







文章信息:

发表于:2023 AAAI
原文链接:https://arxiv.org/abs/2212.07767
源码:https://github.com/DongdingLin/COLA
Abstract
会话推荐系统(Conversational Recommender Systems, CRS)旨在通过自然语言对话向用户推荐合适的产品。理解用户对潜在物品的偏好以及学习高效的物品表示对于CRS至关重要。尽管已有多种尝试,但早期的研究大多基于单个对话来学习物品表示,忽略了在所有对话中体现的物品流行度。此外,由于单个对话中反映的信息有限,这些研究在有效捕捉用户偏好方面仍存在不足。受协同过滤的启发,我们提出了一种协同增强(Collaborative Augmentation, COLA)方法,以同时改进物品表示学习和用户偏好建模,从而解决这些问题。我们构建了一个从所有对话中提取的交互式用户-物品图,该图通过用户感知信息(即物品流行度)来增强物品表示。为了改进用户偏好建模,我们从训练语料库中检索相似的对话,其中涉及的物品和反映用户潜在兴趣的属性通过门控机制来增强用户表示。在两个基准数据集上的大量实验证明了我们方法的有效性。
Introduction
随着会话系统的快速发展,推荐系统有望通过自然语言对话提供高质量的推荐,即会话推荐系统(Conversational Recommender Systems, CRS)(Christakopoulou, Radlinski, and Hofmann 2016; Li et al. 2018)。由于其在高电子商务领域的重要影响,许多研究者(Liao et al. 2019; Lei et al. 2020; Gao et al. 2021; Jannach et al. 2021; Ren et al. 2021; Zhou et al. 2022)被吸引来探索CRS。
在CRS领域,大量研究(Zhang et al. 2019a; Zhou et al. 2020a; Lu et al. 2021; Deng et al. 2021; Chen et al. 2019; Wang et al. 2021; Zhou et al. 2022)聚焦于如何学习良好的物品表示以及有效捕捉用户在自然语言对话中表达的偏好。提出的方法包括强化学习(Zhang et al. 2019a; Deng et al. 2021)、预训练-微调(Chen et al. 2019; Wang et al. 2021)、对比学习(Zhou et al. 2022)等。然而,这些研究仍存在一些局限性。首先,它们主要基于单个对话学习物品表示,忽略了在许多对话(用户)中体现的物品流行度属性。这导致系统无法有效区分流行物品和仅受少数用户青睐的物品。其次,由于单个对话中反映用户对潜在物品兴趣的信息有限,它们在捕捉用户偏好方面仍存在困难。为了缓解上述问题,我们希望通过考虑用户和物品的相互影响,协同学习物品表示和建模用户偏好。然而,这在CRS中并非易事,因为用户-物品交互数据并不直接可用。
在本研究中,我们受协同过滤(Schafer et al. 2007)启发,提出了一种协同增强(COLlaborative Augmentation, COLA)方法来改进CRS。在这里,物品表示通过用户感知信息(即在所有对话中体现的流行度)进行增强。类似地,用户表示通过可能揭示用户潜在兴趣的物品感知信息进行增强。具体而言,我们首先通过从训练语料库中提取所有对话中涉及喜欢或不喜欢关系的用户-物品对,构建一个交互式用户-物品图。该图通过R-GCN(Schlichtkrull et al. 2018)进行编码,其中每个物品节点通过消息传递从不同用户节点聚合喜欢和不喜欢信息(即物品流行度)。我们采用编码输出通过加法操作增强物品表示。鉴于在CRS中,相似用户与系统对话并提供关于物品和属性的相似反馈,我们使用当前对话从训练语料库中检索相似对话(即相似用户),采用BM25(Manning, Raghavan, and Sch¨utze 2008)算法。然后,通过自注意力机制聚合前n个对话中包含的物品和相关属性,这些对话揭示了用户的潜在兴趣。我们采用聚合输出通过门控机制增强用户表示。
基于用户-物品协同增强的表示,我们通过将用户与候选物品进行匹配,并选择排名前k的物品作为推荐集来进行推荐。最后,我们采用一种广泛使用的对话生成模型作为主干,遵循现有工作(Liu et al. 2020; Zhou et al. 2022),生成适当的对话响应以回应用户。
本文的主要贡献如下:
- 我们提出了一种协同增强方法,用于帮助学习物品表示和建模用户偏好,该方法简单但有效,能够改进现有的会话推荐系统(CRS)。
- 我们构建了一个交互式用户-物品图,为物品表示学习引入流行度感知信息,并提出了一种检索增强方法用于用户偏好建模。
- 在两个CRS基准数据集上的大量实验表明,我们的方法在性能上优于多种强基线模型,验证了其。
Related Work
会话推荐系统(Conversational Recommender Systems, CRS)(Jannach et al. 2021; Sun and Zhang 2018)已成为一个新兴的研究课题,旨在通过与用户的自然语言对话提供高质量的推荐。为了推动这一领域的研究,各种数据集相继发布,例如REDIAL(Li et al. 2018)、TG-REDIAL(Zhou et al. 2020c)、INSPIRED(Hayati et al. 2020)、DuRecDial(Liu et al. 2020, 2021)等。现有研究分为推荐导向型CRS(Christakopoulou, Radlinski, and Hofmann 2016; Sun and Zhang 2018; Zhou et al. 2020b; Li et al. 2021; Ren et al. 2021; Xie et al. 2021; Zhou et al. 2020a,c)和对话导向型CRS(Li et al. 2018; Chen et al. 2019; Liu et al. 2020; Ma, Takanobu, and Huang 2021)。本文主要关注推荐导向型CRS。
现有的推荐导向型CRS主要聚焦于如何学习物品表示和建模用户偏好。为此,研究者提出了多种方法,包括强化学习(Zhang et al. 2019a; Deng et al. 2021)、预训练-微调(Chen et al. 2019; Wang et al. 2021)和对比学习(Zhou et al. 2022)。为了改进物品表示学习,Li et al. (2018) 和 Zhou et al. (2020a) 引入了领域知识图谱,并使用R-GCN(Schlichtkrull et al. 2018)对图谱中的物品进行建模。在用户偏好建模方面,Xu et al. (2020) 创建了MGCConvRex语料库,以帮助进行用户记忆推理。Xu et al. (2021) 结合属性级和物品级反馈信号,更精确地识别用户对物品的态度。此外,Li et al. (2022) 关注以用户为中心的会话推荐,通过多方面的用户建模(例如用户的当前对话会话和历史对话会话)来实现。在推荐方面,一些研究聚焦于询问物品属性(Lei et al. 2020)、澄清用户需求(Ren et al. 2021)以及推荐策略(Zhou et al. 2020b; Ma, Takanobu, and Huang 2021)。
Preliminaries
Task Definition
形式上,设 I = { e i } i = 1 m \mathcal{I} = \{e_i\}_{i=1}^m I={ei}i=1m 表示整个物品集合, H = { s t } t = 1 n \mathcal{H} = \{s_t\}_{t=1}^n H={st}t=1n 表示由用户(推荐寻求者)和会话推荐系统之间的一系列对话组成的会话,其中 s t s_t st 由用户或系统生成。给定一个对话历史,CRS的目标是从整个物品集合中选择一组满足用户需求的候选物品 I t \mathcal{I}_t It,然后生成适当的对话以回应用户。系统需要捕捉用户在历史对话中表达的偏好。在某些情况下, I t \mathcal{I}_t It 可能为空,因为系统需要询问物品属性以澄清用户的需求或兴趣。
Fundamental Framework
现有方法(Chen et al. 2019; Liao et al. 2019; Liu et al. 2020; Lu et al. 2021; Zhou et al. 2022)主要将会话推荐系统(CRS)分为两大模块:推荐模块和响应生成模块。推荐模块旨在基于对话历史捕捉用户偏好,并据此推荐合适的物品。基于推荐模块的输出,响应生成模块用于生成自然语言响应以与用户交互。总体而言,推荐模块对CRS的整体性能至关重要。
许多先前的工作(Zhou et al. 2020a; Zhang et al. 2021; Lu et al. 2021; Zhou et al. 2022)引入了外部物品导向的知识图谱(KGs)以丰富学习的物品表示。例如,广泛使用的知识图谱之一是DBpedia(Auer et al. 2007),它提供了关于物品的结构化知识事实。每个知识事实以三元组 ⟨ e 1 , r k , e 2 ⟩ ⟨e_1, r_k, e_2⟩ ⟨e1,rk,e2⟩的形式表示,其中 e 1 , e 2 ∈ E e_1, e_2 ∈ E e1,e2∈E表示实体(或物品), r k r_k rk表示它们之间的关系。为了更好地理解用户在自然语言对话中表达的偏好,一些研究(Zhou et al. 2020a; Lu et al. 2021)引入了词汇导向或常识知识图谱,例如ConceptNet(Speer, Chin, and Havasi 2017)。ConceptNet提供了词汇之间的常识关系(例如“cheerful”和“miserable”之间的反义关系),这有助于对齐对话中的词汇级信息与物品导向知识图谱中的实体级信息。在ConceptNet中,语义事实也以 ⟨ w 1 , r c , w 2 ⟩ ⟨w1, rc, w2⟩ ⟨w1,rc,w2⟩的形式存储,其中 w 1 , w 2 ∈ V w_1, w_2 ∈ V w1,w2∈V是词汇, r c r_c rc表示 w 1 w_1 w1和 w 2 w_2 w2之间的关系。
遵循上述研究,我们也采用一个物品导向的知识图谱和一个词汇导向的知识图谱作为外部数据来构建我们的基础CRS模型。在此基础上,我们通过提出的方法增强物品和用户表示。
Proposed Method
在本节中,我们提出了一种用于CRS的协同增强(COLlaborative Augmentation, COLA)方法,其概览如图1所示。我们COLA方法的关键组件以橙色和蓝色虚线框突出显示,分别代表流行度感知的物品表示增强和检索增强的用户偏好增强。基于协同增强的用户和物品表示,我们遵循现有的推荐和响应生成的基本框架。
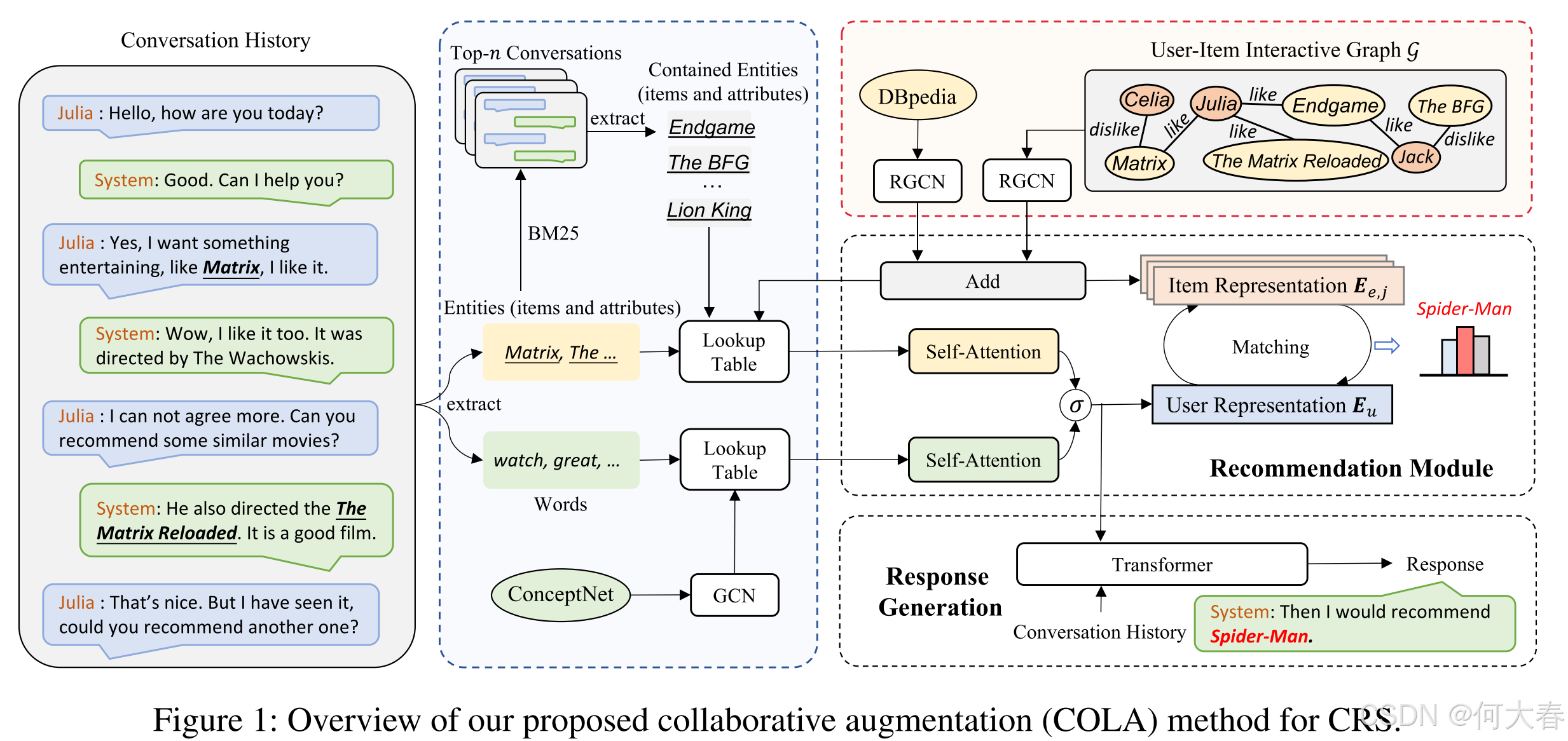
Popularity-aware Item Representation Augmentation
在介绍物品表示增强之前,我们首先采用一个物品导向的知识图谱(例如DBpedia),按照许多现有工作(Chen et al. 2019; Zhou et al. 2020a; Lu et al. 2021)的方式获取基础物品表示。具体而言,我们使用R-GCN(Schlichtkrull et al. 2018)对物品导向的知识图谱 K \mathcal{K} K进行编码。形式上, K \mathcal{K} K中每个实体 e e e的表示计算如下:
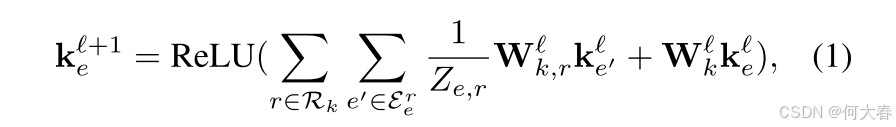
其中, k e ℓ ∈ R d \mathbf{k}_e^\ell\in\mathbb{R}^d keℓ∈Rd 是第 ℓ \ell ℓ 层中节点 e e e 的表示, d d d 是嵌入维度。 E e r \mathcal{E}_e^r Eer 表示在关系 r r r 下节点 e e e 的邻居节点集合。 W k , r ℓ \textbf{ W}_k,r^\ell Wk,rℓ 是一个可学习的、特定于关系的变换矩阵,用于处理具有关系 r r r 的邻居节点的嵌入, W k ℓ \mathbf{W} _k^\ell Wkℓ 是一个可学习的矩阵,用于变换第 ℓ \ell ℓ 层节点的表示。 Z e , r Z_e,r Ze,r 是归一化因子。ReLU(·) 是一个激活函数。在聚合知识图谱信息后,我们采用公式1中R-GCN的输出作为基础物品表示,记为 E K = { k e , 1 , k e , 2 , ⋯ , k e , m } \mathbf{E} _{\mathcal{K} }= \left \{ \mathbf{{k} } _{e, 1}, \mathbf{k} _{e, 2}, \cdots , \mathbf{k} _{e, m}\right \} EK={ke,1,ke,2,⋯,ke,m},其中 m m m 表示物品的数量。
更重要的是,我们的目标是通过用户感知信息(即在所有对话中体现的流行度)来增强基础物品表示。由于用户与系统之间的自然语言对话包含反映用户对物品及相关属性态度的特定关键词(例如“喜欢”、“享受”、“不喜欢”、“讨厌”等),我们从用户与系统的对话中提取用户提到的所有喜欢和不喜欢的物品。基于训练语料库,我们获得各种具有喜欢或不喜欢关系的用户-物品对,然后相应地构建一个交互式用户-物品图 G \mathcal{G} G(见图1)。在图 G \mathcal{G} G中,用户节点和物品节点之间的每条边表示用户的偏好(即喜欢或不喜欢),其定义如下:
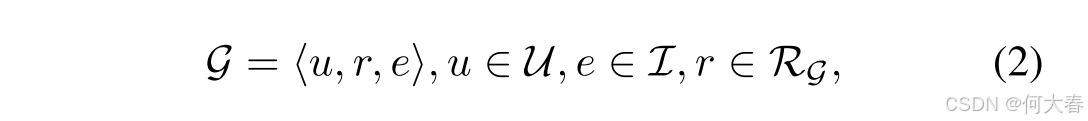
其中, U \mathcal{U} U 表示所有用户, I \mathcal{I} I 表示整个物品集合, R G = { \mathcal{R}_{\mathcal{G}}=\{ RG={“喜欢”,“不喜欢” } \} }。直观上,被更多用户喜欢(或被更少用户不喜欢)的物品节点比被更少用户喜欢(或被更多用户不喜欢)的物品节点更受欢迎。
为了获得流行度感知的物品表示,我们采用另一个R-GCN对用户-物品图 G \mathcal{G} G进行编码,具体如下:
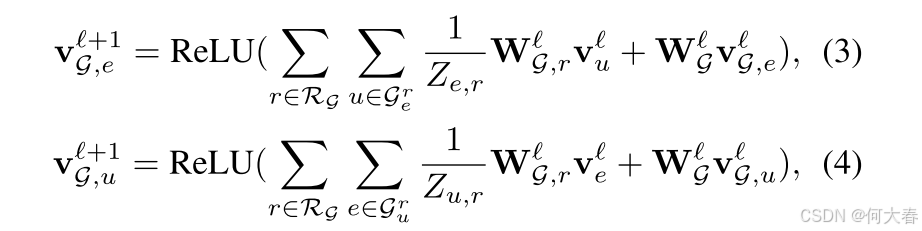
其中, v G , e , v G , u ∈ R d \mathbf{v}_{\mathcal{G},e},\mathbf{v}_{\mathcal{G},u}\in\mathbb{R}^d vG,e,vG,u∈Rd 分别是第 ℓ \ell ℓ 层中物品 e e e 和用户 u u u 的表示。 G e r , G u r \mathcal{G}_e^r,\mathcal{G}_u^r Ger,Gur 是在关系 r r r 下 e e e 和 u u u 的一跳邻居集合。 W G , r ℓ \mathbf{W}_\mathcal{G},r^\ell WG,rℓ 和 W ~ G ℓ \tilde{\mathbf{W}}_\mathcal{G}^\ell W~Gℓ 是第 ℓ \ell ℓ 层的可训练权重。 Z e , r Z_{e,r} Ze,r 和 Z u , r Z_{u,r} Zu,r 是归一化因子。根据公式3和公式4,每个物品节点通过消息传递从不同用户节点聚合喜欢和不喜欢的信息(即物品流行度)。计算完成后,我们采用基于公式3的物品表示作为流行度感知的物品表示,记为 E G = { v e , 1 , v e , 2 , ⋯ , v e , m } \mathbf{E}_{\mathcal{G}}=\{\mathbf{v}_{e,1},\mathbf{v}_{e,2},\cdots,\mathbf{v}_{e,m}\} EG={ve,1,ve,2,⋯,ve,m},其中 m m m 表示物品的数量。最后,我们通过逐元素加法操作将基础物品表示 E K \mathbf{E}_{\mathcal{K}} EK 与流行度感知的物品表示 E G \mathbf{E}_{\mathcal{G}} EG 进行增强:
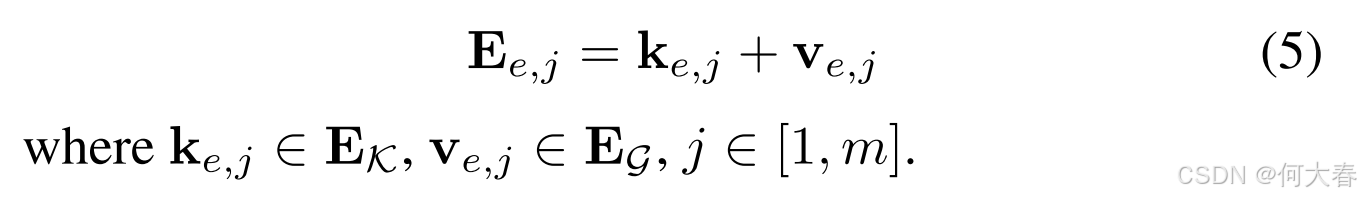
Retrieval-enhanced User Preference Augmentation
在介绍用户偏好增强之前,我们首先简要描述用户偏好建模的基础。用户对特定物品的反馈对于从自然语言对话中捕捉用户偏好至关重要。为此,我们从对话历史中提取提到的物品,并通过查找操作从整个增强的物品表示 E e E_e Ee中收集这些物品的表示,得到 E ( m ) ∈ R ℓ m × d E_{(m)} ∈ \mathbb{R}^{ℓ^m×d} E(m)∈Rℓm×d,其中 ℓ m {ℓ^m} ℓm表示对话历史中提到的物品数量, d d d表示嵌入维度。然后,为了更好地理解用户在自然语言对话中表达的偏好,我们采用一个词汇导向的知识图谱,即ConceptNet,以帮助对齐对话中的词汇级信息与物品导向知识图谱中的实体级信息,遵循现有工作(Zhou et al. 2020a; Lu et al. 2021)。具体而言,我们使用GCN(Zhang et al. 2019b)对ConceptNet C \mathcal{C} C进行编码。 C \mathcal{C} C中每个词 w w w的表示计算如下:
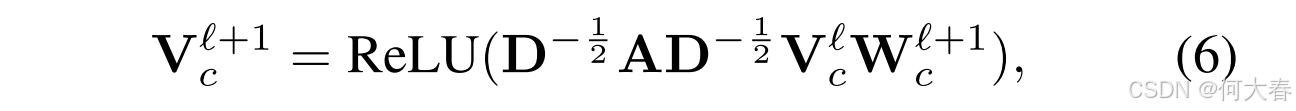
其中, V c ℓ ∈ R V × d \mathbf{V}_c^\ell\in~\mathbb{R}^{\mathbf{V}\times d} Vcℓ∈ RV×d 是节点的表示, V c ℓ − 1 \mathbf{V}_c^{\ell-1} Vcℓ−1 是前一层的表示。 W c ℓ + 1 \mathbf{W}_c^{\ell+1} Wcℓ+1 是第 ℓ + 1 \ell+1 ℓ+1 层的可学习矩阵。A 是图的邻接矩阵,D 是对角度矩阵,其元素 D [ i , i ] = ∑ j A [ i , j ] \mathbf{D}[i,i] = \sum_j\mathbf{A}[i,j] D[i,i]=∑jA[i,j]。然后,我们采用简单的查找操作来获取对话历史中出现在ConceptNet C \mathcal{C} C 中的上下文词(除停用词外)的表示,记为 C ( m ) ∈ R ℓ c × d \mathbf{C}_{(m)}\in\mathbb{R}^{\ell^c\times d} C(m)∈Rℓc×d,其中 ℓ c \ell^c ℓc 表示对话历史的长度, d d d 表示嵌入维度。
在获得表示 E ( m ) \mathbf{E}_{(m)} E(m) 和 C ( m ) \mathbf{C}_{(m)} C(m) 后,我们研究如何通过可能揭示用户潜在兴趣的物品感知信息来增强它们。直观上,相似的用户与系统对话并提供关于物品和属性的相似反馈。如图1所示,我们使用当前对话从训练语料库中检索相似对话(即相似用户),采用BM25算法(Manning, Raghavan, and Schütze 2008)。具体而言,设训练语料库中的所有对话为 D = { H i } i = 1 N D=\{\mathcal{H}_i\}_{i=1}^N D={Hi}i=1N,其中 N N N 表示对话的总数。我们提取当前对话中涉及的实体(物品和属性)作为查询 Q Q Q,然后使用BM25算法从 D D D 中检索相似对话。我们根据 Q Q Q 与 D D D 中每个对话的相似度得分选择前 n n n 个对话。这些对话中包含的实体(物品和属性)记为 E ( r ) E_{(r)} E(r)。上述过程公式化如下:
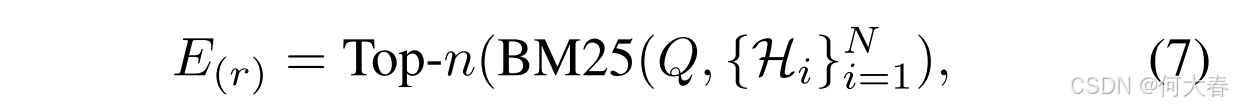
同样,我们通过查找操作从 E e \mathbf{E}_e Ee 中收集 E ( r ) \mathbf{E}_{(r)} E(r) 的表示,记为 E ( r ) \mathbf{E}_{(r)} E(r)。
给定表示 C ( m ) \mathbf{C}_{(m)} C(m)、 E ( m ) \mathbf{E}_{(m)} E(m) 和 E ( r ) \mathbf{E}_{(r)} E(r),我们介绍如何将它们结合起来以获得增强的用户偏好表示。首先,由于 E ( m ) \mathbf{E}_{(m)} E(m) 和 E ( r ) \mathbf{E}_{(r)} E(r) 是在相同的语义空间中计算的,我们通过拼接操作将它们组合在一起,然后应用自注意力操作来捕捉物品导向的用户偏好,其公式如下:
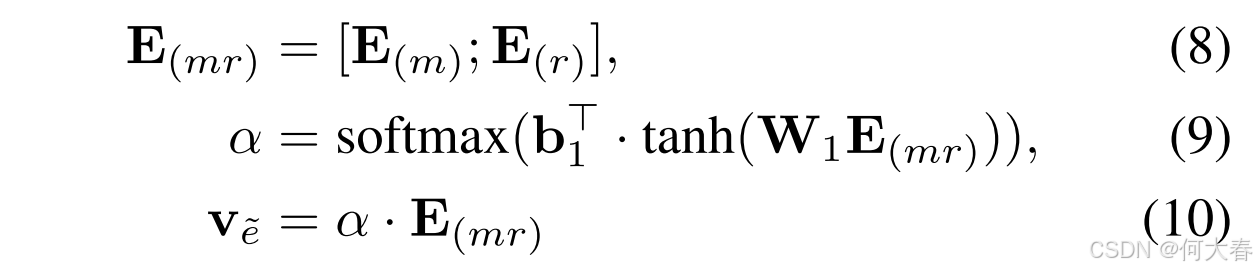 其中,[;]表示拼接操作,
W
1
\mathbf{W}_1
W1为可学习参数矩阵,
b
1
\mathbf{b}_1
b1 是可学习的偏置。其次,我们对
C
(
m
)
\mathbf{C}_{(m)}
C(m) 应用类似的自注意力操作,以更好地捕捉对话中上下文词语的语义,其公式如下:
其中,[;]表示拼接操作,
W
1
\mathbf{W}_1
W1为可学习参数矩阵,
b
1
\mathbf{b}_1
b1 是可学习的偏置。其次,我们对
C
(
m
)
\mathbf{C}_{(m)}
C(m) 应用类似的自注意力操作,以更好地捕捉对话中上下文词语的语义,其公式如下:
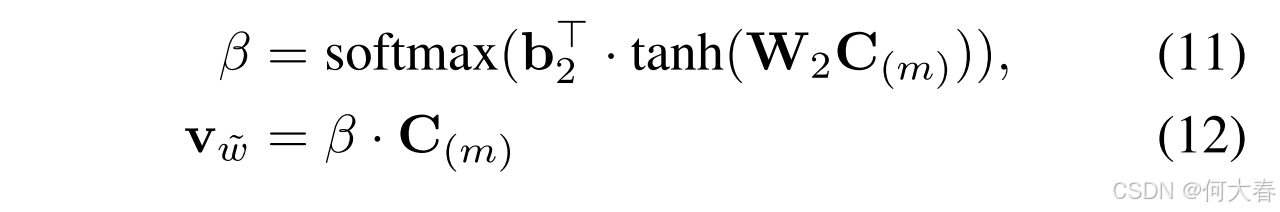
其中, β \beta β 表示反映每个词重要性的注意力权重, W 2 \mathbf{W}_2 W2 是可学习的参数矩阵, b 2 \mathbf{b}_2 b2 是可学习的偏置。
最后,我们通过门控机制融合物品导向的用户表示和词汇导向的用户表示,得到最终的用户偏好表示 E u {\mathbf{E}}_u Eu,其公式如下:
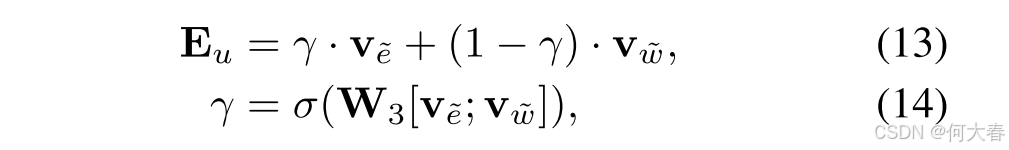
其中, W 3 \mathbf{W}_3 W3 是可学习的参数矩阵, σ \sigma σ 表示Sigmoid激活函数, ⌈ ; ⌉ \lceil;\rceil ⌈;⌉ 表示拼接操作。
Recommendation
给定增强的用户表示 E u \mathbf{E}_u Eu 和所有增强的物品表示 E e \mathbf{E}_e Ee,我们计算向用户 u u u 推荐第 j j j 个物品的概率,公式如下:
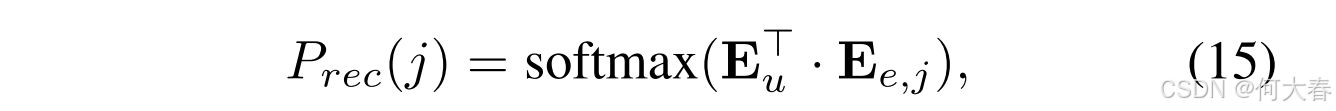
其中, E e , j \mathbf{E}_{e, j} Ee,j 是基于 E e \mathbf{E}_e Ee 的第 j j j 个物品的表示。遵循现有工作(Zhou et al. 2020a, 2022),我们采用交叉熵损失作为优化目标来学习模型参数:
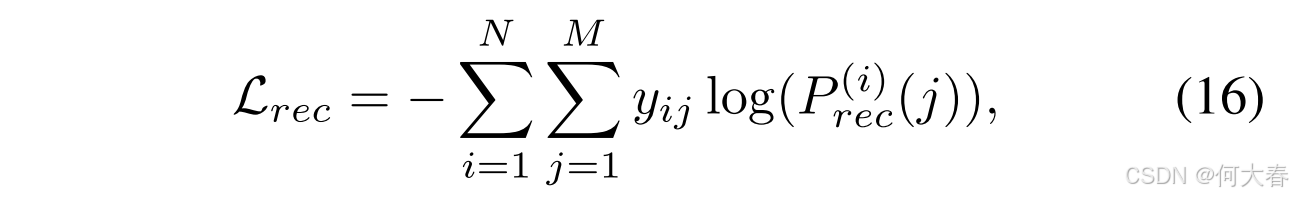
其中, N N N 是对话的数量, i i i 是对话的索引。 M M M 是物品的数量, j j j 是物品的索引。 y i j y_{ij} yij 表示物品标签。在推理过程中,我们使用公式15对物品集 I \mathcal{I} I 中的所有候选物品进行排序,并选择前 k k k 个物品作为推荐集。
Response Generation
遵循现有工作(Zhou et al. 2020a; Lu et al. 2021),我们采用广泛使用的语言生成模型Transformer(Vaswani et al. 2017)作为响应生成的主干模型。我们首先使用Transformer编码器对对话历史 H \mathcal{H} H 进行编码,得到隐藏表示 H = ( h 1 , h 2 , ⋯ , h n ) \mathbf{H}=(\mathbf{h}_1,\mathbf{h}_2,\cdots,\mathbf{h}_n) H=(h1,h2,⋯,hn)。然后,我们采用带有编码器-解码器注意力机制的Transformer解码器,其中条件生成分布近似于Zhou et al. (2020a) 的方法:
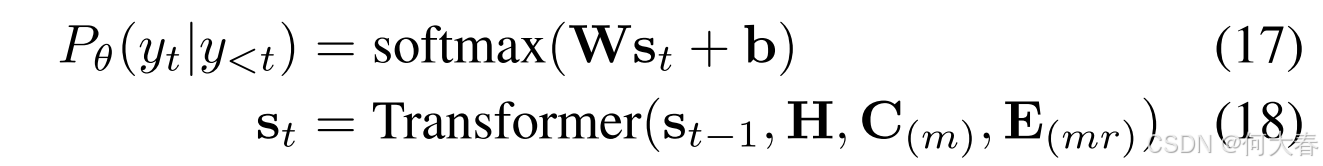
其中, s t \mathbf{s}_t st 表示第 t t t 个时间步的解码器隐藏状态, W \mathbf{W} W 和 b \mathbf{b} b 是可训练的参数。我们通过最小化负对数似然来训练Transformer语言模型,公式如下:
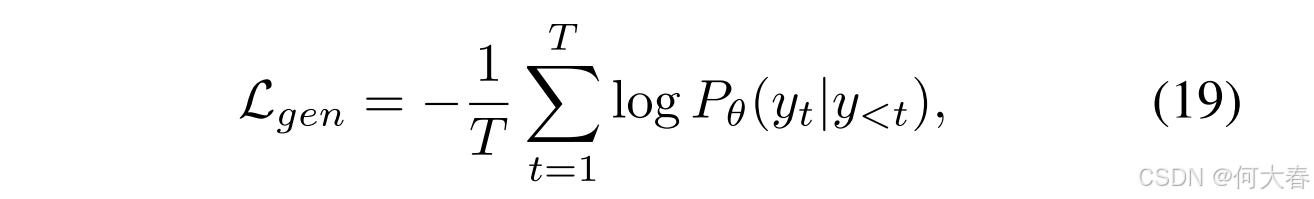
其中, T T T 是响应的长度。在推理过程中,我们使用训练好的模型逐词生成适当的对话以回应用户。
Experimental
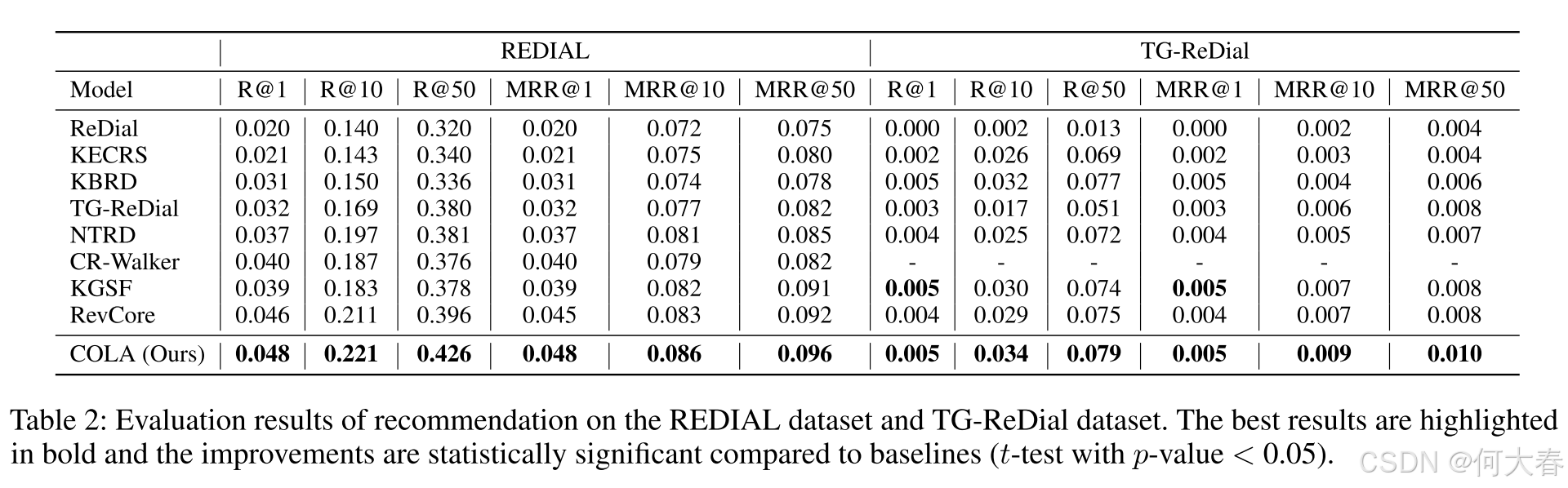
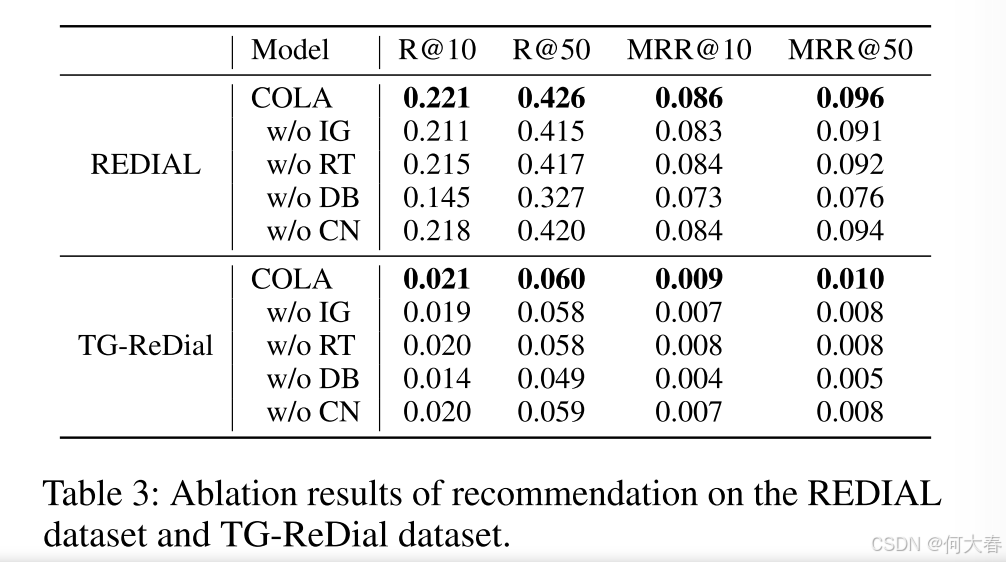
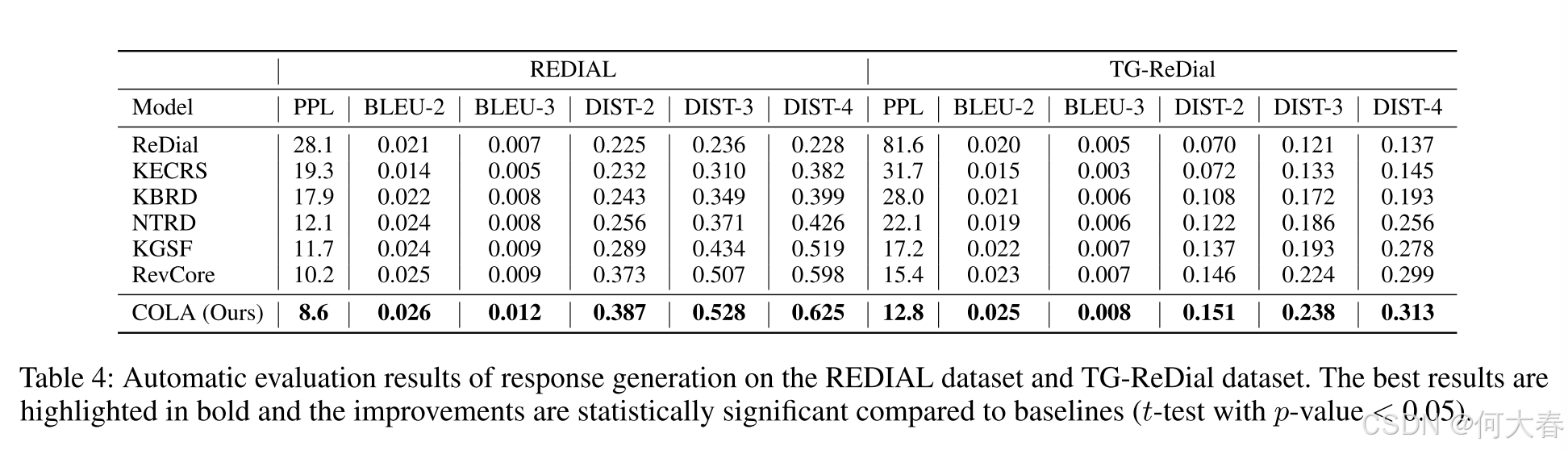
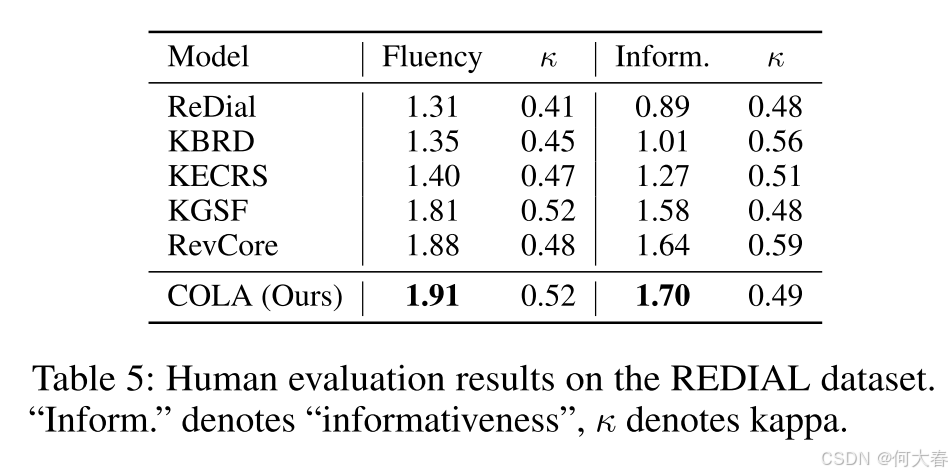
Conclusion
在本文中,我们提出了一种协同增强(COLA)方法,旨在提升对话推荐系统的性能。我们的COLA方法通过对项目表征注入用户感知信息,以及对用户偏好表征注入项目感知信息来实现增强。具体而言,我们构建了一个交互式用户-项目图,为项目表征学习引入流行度感知信息,并提出了一种基于检索增强的方法用于用户偏好建模。实验结果表明,我们的方法显著优于多种强基线模型,验证了其有效性。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









