







 本文介绍了一种自动机器学习框架AutoField,用于深度推荐系统中特征的选择。通过设计可微控制器网络,智能调整特征字段的使用概率,避免冗余参数和人工干预。实验结果证明了框架在提升推荐性能方面的有效性。研究了其可转移性、关键组件和参数敏感性。
本文介绍了一种自动机器学习框架AutoField,用于深度推荐系统中特征的选择。通过设计可微控制器网络,智能调整特征字段的使用概率,避免冗余参数和人工干预。实验结果证明了框架在提升推荐性能方面的有效性。研究了其可转移性、关键组件和参数敏感性。
AutoField: Automating Feature Selection in Deep Recommender Systems
WWW’ 22
摘要
特征质量对推荐性能有重要影响。因此,特征选择是开发基于深度学习的推荐系统的关键过程。然而,大多数现有的深度推荐系统都专注于设计复杂的神经网络,而忽略了特征选择过程。通常,他们只是将所有可能的特征输入到他们提出的深度架构中,或者由人类专家手动选择重要特征。前者导致非平凡的嵌入参数和额外的推理时间,而后者需要大量的专家知识和人力。在这项工作中,我们提出了一个 AutoML 框架,该框架可以以自动方式自适应地选择基本特征字段。具体来说,我们首先设计了一个可微控制器网络,它能够自动调整选择特定特征场的概率;然后,仅使用选定的特征字段来重新训练深度推荐模型。在三个基准数据集上进行的大量实验证明了我们框架的有效性。我们进行了进一步的实验来研究其特性,包括可转移性、关键组件和参数敏感性
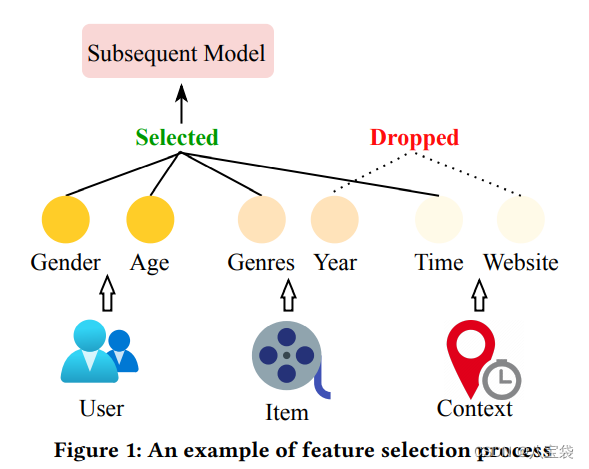
如图,主要是一种取舍项目特征的方法,想看看怎么实现的,比较感兴趣。
方法
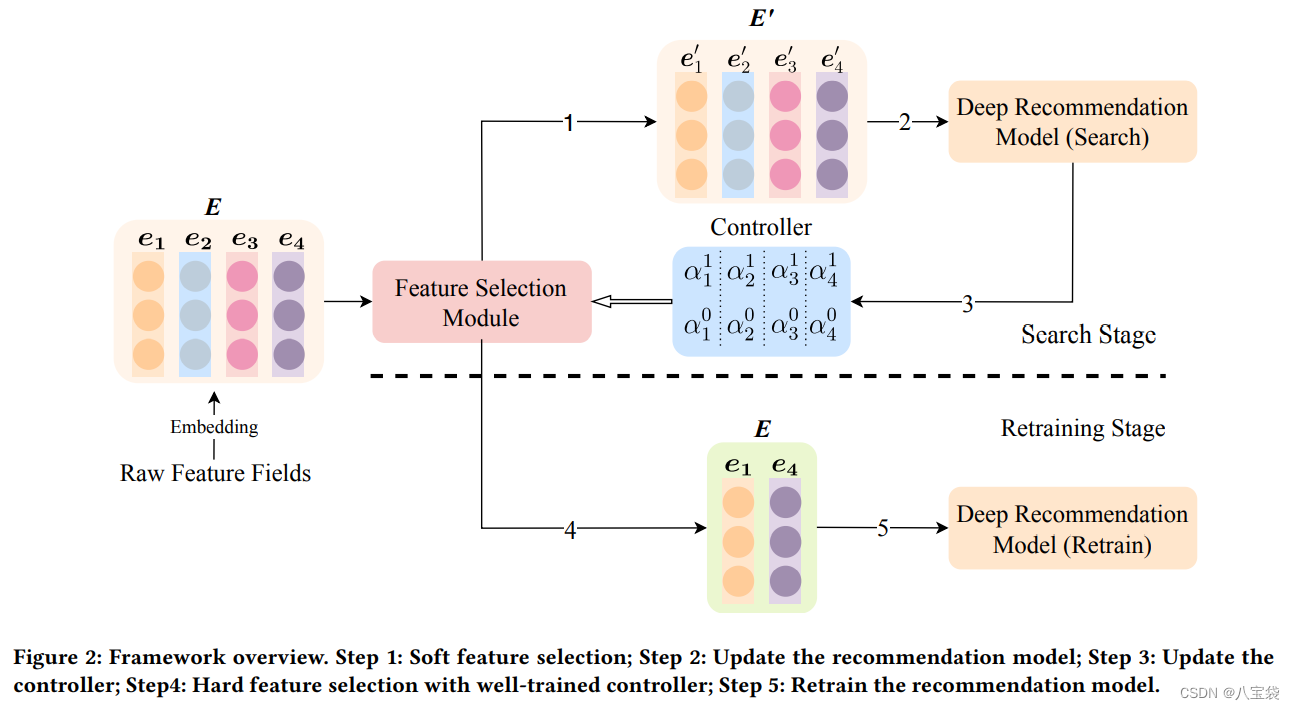
1. 总览
2. Embedding Layer
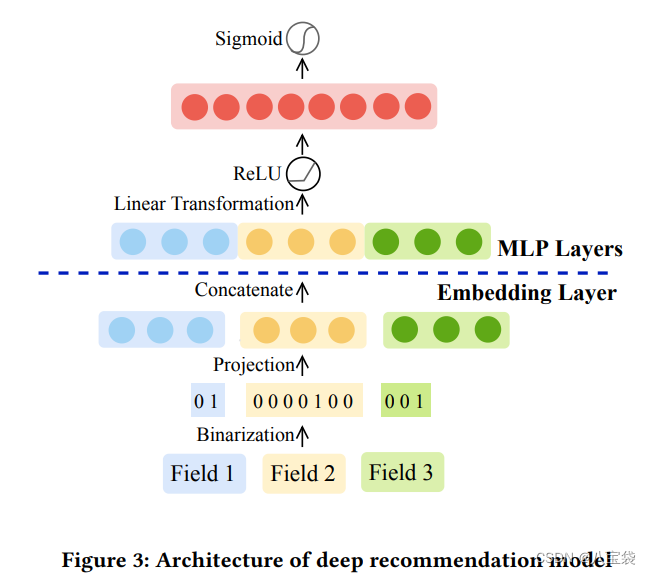
1)Binarizion: One-hot类似,就是把特征的各种取值作为新的特征,比如性别分男女,可以转化为:[1,0], [0,1].
2)Projection: 就是特征One-hot乘上一个投影矩阵embedding化.
3)Concatenate: 拼接;
4)Linear Transformation: MLP层;
5)Activation: 最后用某激活函数(图里是Sigmoid)转化为
y
^
\hat y
y^.
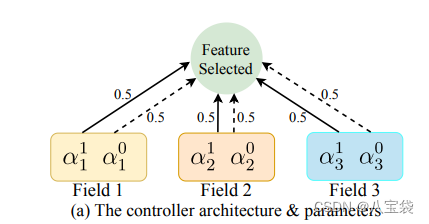
3. Controller
如何控制
N
N
N个向量的取舍呢?作者定义了
N
N
N个2维向量
(
a
n
1
,
a
n
0
)
(a_n^1,a_n^0)
(an1,an0),分别代表各自特征的留/舍. 如图,初始化是(0.5,0.5).
在训练过程中,predictive features (如Field 1,3)的
a
1
1
a_1^1
a11增加,即留下的概率增加:
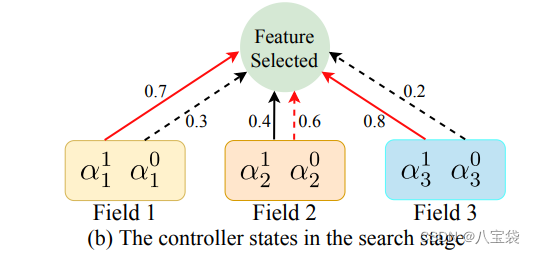
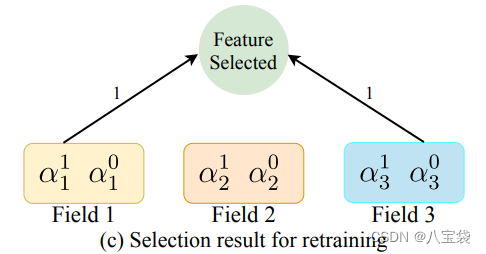
最后,很好理解,取概率高的那个,如下图,1,3留下,2就drop.
原理理解了,下面来看看符号系统,如何实现上述的操作。
由于Embedding Layer的符号系统我跳过了,所以直接给出来解释:
E
=
[
e
1
,
e
2
,
…
,
e
N
]
E=[e_1, e_2,\dots, e_N]
E=[e1,e2,…,eN] —— The final embedding of the user-item interaction data.
这里作者写的是 “user-item interaction data”. 我的理解是,就是一个item吧。
每个
e
e
e是经过投影的每个特征向量表示。
现在开始Controller部分:
e
n
′
=
(
a
1
1
⋅
1
+
a
1
0
⋅
0
)
⋅
e
n
e^{\prime}_n=(a_1^1·1+a_1^0·0)·e_n
en′=(a11⋅1+a10⋅0)⋅en
E
′
=
[
e
1
′
,
e
2
′
,
…
,
e
N
′
]
E^{\prime}=[e_1^{\prime}, e_2^{\prime},\dots, e_N^{\prime}]
E′=[e1′,e2′,…,eN′]
大概就是直接用概率“稀释”一下向量,作者说这是一种soft selection, 对于这种概率选择问题,需要一个hard的方法,这里介绍了一种Gumbel-Max trick, 详见这里【一文学会】Gumbel-Softmax的采样技巧。
- 为什么不直接softmax?
因为对于softmax, [0.005, 0.995], [0.45, 0.55],对于类别选择的结果是一样的,都是选择后者,但是在概率上,这两种还是有区别的,所以为了体现概率的含义,采用gumbel分布。
- Gumbel-Max的缺点?
没有梯度,无法求导
所以加上softmax,即为:Gumbel-Softmax.
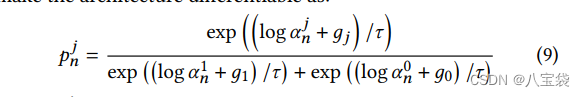
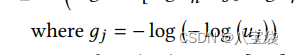
这个是文中的式子,
τ
\tau
τ是大于零的参数,控制soft程度,越大,生成的分布就越平滑;
g
g
g是独立同分布的标准Gumbel分布的随机变量;
a
a
a就是对应概率了;最后得到的是
p
n
j
p_n^j
pnj:第n个特征取/舍(j=1/0)的概率。
OK,最后:
e
n
′
=
(
p
n
1
⋅
1
+
p
n
0
⋅
0
)
⋅
e
n
=
p
n
1
e
n
e_n^{\prime}=(p_n^1·1+p_n^0·0)·e_n=p_n^1e_n
en′=(pn1⋅1+pn0⋅0)⋅en=pn1en
这个Gumbel分布大概这样。
4. Retraining Stage
作者:搜索阶段我们把所有特征都放进模型,因此次优特征会伤害模型。(Why???)
为了解决这个,就需要重新训练整个模型。在上一阶段训练结束后,所有特征最终的(a1,a2)都得到了,然后选出a1最高的K个特征来重新训练模型,并且调整MLP层的输出层大小,从Nxd缩小到Kxd当然这个K就是一个超参数了。
5. 优化

binary cross-entropy loss.
y
^
\hat y
y^就是MLP层的输出,和用户评分对标,最后的评价指标也是AUC.
总结
实验就不具体看了,还是学到了一种新思路,对特征进行取舍,然后Gumbel-Softmax的方法。

















 868
868

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









