System, CRS)旨在通过对话捕捉用户偏好并提供高质量的推荐。先前关于CRS的研究主要可分为两大类:基于属性的CRS(Deng等,2021a;Lei等,2020a,b;Ren等,2021;Xu等,2021)和基于生成的CRS(Chen等,2019;Deng等,2023;Li等,2022;Zhou等,2020a, 2022;Shang等,2023)。基于属性的CRS通过询问商品属性问题来捕捉用户偏好,并使用预定义模板生成响应(Lei等,2020a)。但这一策略往往忽视了生成类似自然人类语言响应的重要性,这可能会对用户体验产生负面影响。另一方面,基于生成的CRS通过利用Seq2Seq架构(Vaswani等,2017a)来解决这一问题,将对话和推荐任务结合起来,生成流畅且连贯的类人响应。尽管这些方法有效,但由于用户-商品交互数据较为稀疏和有限,它们未能建模用户的多样化偏好。相比之下,我们的工作旨在建模多方面的偏好,以探索用户多样化的复杂关系模式。
2.2 Matthew Effect in Recommendation
马太效应是推荐系统(RSs)中一个众所周知的问题。最近,Liu等人(Liu和Huang,2021)证实了马太效应在YouTube推荐系统中的存在。此外,Wang等人(Wang等,2019)进行了严格的定量分析,为基于协同过滤的推荐系统中马太效应的定量特征提供了宝贵的见解。为了缓解马太效应,一种常见的方法是考虑推荐多样性,这一观点得到了研究者的强烈支持(Anderson等,2020;Hansen等,2021;Liang等,2021;Zheng等,2021a);另一个关键视角是通过消除流行度偏差,这一因素被认为是马太效应放大的催化剂(Zheng等,2021b)。但这些方法主要集中在静态推荐场景中研究马太效应,而未考虑用户-系统反馈循环。相比之下,我们的HyCoRec旨在考虑动态的用户-系统反馈循环来缓解马太效应。
3 HyCoRec
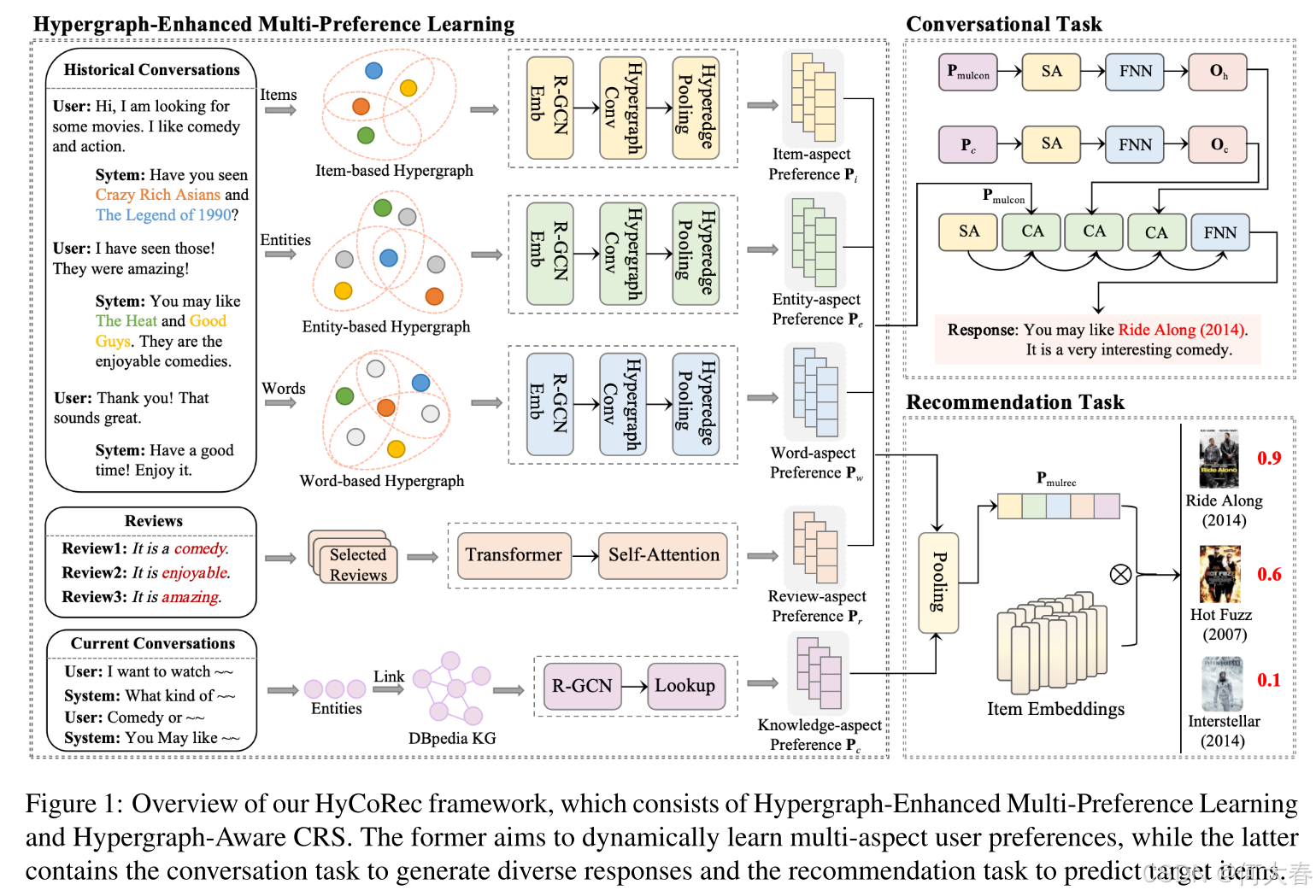
马太效应是对话式推荐系统(CRS)中一个众所周知的问题,并且由于动态用户-系统反馈循环的存在,它不可避免地会随着时间的推移而加剧。为了应对这些挑战,我们提出了一种新范式HyCoRec,它由超图增强的多偏好学习和超图感知的对话式推荐系统组成。图1展示了我们HyCoRec的整体流程。
3.1 Preliminaries
3.1.1 Conversational Recommendation
对话式推荐是一种个性化的方法,系统通过与用户进行持续对话,以更深入地了解他们的偏好并提供定制化的建议。这种交互式方法使系统能够收集更多关于用户偏好、上下文和需求的信息,从而生成更精确且相关的推荐。对话式推荐系统广泛应用于电子商务、音乐流媒体、电影推荐等多个领域,旨在提升用户体验和满意度。
3.1.2 Hypergraph
超图展示了复杂的结构,通过超链接捕捉多个元素之间的复杂关系。在我们的研究中,我们通过构建多粒度超图来描绘用户偏好,包括基于商品的超图 G item ( t ) \mathcal{G}^{(t)}_{\text{item}} Gitem(t)、基于实体的超图 G entity ( t ) \mathcal{G}^{(t)}_{\text{entity}} Gentity(t)和基于词汇的超图 G word ( t ) \mathcal{G}^{(t)}_{\text{word}} Gword(t)。每个超图可以描述为 G item ( t ) = ( I ∗ ( t ) , H ∗ ( t ) , N ∗ ( t ) ) \mathcal{G}^{(t)}_{\text{item}} = (\mathcal{I}^{(t)}_{*}, \mathcal{H}^{(t)}_{*}, \mathbf{N}^{(t)}_{*}) Gitem(t)=(I∗(t),H∗(t),N∗(t)),包括:(1) 节点集合 I ∗ ( t ) \mathcal{I}^{(t)}_{*} I∗(t);(2) 超边集合 H ∗ ( t ) \mathcal{H}^{(t)}_{*} H∗(t);(3) 一个 ∣ I ∗ ( t ) ∣ × ∣ H ∗ ( t ) ∣ |\mathcal{I}^{(t)}_{*}| \times |\mathcal{H}^{(t)}_{*}| ∣I∗(t)∣×∣H∗(t)∣的邻接矩阵 N ∗ ( t ) \mathbf{N}^{(t)}_{*} N∗(t),表示每个节点与超边之间的加权链接。
3.2 Hypergraph-Enhanced Multi-Preference Learning
大多数现有方法(Hussein等,2020;Liu等,2021;Nguyen等,2014)的广泛实验一致表明,偏好受限的用户极易受到马太效应的影响。因此,缓解这种不良效应的关键在于建模多样化的用户偏好。沿着这一思路,我们提出了超图增强的多偏好学习,包括多超图构建和多偏好学习。
3.2.1 Multi-Hypergraph Construction
传统的知识图谱(KGs)专注于通过成对交互进行偏好学习,因为边仅连接两个顶点。然而,用户偏好通常表现出复杂的商品关系模式。为了解决这一问题,我们构建了多个超图(商品层面、实体层面和词汇层面),使得连接超过两个顶点成为可能。
Item-based Hypergraph.
商品直接反映了用户的真实偏好。用户可能偏好相关的商品,例如来自同一品牌或具有相似特征的产品。因此,在相似或功能相似的商品之间建立连接对于探索多样化偏好至关重要。为此,我们首先从会话中提取商品并将其作为顶点,形成一个超边。然后,通过共享商品将用户的所有超边连接起来,构建基于商品的超图 G item ( t ) \mathcal{G}^{(t)}_{\text{item}} Gitem(t),如下所示:
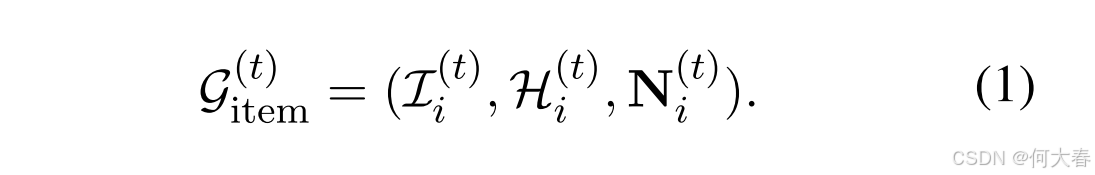
其中,I(t) i 表示从历史对话中提取的商品集合,H(t) i 是超边集合,N(t) i ∈ {0, 1}|I(t) i |×|H(t) i | 是关联矩阵,其定义如下:
其中, I i ( t ) \mathcal{I}_i^{(t)} Ii(t) 表示从历史对话中提取的项集, H i ( t ) \mathcal{H}_i^{(t)} Hi(t) 是超边集, N i ( t ) ∈ { 0 , 1 } ∣ I i ( t ) ∣ × ∣ H i ( t ) ∣ \mathbf{N}_i^{(t)} \in \{0,1\}^{|\mathcal{I}_i^{(t)}| \times |\mathcal{H}_i^{(t)}|} Ni(t)∈{0,1}∣Ii(t)∣×∣Hi(t)∣ 是关联矩阵,其定义如下:
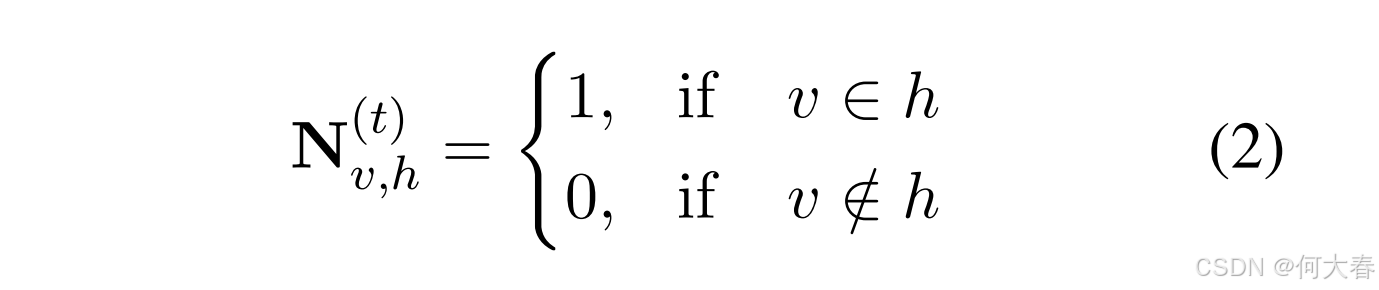
顶点 v ∈ I i ( t ) v \in {\cal I}_i^{(t)} v∈Ii(t) 的度数记为 d ( v ) = ∑ h ∈ H i ( t ) N v , h ( t ) d(v) = \sum_{h \in {\cal H}_i^{(t)}} {\bf N}_{v,h}^{(t)} d(v)=∑h∈Hi(t)Nv,h(t)。类似地,边 h ∈ H i ( t ) h \in {\cal H}_i^{(t)} h∈Hi(t) 的度数记为 δ ( h ) = ∑ v ∈ I i ( t ) N v , h ( t ) \delta(h) = \sum_{v \in {\cal I}_i^{(t)}} {\bf N}_{v,h}^{(t)} δ(h)=∑v∈Ii(t)Nv,h(t)。此外,我们使用 V i ( t ) ∈ N ∣ I i ( t ) ∣ × ∣ I i ( t ) ∣ {\bf V}_i^{(t)} \in \mathbb{N}^{|{\cal I}_i^{(t)}| \times |{\cal I}_i^{(t)}|} Vi(t)∈N∣Ii(t)∣×∣Ii(t)∣ 和 E i ( t ) ∈ N ∣ H i ( t ) ∣ × ∣ H i ( t ) ∣ {\bf E}_i^{(t)} \in \mathbb{N}^{|{\cal H}_i^{(t)}| \times |{\cal H}_i^{(t)}|} Ei(t)∈N∣Hi(t)∣×∣Hi(t)∣ 分别表示顶点度数和边度数的对角矩阵。
Entity-based Hypergraph.
为了解决历史用户-商品交互数据的稀疏性和局限性,我们利用广泛的 DBpedia 知识图谱(Auer 等,2007)构建基于实体的超图。具体来说,我们从对话中提取提到的单个商品作为实体,并将其 k 跳邻居形成每个超边。这种方法使我们能够捕捉扩展邻居之间的共享语义内涵。然后,根据超边共有的实体将它们连接起来。形式上,基于实体的超图 G e n t i t y ( t ) \mathcal{G}^{(t)} _{entity} Gentity(t) 可以表示为:
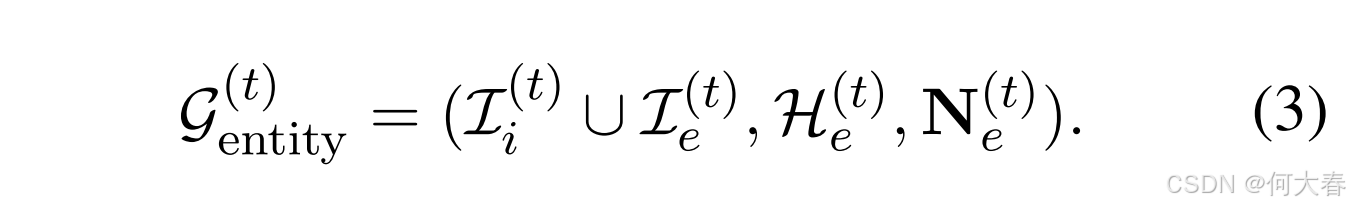
其中,
I
e
(
t
)
\mathcal{I}_e^{(t)}
Ie(t) 表示
k
k
k 跳邻居,
H
e
(
t
)
\mathcal{H}_e^{(t)}
He(t) 是超边集,
N
e
(
t
)
∈
{
0
,
1
}
∣
I
e
(
t
)
∣
×
∣
H
e
(
t
)
∣
\mathbf{N}_e^{(t)}\in\{0,1\}|\mathcal{I}_e^{(t)}|\times|\mathcal{H}_e^{(t)}|
Ne(t)∈{0,1}∣Ie(t)∣×∣He(t)∣ 是关联矩阵,
V
e
(
t
)
∈
N
∣
I
e
(
t
)
∣
×
∣
I
e
(
t
)
∣
\mathbf{V}_e^{(t)}\in\mathbb{N}|\mathcal{I}_e^{(t)}|\times|\mathcal{I}_e^{(t)}|
Ve(t)∈N∣Ie(t)∣×∣Ie(t)∣ 和
E
e
(
t
)
∈
N
∣
H
e
(
t
)
∣
×
∣
H
e
(
t
)
∣
\mathbf{E}_e^{(t)}\in\mathbb{N}|\mathcal{H}_e^{(t)}|\times|\mathcal{H}_e^{(t)}|
Ee(t)∈N∣He(t)∣×∣He(t)∣ 分别表示顶点度数和边度数的对角矩阵。
Word-based Hypergraph.
对话中的关键词对于理解用户需求至关重要。通过分析突出词汇,我们可以识别特定的偏好,这对于建模多样化的用户偏好至关重要。为了实现这一点,我们利用面向词汇的知识图谱 ConceptNet(Speer 等,2017)构建基于词汇的超图,以揭示同义、反义和共现等语义关系。我们将每个历史对话项目表示为一个关键词,并将其扩展到包括 k 跳邻居,形成一个超边。所有超边通过共享词汇连接起来。基于词汇的超图
G
w
o
r
d
(
t
)
\mathcal{G}^{(t)} _{word}
Gword(t)可以定义如下:
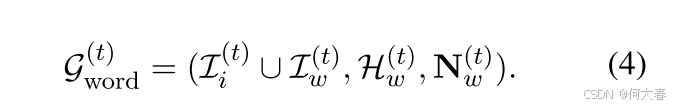
其中, I w ( t ) \mathcal{I}_w^{(t)} Iw(t) 是 k k k 跳邻居, H w ( t ) \mathcal{H}_w^{(t)} Hw(t) 表示超边集, N w ( t ) ∈ { 0 , 1 } ∣ I w ( t ) ∣ × ∣ H w ( t ) ∣ \mathbf{N}_w^{(t)} \in \{0,1\}^{|\mathcal{I}_w^{(t)}| \times |\mathcal{H}_w^{(t)}|} Nw(t)∈{0,1}∣Iw(t)∣×∣Hw(t)∣ 是如公式 (2) 定义的关联矩阵。类似地,令 V w ( t ) ∈ N ∣ I w ( t ) ∣ × ∣ I w ( t ) ∣ \mathbf{V}_w^{(t)} \in \mathbb{N}^{|\mathcal{I}_w^{(t)}| \times |\mathcal{I}_w^{(t)}|} Vw(t)∈N∣Iw(t)∣×∣Iw(t)∣ 和 E w ( t ) ∈ N ∣ H w ( t ) ∣ × ∣ H w ( t ) ∣ \mathbf{E}_w^{(t)} \in \mathbb{N}^{|\mathcal{H}_w^{(t)}| \times |\mathcal{H}_w^{(t)}|} Ew(t)∈N∣Hw(t)∣×∣Hw(t)∣ 分别表示顶点度数和边度数的对角矩阵。
3.2.2 Multi-Preference Learning
在构建了如上所述的多重超图之后,我们将利用这些超图来有效捕捉多样化的用户偏好,从而缓解马太效应。这包括与商品、实体、词汇、评论和知识方面相关的偏好,所有这些都在建模多维度偏好中发挥作用。
Item-aspect Preference.
建模商品层面的偏好对于理解用户在与不同商品互动时的独特品味和偏好具有重要意义。为了实现这一目标,我们利用基于商品的超图推导出商品层面的偏好 P i \mathbf{P}_i Pi。为了有效捕捉高阶关系,受 (Bai 等,2021) 启发,我们将超图卷积函数 HConv(·) 定义如下:
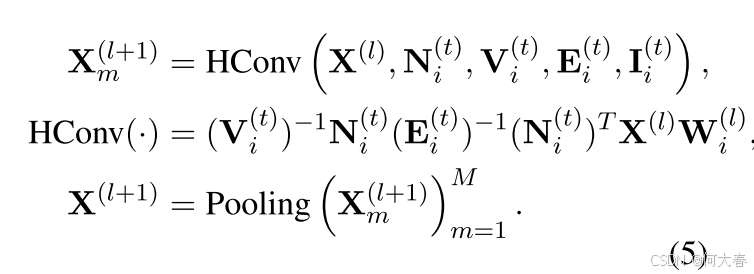
其中, X l \textbf{X}^l Xl 和 X ( l + 1 ) \mathbf{X}^{(l+1)} X(l+1) 分别表示第 l l l 层和第 ( l + 1 ) (l+1) (l+1) 层的输入, W i ( l ) \mathbf{W}_i^{(l)} Wi(l) 表示可训练参数。符号 N i ( t ) \mathbf{N}_i^{(t)} Ni(t)、 V i ( t ) \mathbf{V}_i^{(t)} Vi(t) 和 E i ( t ) \mathbf{E}_i^{(t)} Ei(t) 已在第 3.2.1 节中讨论过。具体来说, I i ( t ) \mathbf{I}_i^{(t)} Ii(t) 表示商品表示(Shang 等,2023)。此外, m m m 表示多头架构中的头数(Vaswani 等,2017b)。最后,我们对从最后一层(即第 ( L + 1 ) (L+1) (L+1) 层)获得的表示 X ( L + 1 ) \mathbf{X}^{(L+1)} X(L+1) 应用平均池化 Pooling(·),以学习商品层面的偏好 P i \mathbf{P}_i Pi:
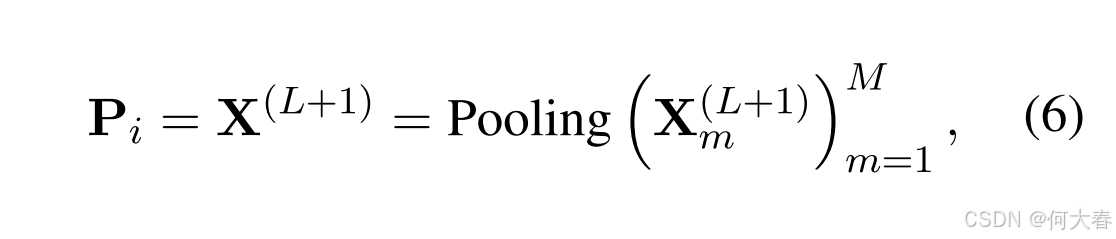
Entity-aspect Preference.
捕捉实体层面的偏好对于揭示用户行为背后的复杂关系模式非常有益。为了实现这一点,我们利用基于实体的超图作为学习实体层面偏好的机制。与商品层面的偏好类似,实体层面的偏好 P e \mathbf{P}_e Pe可以表示为:
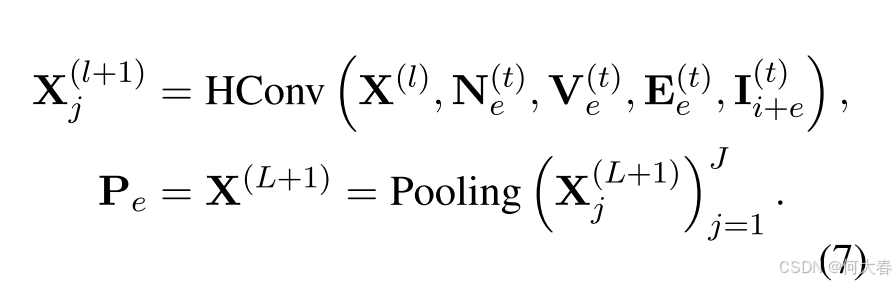
关于 N e ( t ) \mathbf{N}_e^{(t)} Ne(t)、 V e ( t ) \mathbf{V}_e^{(t)} Ve(t) 和 E e ( t ) \mathbf{E}_e^{(t)} Ee(t) 的具体细节可以在第 3.2.1 节中找到。此外, I i + e ( t ) \mathbf{I}_{i+e}^{(t)} Ii+e(t) 是实体集 I i ( t ) ∪ I e ( t ) \mathcal{I}_i^{(t)} \cup \mathcal{I}_e^{(t)} Ii(t)∪Ie(t) 的实体表示。同时, j j j 表示多头架构中的头数, W e ( l ) \mathbf{W}_e^{(l)} We(l) 是可训练的参数。
Word-aspect Preference.
对话中出现的关键词直接反映了用户的特定或潜在偏好。基于词级超图(word-based hypergraph)推导出的词层面偏好(word-aspect preference) P w \mathbf{P}_w Pw 可以表示为:
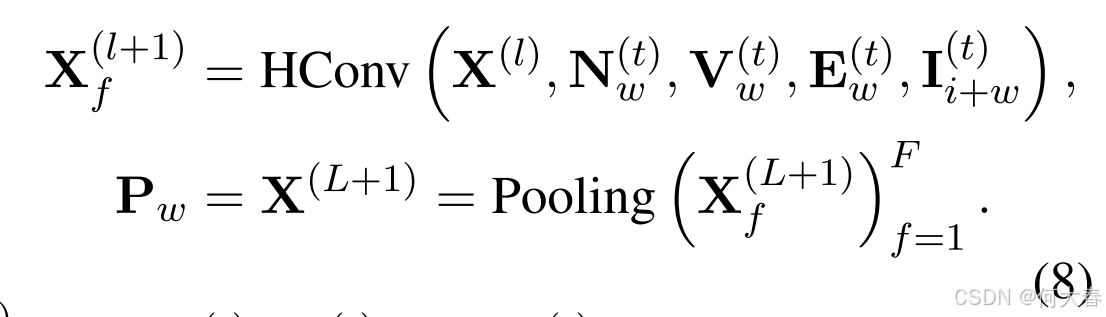
其中,N w ( t ) \textbf{其中,N}_w^{(t)} 其中,Nw(t)、 V w ( t ) \textbf{V}_w^{(t)} Vw(t) 和 E w ( t ) \textbf{E}_w^{(t)} Ew(t) 在第 3.2.1 节中有更详细的解释。此外, I i + w ( t ) \textbf{I}_{i+w}^{(t)} Ii+w(t) 表示从编码的实体嵌入中获得的词表示。变量 f f f 表示多头架构中的头数, W f ( l ) \textbf{W}_f^{(l)} Wf(l) 表示可训练的参数。
Review-aspect Preference.
物品评论为用户的使用体验和反馈提供了宝贵的洞察。分析这些评论有助于识别模式、情感趋势以及用户态度,从而更好地理解用户偏好。受 Transformer 模型优点的启发,我们利用 Transformer 框架对获取的评论进行编码(Lu 等,2021)。具体来说,给定一条评论 R R R,前一 Transformer 层的输出嵌入表示为 T l ( R ) \mathcal{T}^l(R) Tl(R),通过多头注意力函数 MHA(·) 定义下一层 T l + 1 ( R ) \mathcal{T}^{l+1}(R) Tl+1(R),公式如下:
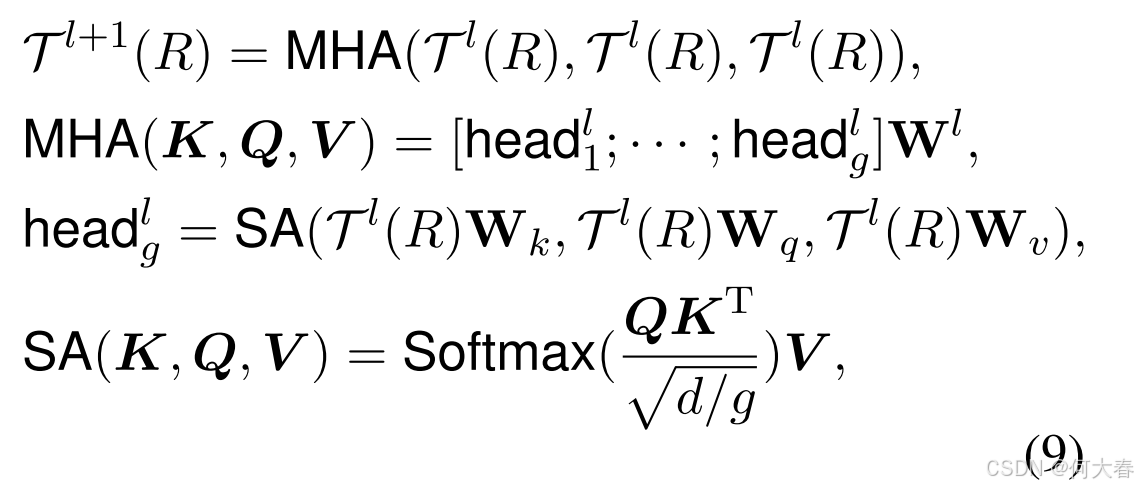
其中, g g g 表示头数, W l \mathbf{W}^l Wl 表示可训练的参数,每个头 head g l \text{head}_g^l headgl 通过缩放点积注意力机制(Scaled Dot-Product Attention)(Vaswani 等,2017c) SA ( ⋅ ) \text{SA}(\cdot) SA(⋅) 计算得到。 K \boldsymbol{K} K、 Q \boldsymbol{Q} Q 和 V \boldsymbol{V} V 分别表示键矩阵、查询矩阵和值矩阵, W k \mathbf{W}_k Wk、 W q \mathbf{W}_q Wq 和 W v \mathbf{W}_v Wv 是可学习的参数。为方便起见,我们将最后一层 Transformer 的输出嵌入视为评论层面偏好 P r \mathbf{P}_r Pr:
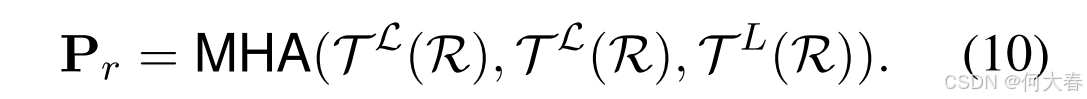
其中,
L
\mathcal{L}
L 表示 Transformer 的层数。
Knowledge-aspect Preference.
当前对话中传递的信息反映了用户的动态偏好,为理解他们当前的兴趣提供了宝贵的洞察。因此,我们的重点在于通过对当前对话中提到的实体进行编码,来建模知识层面的偏好。给定当前对话上下文 C \mathcal{C} C,我们利用 DBpedia 和 CN-DBpedia 沿路径提取实体 E k = { e 1 , e 2 , ⋯ , e k } \mathcal{E}_k=\{e_1,e_2,\cdots,e_k\} Ek={e1,e2,⋯,ek}。为了捕捉高阶实体表示,我们使用 RGCN 通过对比预训练(Shang 等,2023)显式地捕捉关系语义。实体 e e e 在第 ( l + 1 ) (l+1) (l+1) 层的表示可以计算如下:
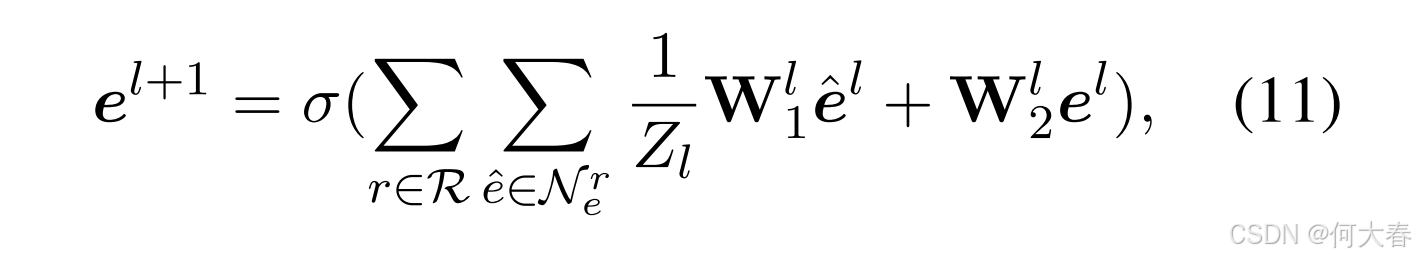
其中, e l \boldsymbol{e}^l el 是实体 e e e 在第 l l l 层的表示, σ \sigma σ 表示 sigmoid 函数, e ^ \hat{e} e^ 指的是关系 r r r 下一跳邻居集 N e r \mathcal{N}_e^r Ner 中的实体, Z l Z_l Zl 是超参数。 W 1 l \textbf{W}_1^l W1l 和 W 2 l \mathbf{W}_2^l W2l 是可训练的参数。我们使用最后一层的表示 e L e^L eL 作为知识层面偏好 P c \mathbf{P}_{c} Pc:
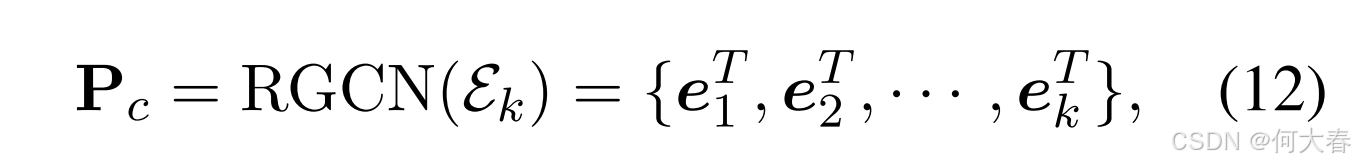
其中, e i T \boldsymbol{e}_i^T eiT 是通过 RGCN 得到的实体 e i e_i ei 的嵌入表示。
3.3 Hypergraph-Aware CRS
为了应对对话推荐系统(CRS)中的马太效应,我们采用多层面偏好,即 P i P_i Pi、 P e P_e Pe、 P w P_w Pw、 P r P_r Pr 和 P c P_c Pc,以在推荐任务中准确预测物品,并在对话任务中有效生成响应。
3.3.1 Recommendation Task
推荐任务的目标是通过动态用户-系统交互中的自然对话,为用户准确预测物品。为了解决马太效应,我们首先整合多层面偏好,在推荐任务中推导出融合偏好 P m u l r e c \mathbf{P}_{\mathrm{mulrec}} Pmulrec,其公式如下:
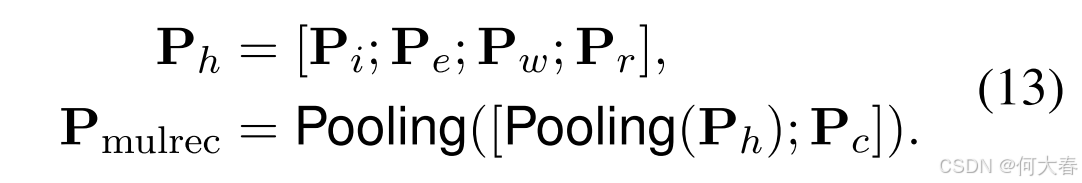
其中,
;
;
; 表示拼接操作。接下来,向量
P
mulrec
\mathbf{P}_{\text{mulrec}}
Pmulrec 用于从物品集
I
I
I 的所有候选集中选择合适的物品,推荐预测的计算公式如下:
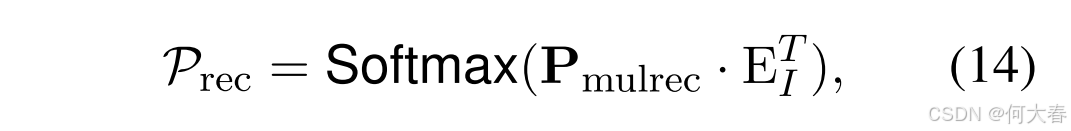
其中, E I {E}_I EI 是物品集 I \mathcal{I} I 中所有候选物品的嵌入表示。我们使用交叉熵损失(Shang 等,2023)来学习推荐任务:
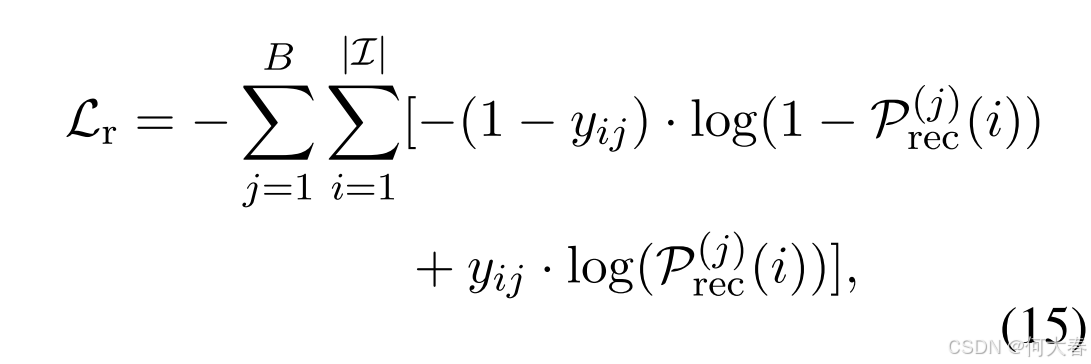
其中,符号 B B B 表示小批量的大小, y i j ∈ { 0 , 1 } y_{ij} \in \{0,1\} yij∈{0,1} 表示目标标签。
3.3.2 Conversational Task
对话任务的重点是生成合适的对话语句以回应用户输入。为了生成多样化的响应,我们整合多层面偏好向量,在对话任务中推导出融合偏好 P mulcon \mathbf{P}_{\text{mulcon}} Pmulcon,其公式如下:
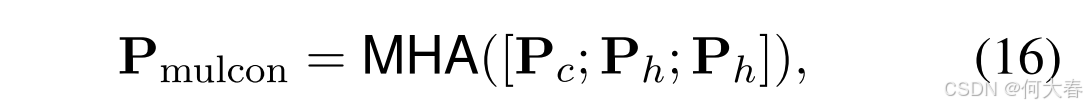
其中,
P
h
\texttt{P}_h
Ph 的定义如公式 (13) 所示。然后,该融合偏好
P
mulcon
\mathbf{P}_{\text{mulcon}}
Pmulcon 被输入到基于 Transformer 的编码器-解码器框架中,以生成多样化的响应。设
Y
n
−
1
\mathbf{Y}^{n-1}
Yn−1 为上一时间单元的输出,则当前时间单元的输出
Y
n
\mathbf{Y}^n
Yn 为:
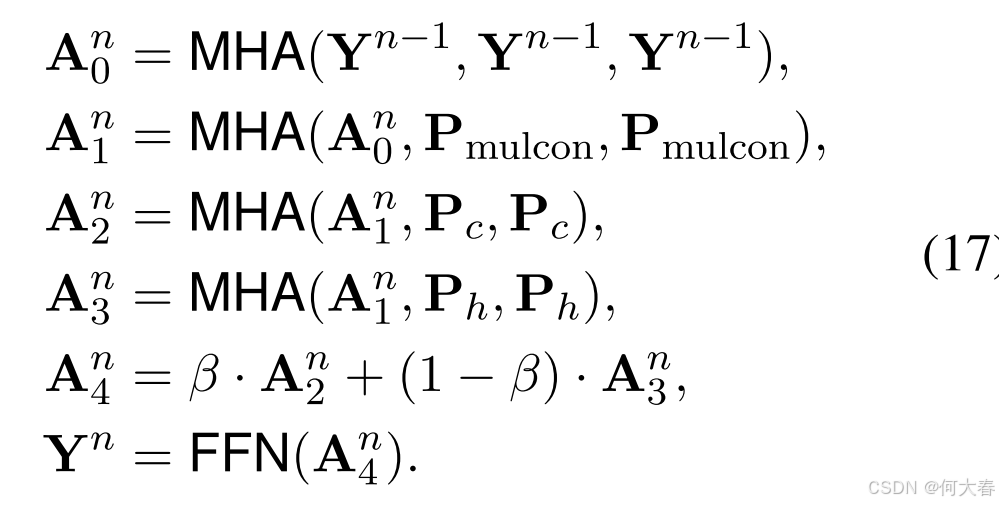
其中,FFN(·) 是全连接前馈网络, β \beta β 是用于平衡两个信号的超参数。为了增强响应的多样性,我们采用(Shang 等,2023)中的偏好感知偏置和物品相关偏置。给定预测序列 { s t − 1 } \{s_{t-1}\} {st−1},下一个词元的概率计算公式如下:
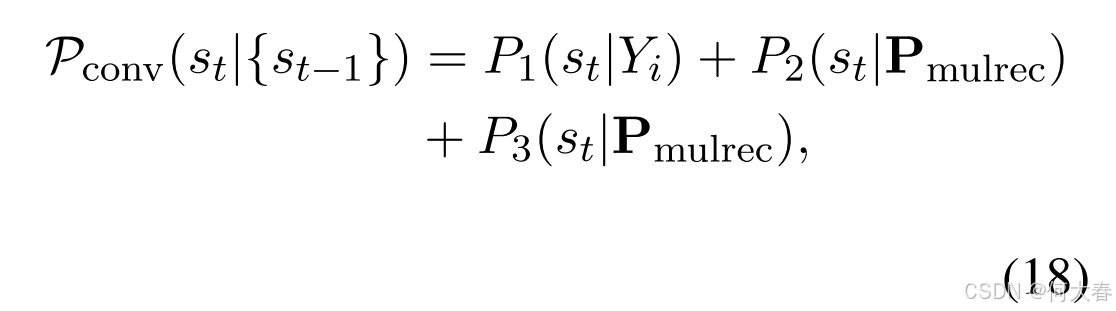
其中, s t s_t st 是第 t t t 个语句,且 { s t − 1 } = s 1 , s 2 , ⋯ , s t − 1 \{s_{t-1}\} = s_1, s_2, \cdots, s_{t-1} {st−1}=s1,s2,⋯,st−1。受(Shang 等,2023)启发, P 1 ( ⋅ ) P_1(\cdot) P1(⋅)、 P 2 ( ⋅ ) P_2(\cdot) P2(⋅) 和 P 3 ( ⋅ ) P_3(\cdot) P3(⋅) 分别是词汇概率、词汇偏置和复制概率。接下来,我们使用交叉熵损失:
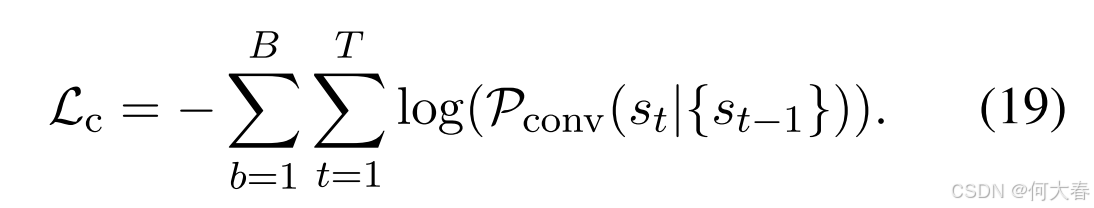
其中, T T T 表示语句的截断长度。
4 Experiments and Analyses
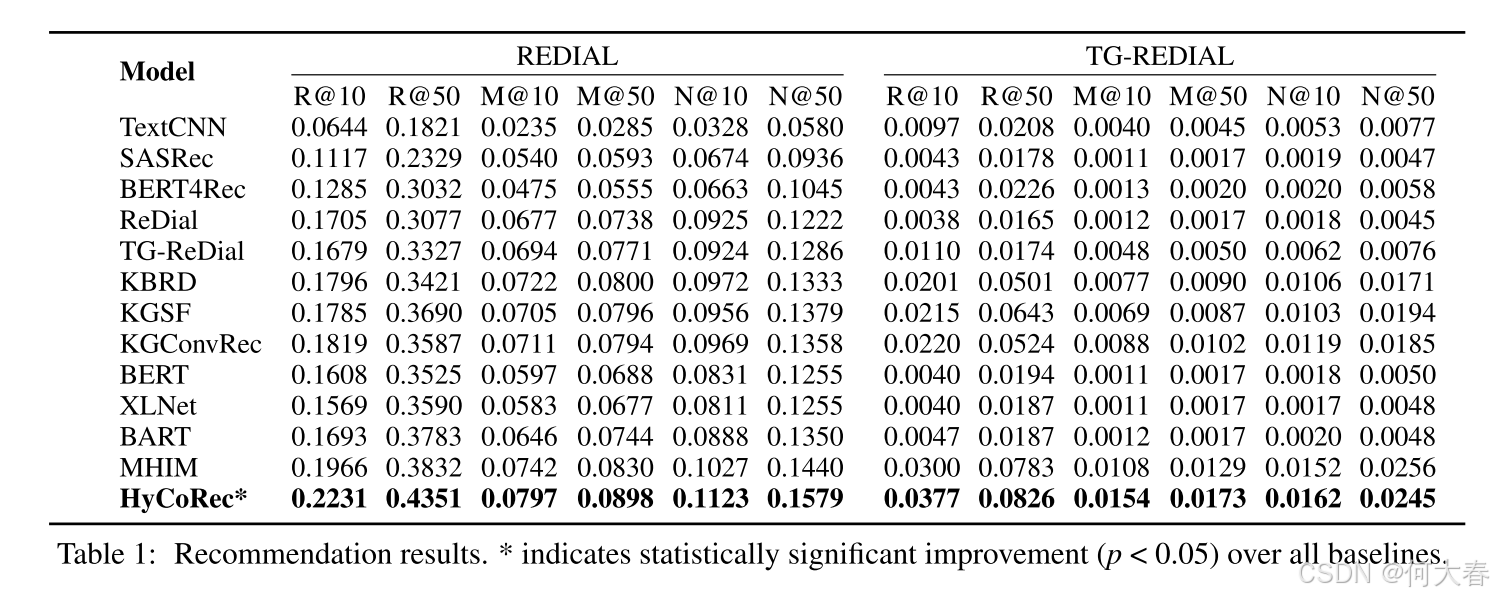
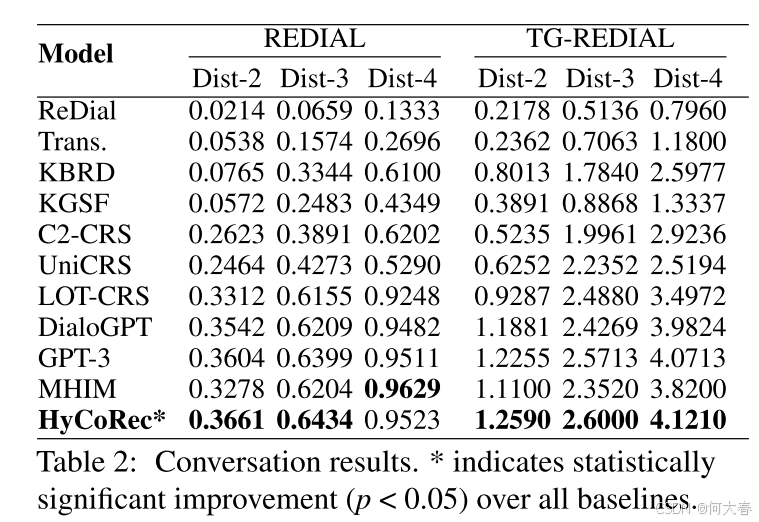
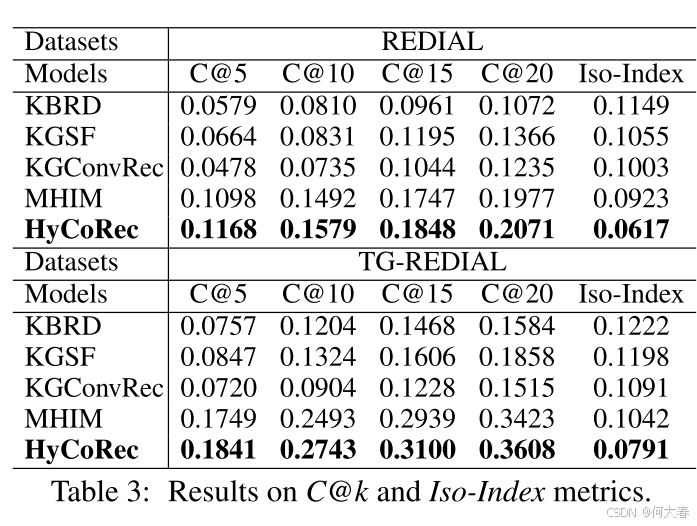
5 Conclusion
马太效应是对话推荐系统(CRS)中一个众所周知的问题,并且由于动态的用户-系统反馈循环,这一问题会不断加剧。为了解决这些问题,我们提出了一种新范式 HyCoRec,旨在通过学习多层面的用户偏好(即物品层面、实体层面、词层面、评论层面和知识层面的偏好),在对话任务中有效生成多样化的响应,并在推荐任务中准确预测物品,从而缓解马太效应。大量实验验证了我们的 HyCoRec 在所有对比基线中的优越性,并证明了其在缓解 CRS 中马太效应方面的显著效果。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









