







文章信息:

Towards Unified Conversational Recommender Systems via Knowledge-Enhanced Prompt Learning 论文阅读
发表于:KDD 2022
原文链接:https://arxiv.org/abs/2206.09363
源码:https://github.com/RUCAIBox/UniCRS
ABSTRACT
对话式推荐系统(CRS)旨在通过自然语言对话主动获取用户偏好并推荐高质量的项目。通常,CRS由一个推荐模块(为用户预测偏好项目)和一个对话模块(生成适当的回应)组成。为了开发一个有效的CRS,无缝集成这两个模块至关重要。现有的工作要么设计语义对齐策略,要么在两个模块之间共享知识资源和表示。然而,这些方法仍然依赖于不同的架构或技术来开发这两个模块,使得有效的模块集成变得困难。
为了解决这个问题,我们提出了一种基于知识增强提示学习的统一CRS模型,名为UniCRS。我们的方法将推荐和对话子任务统一到提示学习范式中,并利用基于固定预训练语言模型(PLM)的知识增强提示以统一的方式完成这两个子任务。在提示设计中,我们包括融合的知识表示、任务特定的软标记和对话上下文,这些可以提供足够的上下文信息来适应CRS任务的PLM。此外,对于推荐子任务,我们还将生成的响应模板作为提示的重要部分,以增强两个子任务之间的信息交互。
在两个公共CRS数据集上的广泛实验已经证明了我们方法的有效性。我们的代码可在以下链接公开获取:https://github.com/RUCAIBox/UniCRS
1 INTRODUCTION
随着智能助手的普及,对话式推荐系统(CRS)已成为一个新兴的研究课题,通过自然语言对话为用户提供推荐服务[5, 15]。从功能角度来看,CRS应能完成两个主要的子任务:一个是从候选集中预测项目给用户的推荐子任务,另一个是生成适当问题或回应的对话子任务。
为了完成这两个子任务,现有的方法[4, 16, 35]通常为每个子任务分别建立两个独立的模块,即推荐模块和对话模块。由于这两个子任务高度耦合,人们普遍认识到,一个强大的CRS应该能够无缝集成这两个模块[4, 16, 30, 35],以便在它们之间共享有用的特征或知识。一类工作结合共享的知识资源(例如,知识图谱[4]和评论[22])及其表示来增强语义交互。另一类工作设计特殊的表示对齐策略,如预训练任务和正则化项(例如,互信息最大化[35]和对比学习[38]),以保证两个模块的语义一致性。
尽管现有的对话式推荐系统(CRS)方法取得了进展,但推荐模块和对话模块之间的语义不一致这一根本问题尚未得到很好的解决。图1展示了一个代表性的CRS模型KGSF [35]的预测不一致案例,该模型利用互信息最大化来对齐语义表示。尽管推荐模块预测了电影《冰雪奇缘2(2019)》,但对话模块似乎没有意识到这一推荐结果,生成了一个包含另一部电影《漂亮女人(1990)》的不匹配回应。即使我们可以利用启发式约束来强制生成推荐的电影,这也无法从根本上解决两个模块之间的语义不一致问题。本质上,这个问题是由现有方法中的两个主要问题引起的。首先,这些方法中的大多数使用不同的架构或技术开发这两个模块。即使有一些共享的知识或组件,仍然很难有效地无缝关联这两个模块。其次,一个模块的结果无法被另一个模块感知和利用。例如,在KGSF [35]中,没有办法在预测推荐结果时利用生成的回应。总之,语义不一致的根源在于两个模块的不同架构设计和工作机制。
为了解决上述问题,我们旨在开发一种更有效的CRS,以统一的方式实现推荐和对话模块。我们的方法受到预训练语言模型(PLMs)[2, 8, 12]巨大成功的启发,这些模型已被证明即使在非常不同的设置中也能作为解决各种任务的有效通用解决方案。特别是,最近提出的提示学习范式[2, 8, 29]以一种简单而灵活的方式进一步统一了在不同任务上使用PLMs的方法。一般来说,提示学习通过在原始输入前添加显式或隐式的标记来增强或扩展PLMs的输入,这些标记可能包含示例、指令或可学习的嵌入。这种范式在很大程度上可以将不同的任务格式或数据形式统一起来。对于CRS来说,由于两个子任务都旨在基于相同的对话语义实现特定目标,因此基于提示学习开发一种统一的CRS方法是可行的。
为此,在本文中,我们提出了一种基于知识增强提示学习的新型统一对话推荐系统(CRS)模型,名为UniCRS。对于基础预训练语言模型(PLM),我们选用DialoGPT [33],因为它是在大规模对话语料库上预训练的。在我们的方法中,基础PLM在解决两个子任务时保持固定,不进行微调或持续预训练。
为了更好地将任务知识注入基础PLM,我们首先设计了一个语义融合模块,该模块能够捕捉对话文本中词汇与知识图谱(KGs)中实体之间的语义关联。我们方法的主要技术贡献在于我们将两个子任务以提示学习的形式进行构建,并为每个子任务设计了特定的提示。在我们的提示设计中,我们包含了对话上下文(特定标记)、任务特定的软标记(潜在向量)和融合的知识表示(潜在向量),这些可以提供关于对话上下文、任务指令和背景知识的充分语义信息。此外,对于推荐任务,我们将对话模块生成的响应模板纳入提示中,这可以进一步增强两个子任务之间的信息交互。
为了验证我们方法的有效性,我们在两个公共CRS数据集上进行了实验。实验结果表明,我们的UniCRS在推荐和对话子任务上均优于几种有竞争力的方法,尤其是在训练数据有限的情况下。我们的主要贡献总结如下:
- 据我们所知,这是首次以通用提示学习的方式开发统一的CRS。
- 我们的方法将CRS的子任务构建为统一的提示学习形式,并设计了具有相应优化方法的任务特定提示。
- 在两个公共CRS数据集上的广泛实验证明了我们的方法在推荐和对话任务中的有效性。
2 RELATEDWORK
我们的工作与以下两个研究方向相关,即对话式推荐和提示学习。
2.1 Conversational Recommendation
随着对话系统的快速发展[3, 33],对话式推荐系统(CRS)已成为一个研究课题,旨在通过与用户的对话交互提供准确的推荐[5, 7, 28]。CRS研究的一个主要类别依赖于预定义的动作(例如,意图槽或项目属性)与用户互动[5, 28, 36]。它们专注于在尽可能少的轮次内完成推荐任务。它们采用多臂老虎机模型[5, 31]或强化学习[28]来找到最优的交互策略。然而,属于这一类别的方法大多依赖于预定义的动作和模板来生成响应,这在很大程度上限制了它们在各种场景中的应用。另一类CRS研究旨在生成既准确的推荐又具有人类般自然的响应[10, 15, 37]。为了实现这一目标,这些工作通常设计一个推荐模块和一个对话模块分别实现这两个功能。然而,这样的设计引发了语义不一致的问题,因此将两个模块无缝集成到一个系统中至关重要。现有的工作大多要么共享知识资源及其表示[4, 22],要么设计语义对齐预训练任务[35]和正则化项[38]。然而,由于它们的架构或技术不同,仍然很难有效地集成这两个模块。例如,已经指出,从对话模块生成的响应并不总是与推荐模块预测的项目匹配[18]。我们的工作遵循后一类,并采用基于预训练语言模型(PLM)的提示学习来统一推荐和对话子任务。通过这种方式,可以通过精心设计的提示以统一的方式构建这两个子任务。
2.2 Prompt Learning
近年来,预训练语言模型(PLMs)在各种任务上展现出了卓越的性能[6, 14]。大多数PLMs都是以语言建模为目标进行预训练的,但在具有相当不同目标的下游任务上进行微调。为了克服预训练和微调之间的差距,提示学习(又称为提示调整)已被提出[9, 19],它依赖于精心设计的提示将下游任务重新构建为预训练任务。早期的工作大多采用手工制作的离散提示来指导PLM[2, 24]。最近,大量工作集中在自动优化特定任务的离散提示上[8, 12],并实现了与手工提示相当的性能。然而,这些方法仍然依赖于生成模型或复杂的规则来控制提示的质量。相比之下,一些工作提出使用可直接优化的可学习连续提示[13, 17]。在此基础上,一些工作设计了提示预训练任务[9]或有知识的提示[11]以提高连续提示的质量。在这项工作中,我们通过提示学习将推荐和对话子任务重新构建为PLM的预训练任务。此外,为了向PLM提供与CRS相关的任务知识,我们通过来自外部知识图谱(KG)的信息增强提示,并进行语义融合以实现提示学习。
3 PROBLEM STATEMENT
正式地,设 u u u 表示一个用户, i i i 表示来自项目集 I \mathcal{I} I 的一个项目, w w w 表示来自词汇表 V \mathcal{V} V 的一个词。一次对话表示为 C = { s t } t = 1 n C = \{s_t\}_{t=1}^n C={st}t=1n,其中 s t s_t st 表示第 t t t 轮的发言,每个发言 s t = { w j } j = 1 m s_t = \{w_j\}_{j=1}^m st={wj}j=1m 由词汇表 V \mathcal{V} V 中的一系列词组成。
根据上述定义,对话式推荐的任务定义如下。在第 t t t 轮,给定对话历史 C = { s j } j = 1 t − 1 C = \{s_j\}_{j=1}^{t-1} C={sj}j=1t−1 和项目集 I \mathcal{I} I,系统应
(1)从整个项目集 I I I 中选择一组候选项目 I t I_t It 进行推荐,并
(2)生成包含 I t I_t It 中项目的回应 R = s t R = s_t R=st。注意,当不需要推荐时, I t I_t It 可能为空。
4 APPROACH
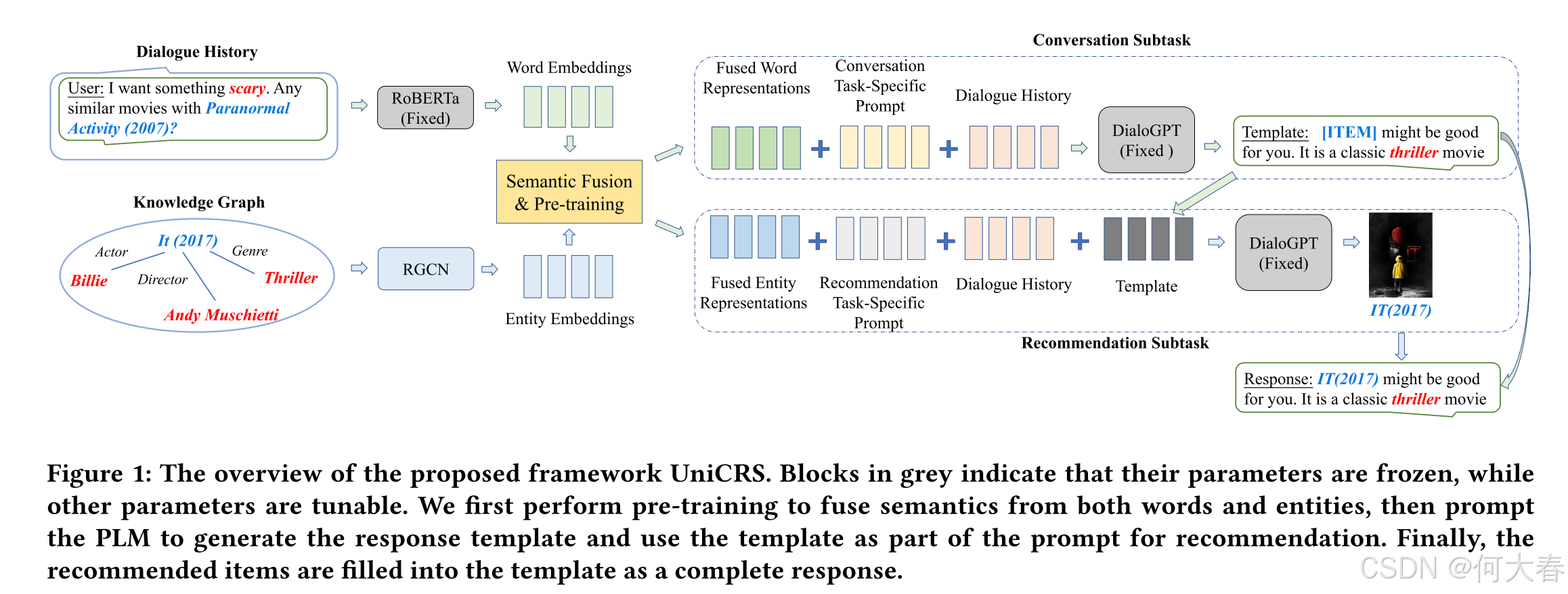
在本节中,我们介绍了一种基于预训练语言模型(PLM)并通过知识增强提示学习实现的统一对话推荐系统(CRS)方法,即UniCRS。我们首先概述我们的方法,然后讨论如何将来自词汇和实体的语义融合到提示中,最后介绍针对CRS任务的知识增强提示方法。我们提出的模型的整体架构如图1所示。
4.1 Overview of the Approach
以往关于对话式推荐系统(CRS)的研究[4, 15, 35]通常分别为推荐和对话子任务开发特定的模块,并且需要将这两个模块连接起来以实现CRS的任务目标。与现有的CRS方法不同,我们旨在基于预训练语言模型(PLM)开发一种基于提示学习的统一方法。
Base PLM
在我们的方法中,我们选用DialoGPT [33] 作为基础预训练语言模型(Base PLM)。DialoGPT采用基于Transformer的自回归架构,并在从Reddit提取的大规模对话语料库上进行了预训练。研究表明,DialoGPT能够生成连贯且富有信息量的回应,使其成为CRS任务的合适基础模型[18,29]。设
f
(
⋅
∣
Θ
p
l
m
)
f(\cdot\mid\Theta_{plm})
f(⋅∣Θplm)表示由参数
Θ
p
l
m
\Theta_{plm}
Θplm参数化的基础PLM,该模型接收一个标记序列作为输入,并为每个标记生成上下文化的表示。除非另有说明,我们将使用DialoGPT最后一个标记的表示来进行后续的预测或生成任务。
A Unified Prompt-Based Approach to CRS.
在第 t t t轮,给定对话历史 { s j } j = 1 t − 1 \{s_j\}_{j=1}^{t-1} {sj}j=1t−1,我们将每个发言连接成一个文本序列 C = { w k } k = 1 n W C=\left\{w_k\right\}_{k=1}^{n_W} C={wk}k=1nW。基本思想是编码对话历史 C C C,获取其上下文化的表示,并通过生成(即生成推荐项目或回应发言)利用基础预训练语言模型(PLM)来解决推荐和对话两个子任务。通过这种方式,这两个子任务可以通过统一的方法来完成。然而,由于基础PLM是固定的,与微调相比,由于缺乏任务适应性,难以达到令人满意的性能。因此,我们采用提示方法[8,9],在原始对话历史前添加精心设计或学习到的提示标记,记为 { p k } k = 1 n P \{p_k\}_{k=1}^{n_P} {pk}k=1nP( n P n_P nP是提示标记的数量)。在实践中,提示标记可以是显式的标记或潜在向量。研究表明,提示是一种有效的范式,可以在不进行微调的情况下利用PLM的知识解决各种任务[2,8]。
Prompt-augmented Dialogue Context.
通过加入提示,原始的对话历史
C
C
C可以被扩展为一个更长的序列(称为上下文序列),记为
C
~
\widetilde{C}
C
。
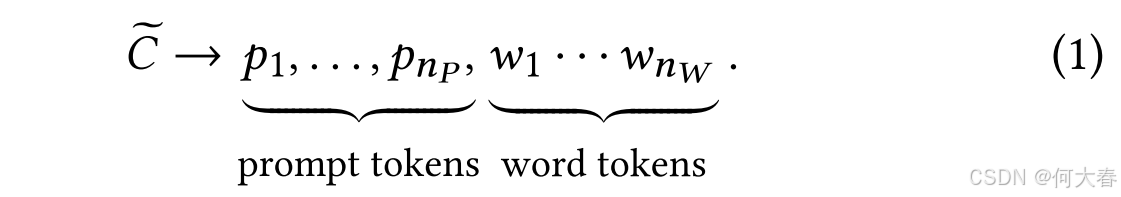
如前所述,我们利用基础预训练语言模型(PLM)来获取上下文序列的上下文化表示,以解决推荐和对话子任务。为了更好地适应任务特性,我们可以构建并学习不同的提示,并获得相应的上下文序列,分别记为用于推荐的 C ~ r e c \widetilde{C}_{rec} C rec和用于对话的 C ~ c o n \widetilde{C}_{con} C con。
为了实现这种统一的方法,我们确定了两个主要问题需要解决:(1)如何融合对话语义和相关知识语义,以便将基础PLM适配于CRS(第4.2节),以及(2)如何为推荐和对话子任务设计和学习合适的提示(第4.3节)。接下来,我们将详细介绍这两个部分。
4.2 Semantic Fusion for Prompt Learning
由于DialoGPT是在一般对话语料库上预训练的,它缺乏针对CRS任务的特定能力,因此不能直接使用。遵循以往的研究[4, 35],我们将知识图谱(KGs)作为特定于任务的知识资源纳入其中,因为它涉及有关对话中提到的实体和项目的有用知识。然而,研究发现对话和KGs的语义空间之间存在较大的语义鸿沟[35, 38]。我们需要首先融合这两个语义空间,以实现有效的知识对齐和丰富。特别地,这一步的目的是融合来自不同编码器的标记和实体嵌入。
Encoding Word Tokens and KG Entities.
给定一个对话历史 C C C,我们首先将出现在 C C C 中的对话词和知识图谱(KG)实体分别编码为词嵌入和实体嵌入。为了补充我们的基础预训练语言模型(PLM)DialoGPT(一个单向解码器),我们采用另一个固定的PLM RoBERTa [20](一个双向编码器)来生成词嵌入。从固定编码器RoBERTa得到的上下文化标记表示被连接成一个词嵌入矩阵,即 T = [ h 1 T ; … ; h n W T ] \mathcal{T} = [\boldsymbol{h}_1^T; \ldots ; \boldsymbol{h}_{n_W}^T] T=[h1T;…;hnWT]。对于实体嵌入,遵循以往的工作[4,35],我们首先基于外部KG DBpedia [1]进行实体链接,然后通过关系图神经网络(RGCN)[25]获得相应的实体嵌入,该网络可以通过在KG上的信息传播和聚合来建模关系语义。同样,得到的实体嵌入矩阵在对话历史中表示。
Word-Entity Semantic Fusion.
为了弥合词与实体之间的语义鸿沟,我们采用一种交叉交互机制,通过双线性变换将这两种语义表示关联起来。
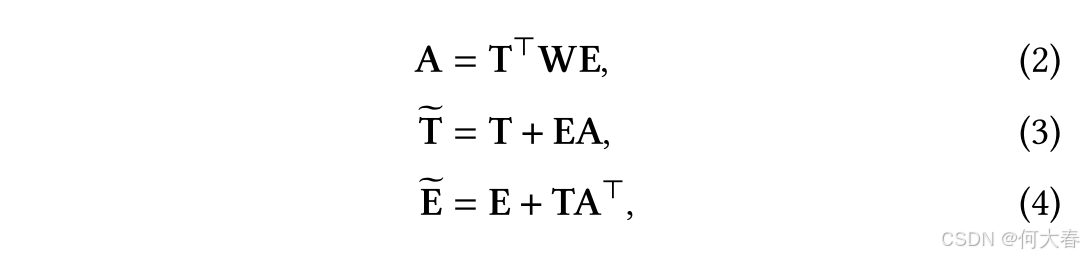
其中, A A A 是两种表示之间的亲和矩阵, W W W 是变换矩阵, T ~ \widetilde{T} T 是融合后的词表示, E ~ \widetilde{\mathbf{E}} E 是融合后的实体表示。这里我们为了简化起见,使用了 T T T 和 E \mathbf{E} E 之间的双线性变换,并将复杂交互机制的进一步探索留待未来的工作。
Pre-training the Fusion Module.
在语义融合之后,我们可以在词和实体之间建立语义关联。然而,这样的模块涉及额外的可学习参数,记为 Θ f u s e \Theta_{fuse} Θfuse。为了更好地优化融合模块的参数,我们提出了一种基于提示的预训练方法,该方法利用来自对话的自监督信号。具体来说,我们将融合后的实体表示 E ~ \widetilde{\mathbf{E}} E (公式 4)前置,并将回应附加到对话上下文中,即 C ~ p r e = [ E ~ ; C ; R ] \widetilde{C}_{pre}=[\widetilde{\mathbf{E}};C;R] C pre=[E ;C;R],其中我们使用粗体字表示潜在向量( E ~ \widetilde{\mathbf{E}} E ),用普通字体表示显式标记 ( C , R ) (C,R) (C,R)。对于这个预训练任务,我们简单地利用增强提示的上下文序列 C ~ p r e \widetilde{C}_{pre} C pre 来预测回应中出现的实体。实体 e e e 的预测概率公式化为:
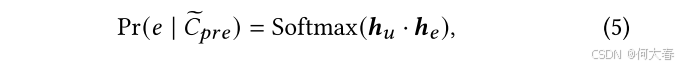
其中, h u = P o o l i n g [ f ( C ~ p r e ∣ Θ p l m ; Θ f u s e ) ] \boldsymbol{h}_u = \mathrm{Pooling}[f(\widetilde{C}_{pre} \mid \Theta_{plm}; \Theta_{fuse})] hu=Pooling[f(C pre∣Θplm;Θfuse)] 是通过对 C ~ p r e \widetilde{C}_{pre} C pre 中所有标记的上下文化表示进行池化得到的上下文的已学习表示, h e \boldsymbol{h}_e he 是实体 e e e 的融合实体表示。请注意,只有融合模块的参数 Θ f u s e \Theta_{fuse} Θfuse 需要优化,而基础预训练语言模型(PLM)的参数 Θ p l m \Theta_{plm} Θplm 保持固定。我们采用交叉熵损失用于预训练任务。
在语义融合之后,我们从对话历史中获得了词和实体的融合知识表示,分别记为 T ~ \widetilde{T} T (公式 3)和 E ~ \widetilde{\mathbf{E}} E (公式 4)。这些表示随后被用作提示的一部分,如第4.3节所示。
4.3 Subtask-specific Prompt Design
尽管基础预训练语言模型(PLM)是固定的且不进行微调,但我们可以设计特定的提示来使其适应对话推荐系统(CRS)的不同子任务。对于每个子任务(无论是推荐还是对话),提示设计主要包括三个部分,即对话历史、特定于子任务的软标记以及融合的知识表示。对于推荐任务,我们进一步将生成的响应模板作为额外的提示标记纳入其中。接下来,我们将详细描述这两个子任务的具体提示设计。
4.3.1 Prompt for Response Generation.
响应生成子任务旨在生成有信息量的话语,以澄清用户偏好或回应用户的发言。提示设计主要通过增强文本语义来更好地理解对话和生成响应。
The Prompt Design.
响应生成的提示由原始对话历史(以词标记
C
C
C 的形式)、生成特定的软标记(以潜在向量
P
g
e
n
\mathbf{P_{gen}}
Pgen 的形式)以及融合的文本上下文(以潜在向量
e
T
e_T
eT 的形式)组成,正式表示为:
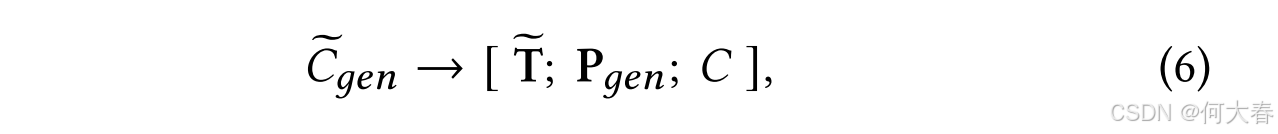
在这里,我们使用粗体和普通字体分别表示软标记序列和硬标记序列。在这种设计中,特定于子任务的提示 P g e n \mathbf{P}_{gen} Pgen 通过来自生成任务的信号、知识图谱增强的文本表示 T ~ \mathbf{\widetilde{T}} T (公式 3)以及原始对话历史 C C C 来指导预训练语言模型(PLM)。
Prompt Learning.
在上述提示设计中,唯一可调的参数是经过预训练的融合文本表示 T ~ \mathbf{\widetilde{T}} T 和生成任务特定的软标记 P g e n \mathbf{P}_{gen} Pgen。它们被表示为 Θ gen \Theta_{\text{gen}} Θgen。我们使用增强提示的上下文 C ~ gen \widetilde{C}_{\text{gen}} C gen 来推导学习 Θ gen \Theta_{\text{gen}} Θgen 的预测损失,其正式表示为:
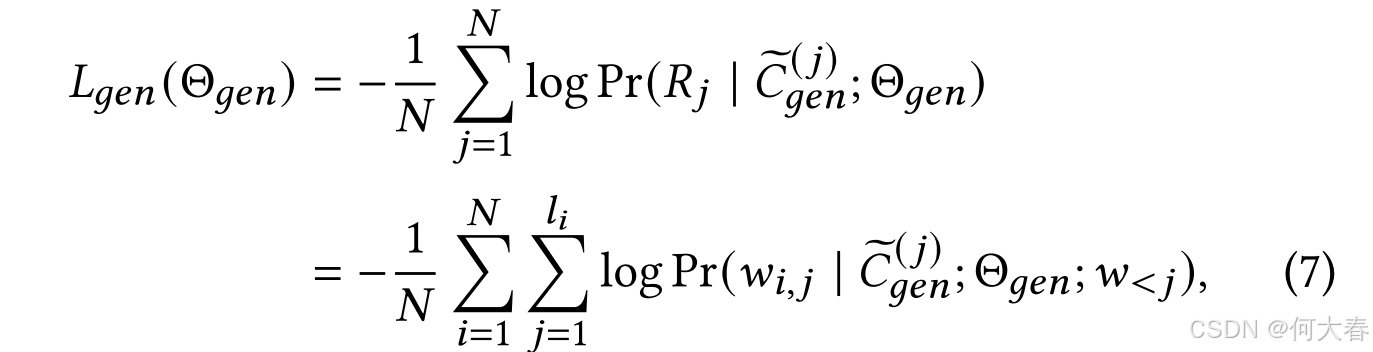
其中, N N N 是训练实例的数量(上下文和目标话语的对数), l i l_i li 是第 i i i 个目标话语的长度, w j w_j wj 表示位于第 j j j 个位置的单词。
Response Template Generation.
我们发现,共享不同子任务的中间结果以实现更一致的最终结果也很重要。例如,根据对话任务生成的回应,预训练语言模型(PLM)可能能够根据这些额外的上下文信息预测更相关的推荐。基于这种直觉,我们建议将回应模板作为推荐子任务提示的一部分。具体来说,我们在基础 PLM 的词汇表 V \mathcal{V} V 中添加一个特殊标记 [ITEM],并用 [ITEM] 标记替换回应中出现的所有项目。在每个时间步,PLM 会生成特殊标记 [ITEM] 或来自原始词汇表的一般标记。所有槽位将在推荐项目生成后填满。
4.3.2 Promptfor Item Recommendation.
推荐子任务旨在预测用户可能感兴趣的项目。提示设计主要增强用户偏好语义,以预测更令人满意的推荐。
The Prompt Design.
项目推荐提示由以下部分组成:原始对话历史 C C C(以词标记的形式)、特定于推荐的软标记 P r e c P_{rec} Prec(以潜在向量的形式)、融合的实体上下文 E ~ \widetilde{\mathbf{E}} E (以潜在向量的形式)以及响应模板 S S S(以词标记的形式),正式描述如下。
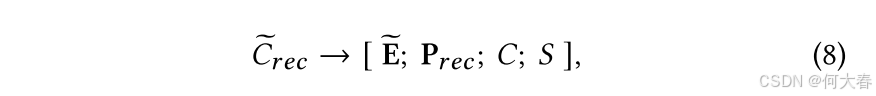
其中,特定于子任务的提示
P
r
e
c
\mathbf{P}_{rec}
Prec通过来自推荐任务的信号、知识图谱增强的实体表示
E
~
\widetilde{\mathbf{E}}
E
(公式4)、原始对话历史
C
C
C以及响应模板
S
S
S来指导预训练语言模型(PLM)。
Prompt Learning.
在上述提示设计中,唯一可调整的参数是已经预训练过的融合实体表示 E ~ \widetilde{E} E 和特定于推荐的软标记 P g e n P_{gen} Pgen。它们被表示为 Θ r e c \Theta_{rec} Θrec。我们利用增强提示的上下文 C ~ r e c \widetilde{C}_{rec} C rec来推导学习 Θ r e c \Theta_{rec} Θrec的预测损失,其正式表示为:
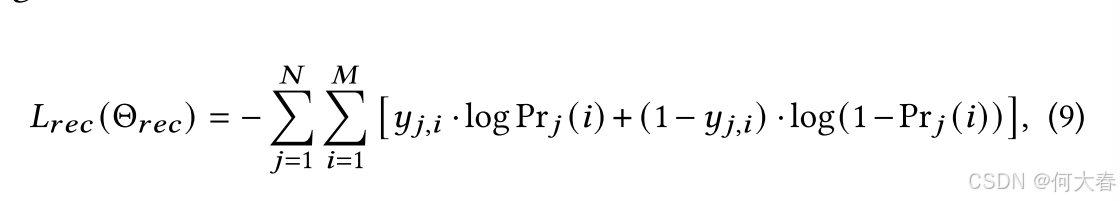
其中, N N N 是训练样本的数量(一对上下文和一个目标项目), M M M 是项目的总数, y j , i y_{j,i} yj,i 表示一个二元真实标签,当项目 i i i 是第 j j j 个训练样本的正确标签时其值为 1; Pr j ( i ) \text{Pr}_j(i) Prj(i) 是 Pr ( i ∣ C ~ r e c ( j ) ; Θ r e c ) \text{Pr}(i\mid\widetilde{C}_{rec}^{(j)};\Theta_{rec}) Pr(i∣C rec(j);Θrec) 的缩写,其计算方式与公式 5 中类似,即先对上下文化表示进行池化,然后计算 softmax 分数。
4.4 Parameter Learning
我们模型的参数分为四组,分别是基础预训练语言模型(PLM)、语义融合模块以及针对推荐和对话任务的子任务特定软标记。它们分别表示为 Θ p l m \Theta_{plm} Θplm、 Θ f u s e \Theta_{fuse} Θfuse、 Θ r e c \Theta_{rec} Θrec和 Θ g e n \Theta_{gen} Θgen。
在整个训练过程中,基础PLM的参数 Θ p l m \Theta_{plm} Θplm始终保持固定,我们只优化其余参数。首先,我们对语义融合模块的参数 Θ f u s e \Theta_{fuse} Θfuse进行预训练。给定对话历史和知识图谱(KG),我们使用固定的文本编码器RoBERTa对对话标记进行编码,使用可学习的图编码器RGCN对KG实体进行编码。然后,我们根据公式3执行语义融合以获得融合的词表示 T \mathbf{T} T,并根据公式4获得实体表示 E \mathbf{{E}} E。之后,我们基于自监督的实体预测任务对 Θ f u s e \Theta_{fuse} Θfuse进行优化。接下来,我们随机初始化子任务特定软标记 Θ r e c \Theta_{rec} Θrec和 Θ g e n \Theta_{gen} Θgen的参数,并根据公式6构建响应生成提示。我们利用来自对话任务的监督信号,根据公式7学习 Θ g e n \Theta_{gen} Θgen并生成响应模板。最后,我们根据公式8构建项目推荐提示,并利用来自推荐任务的监督信号,根据公式9学习 Θ r e c \Theta_{rec} Θrec。
5 EXPERIMENT
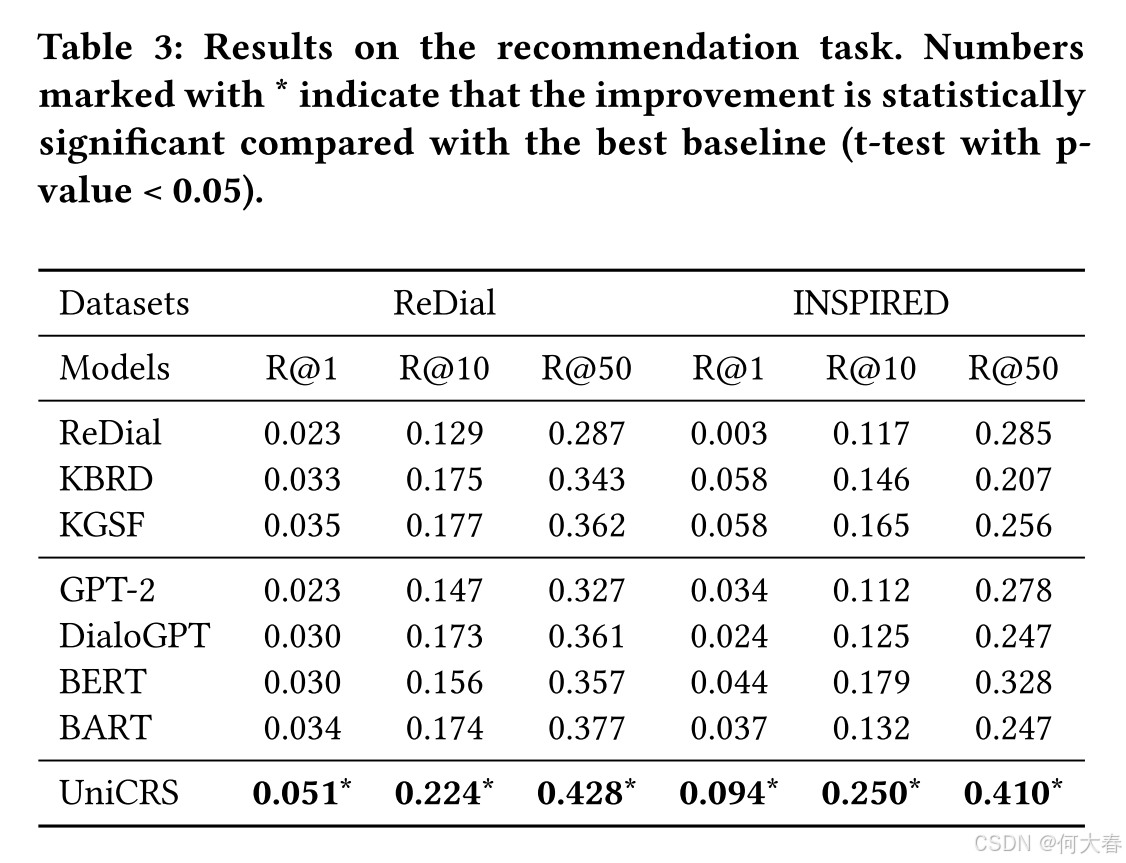
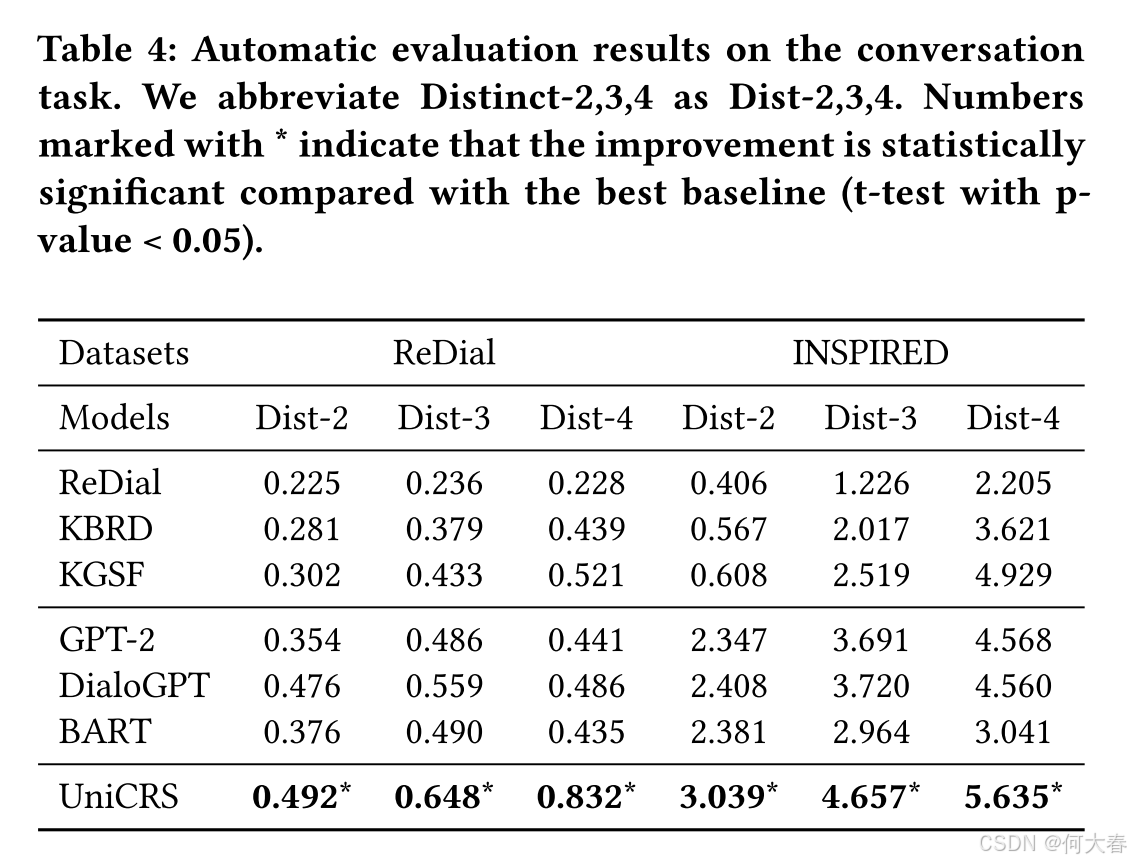
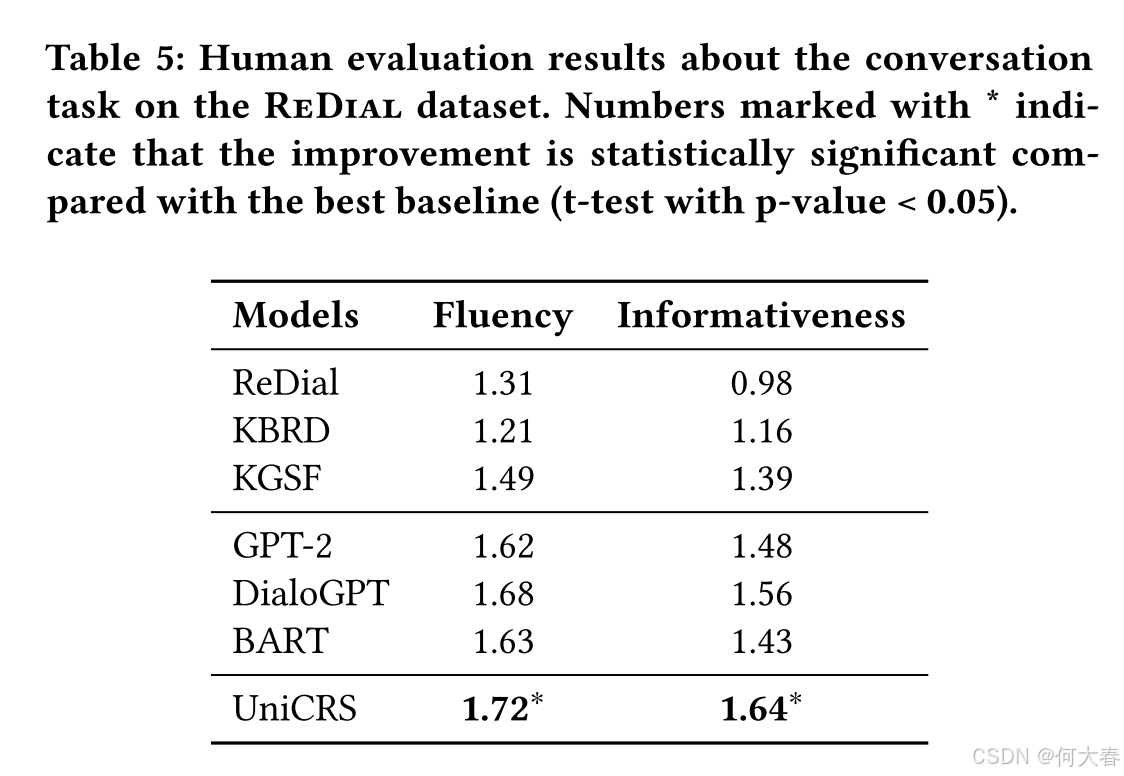
6 CONCLUSION
在这篇论文中,我们提出了一种新颖的对话推荐模型,名为 UniCRS,以统一的方式同时完成推荐和对话两个子任务。首先,我们以固定的预训练语言模型(PLM,即 DialoGPT)为骨干,利用知识增强的提示学习范式重新构建这两个子任务。接着,我们设计了多种有效的提示来支持这两个子任务,这些提示包括由预训练语义融合模块生成的融合知识表示、任务特定的软标记以及对话上下文。我们还利用对话子任务生成的响应模板作为提示的重要组成部分,以增强推荐子任务。上述提示设计能够提供关于对话上下文、任务指令和背景知识的充分信息。通过仅优化这些提示,我们的模型能够有效地完成推荐和对话两个子任务。大量实验结果表明,我们的方法优于多种竞争性的对话推荐系统(CRS)和预训练语言模型(PLM)方法,尤其是在训练数据有限的情况下。
未来,我们将把我们的模型应用于更复杂的场景,例如主题引导的对话推荐系统 [37] 和多模态对话推荐系统 [32]。我们还将考虑设计更有效的提示预训练策略,以便快速适应各种对话推荐场景。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









