







DataFrame 和 DataSet 是Spark SQL两大分布式数据结构,是学习Spark SQL 必不可少的内容
Spark SQL的发展
Spark SQL前身是Shark,Shark则是使用Hive的结构,把底层计算逻辑换成SparkCore而已,然后需要依赖于Hive的发展,2014年提出,把SparkSQL独立出来 以及提供Hive On Spark
Spark 1.0 RDD出现
Spark 1.4 DataFrame出现
Spark 1.6 DataSet 出现
在之后的Spark发展中,有可能DataSet 会成分布式数据集唯一出口
介绍
DataFrame:
在RDD的基础上以表的形式,把RDD加上Schame,每个数据作为表的一行,这个表的每列都有字段及类型,可以按表的形式查询
DataSet:
在RDD上,具有强类型,使用sql的方式,也就是把每一行都强类型化
DataFrame的创建方式:
通过数据源进行创建
从一个存在的RDD进行转换
从Hive table中进行查询返回
notice:如果spark从内存中获取数据,那么就可以知道数据的类型,如果是数字,默认是Int,但是从文件中读取数字,不知道是什么类型,默认是bigInt,可以和long转换,但是不能和Int转换
DataFrame中通过createTempView 或createOrReplaceTempView 创建的临时表,只能是在当前session内有效,spark.newSession可以开启一新session,如果想要当前全局内有效,则需要创建当前应用全局临时表,spark.createGlobalTempView 或者已存在的情况下spark.createOrReplaceGlobalTempView来创建全局临时表,但是访问时需要加一个 global_temp.表名
DSL语法
DSL(domain-specific language)语法
使用DSL语法进行查询,则就不用创建临时表了,可以直接以Api的方式访问
user.select(“age”).show
user.printSchema
如果需要用到字段查询做计算,可以用"字段“来取值user.select("字段“ 来取值
user.select("字段“来取值user.select("age"+1).show
也可以用‘字段 单引号来代替 $“字段”
user.select('age +1).show
user.filter('age>19).show
user.groupBy('age).count.show
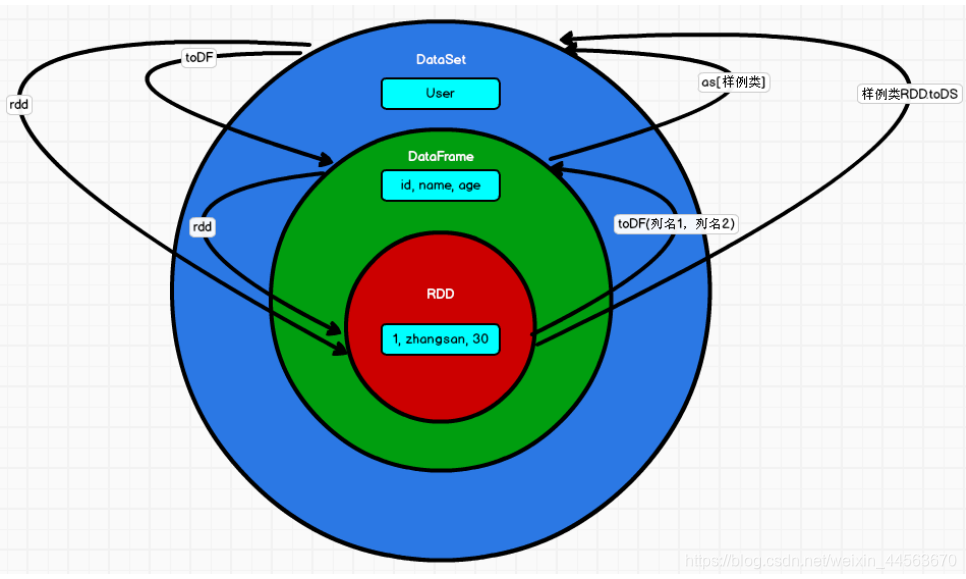
RDD是数据本身,关心的是数据本身,DataFrame则是有schame,二维表格,有字段类型对应上。
RDD–>DataFrame (toDF("字段类型”))
DataFrame -->RDD (DataFrame.rdd,得到的RDD的类型是ROW)
val df3=rdd.toDF(“id”) (rdd转换成 DataFreame,由于RDD中的数据已经有类型,所以转换的时候不需要指定其类型)
val rdd2=df3.rdd DataFrame转换成RDD,RDD的泛型是Row
DataSet 与 DataFrame 转换
DataFrame --> DataSet (DataFrame.as[样例类])val ds=df.as[user]
DataSet --> DataFrame (DataSet.toDF) val df2=ds.toDF
DataSet 与 RDD转换
RDD --> DataSet (RDD.toDS,需要RDD中有强类型) val ds =rdd.toDS
DataSet --> RDD val rdd2=ds.rdd
转换关系图如下:

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









