






Logistic回归虽然带有“回归”,但却是一个分类算法,分类算法是指可以根据包含正确答案给定数据集(训练集),来预测离散的值。
我们尝试预测目标变量的值,肯定是一个离散的值,这里以二元分类为例,
的取值可以为0或1
其中用0表示的类称为“负类”(Negative Class),而用1表示的类被称为“正类”(Positive Class)。
如果采用之前的线性回归算法的假设函数,当输入变量很大或很小时,根据线性的关系可能会导致目标变量
的值远大于1或远小于0,如下图所示
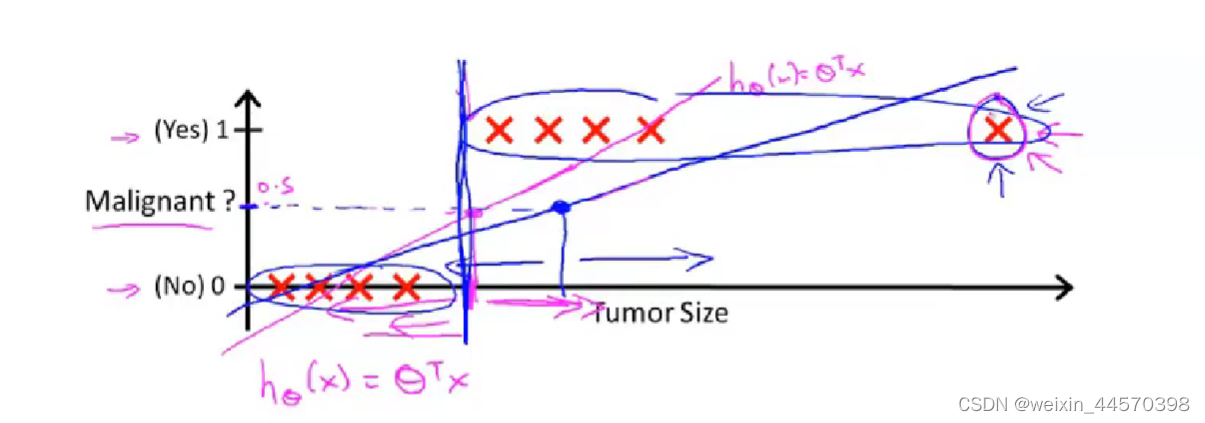
而Logistic算法就是让输出的目标变量,使假设函数满足
和线性回归一样,Logistic回归同样有假设函数和代价函数。
1、假设函数
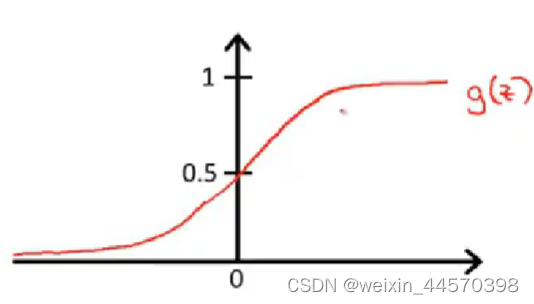
为了使假设函数,引入一个新的函数
,称为Sigmoid函数或者Logistic函数。
当时
当时
因为的导数
所以 在
上单调递增。
又因为的二阶导数
所以当时,
,
为凸函数,当
时,
,
为凹函数。
故,其图像大致为
将线性回归的假设函数(也可以是多项式回归的假设函数)代入,可以得到Logistic回归的假设函数
这样假设函数也属于
。
该假设函数的意义为,当输入一个特征向量,假设函数
输出的值为
的概率,既为
2、代价函数
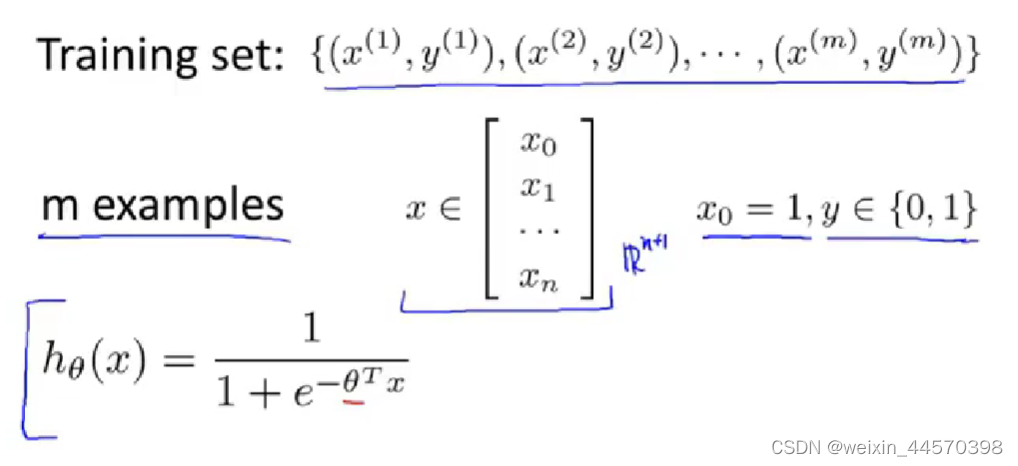
训练集:,有
个训练样本
其中
输入变量为
维向量,有
个特征,
,目标变量
假设函数
为了使梯度下降法更好的工作,我们应该使代价函数为凸函数,避免梯度下降法陷入局部最小,而达不到全局最小。
故代价函数为
当时,在输入特征向量
后,假设函数
越趋向于1
代价函数越趋向于0,说明该假设函数越拟合训练集。
假设函数越趋向于0
代价函数越趋向于
,说明该假设函数误差越大。
同理可得,当时,在输入特征向量
后,假设函数
越趋向于0
代价函数越趋向于0,说明该假设函数越拟合训练集。
假设函数越趋向于1
代价函数越趋向于
,说明该假设函数误差越大。
因为,是两个离散的值,所以我们可以简化代价函数为
这和上面的代价函数完全等价,但不必写成分段形式,最终我们可以写出代价函数为
3、梯度下降法及优化
为了得出,依旧采用梯度下降法,梯度下降法的公式和之前的一样
因为最终的代价函数略微有点复杂,我们先将假设函数
代入代价函数
再对代价函数求偏导,看最终结果能不能化简
把常数省略,最后得出梯度下降的公式为
将梯度下降法同时作用在所有上。
在实际运用中可以选择其他优化算法来计算
- 共轭梯度法
- BFGS
- L-BFGS
上述三种方法不需要选择学习率,在给出代价函数
和偏导数
后,这些算法都有一个智能内循环,称为线搜索算法,它可以自动尝试不同的学习率
,并自动选择一个最优的
,甚至在每次迭代过程中都会选择合适的
,就结果而言,这些算法的收敛速度远大于梯度下降法。
4、决策边界
在利用梯度下降法计算出后,把对应的
向量带入到假设函数中,之前提到假设函数根据输入的特征,计算出的值是
的概率,当
我们认为,而
反之则认为。
又因为单调递增,所以当
既在的上方,认为是
的范围
而
在的下方,认为是
的范围。
因此就是假设函数
的决策边界,决策边界是假设函数的属性,而不是训练集的属性。一旦确定,和训练集无关。
5、多元分类
上面所讲的都是二元分类问题,,但在实际情况下可能并不只是二元分类,可能需要分成好几类,则需要的离散值也会随之增多,既n元分类
这里以三元分类为例,有两个特征,和
,分成三个类别,如下图所示
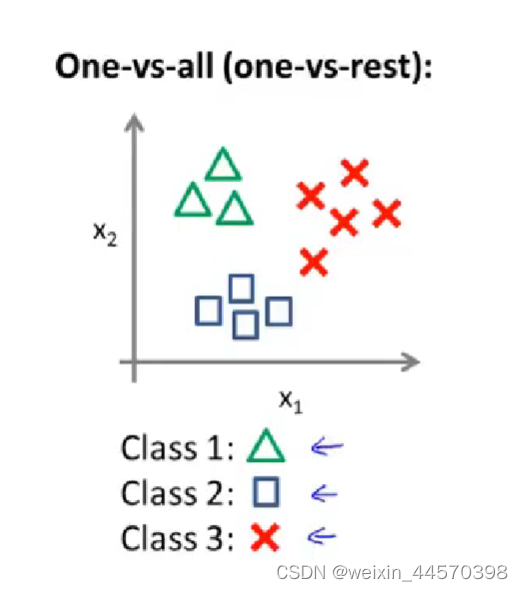
我们需要将这个训练集转化为三个独立的二元分类问题,先从类别1开始
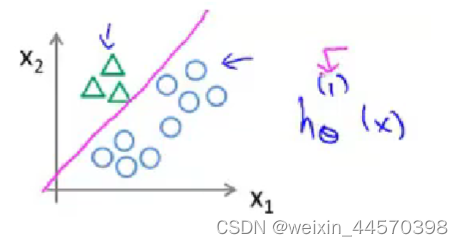
把类别1设置为正类别,其余的设置为负类别.
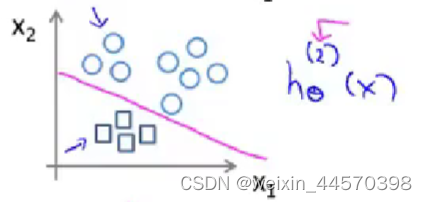
把类别2设置为正类别,其余设置为负类别。
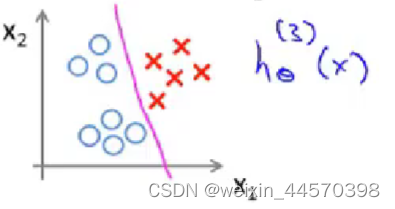
把类别3设置为正类别,其余设置为负类别。
这样就拟合出了三个假设函数,有三条决策边界,每一个假设函数计算出的值都是该类别作为正类别时的概率,既
最后我们我们为了预测,给定一个新的输入特征向量,期望获得的目标变量就是三个假设函数中的最大值,表示落在哪个区域的概率最大,既计算
对于多元分类问题,我们还可以采用其他的假设函数,假设有个类别
其中
每个输出类别的参数
都不一样,但是
和二元分类一样,依然表示输出为该类别的概率
目标变量为一个向量,属于第
个类别时,
,其余都是
,表示为向量形式为
因此代价函数为

















 2574
2574

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









