







 本文详细介绍了PyTorch中训练和测试时model的train/eval模式,权重初始化方法,以及Variable的重要属性如detach(),强调了在训练和推理过程中如何管理和控制梯度计算,对理解PyTorch的自动求导机制和优化过程有较大帮助。
本文详细介绍了PyTorch中训练和测试时model的train/eval模式,权重初始化方法,以及Variable的重要属性如detach(),强调了在训练和推理过程中如何管理和控制梯度计算,对理解PyTorch的自动求导机制和优化过程有较大帮助。
[Pytorch]Pytorch 细节记录(转)
文章来源 https://www.cnblogs.com/king-lps/p/8570021.html
1. PyTorch进行训练和测试时指定实例化的model模式为:train/eval
eg:



class VAE(nn.Module): def __init__(self): super(VAE, self).__init__() ... def reparameterize(self, mu, logvar): if self.training: std = logvar.mul(0.5).exp_() eps = Variable(std.data.new(std.size()).normal_()) return eps.mul(std).add_(mu) else: return mu model = VAE() ... def train(epoch): model.train() ... def test(epoch): model.eval()
eval即evaluation模式,train即训练模式。仅仅当模型中有Dropout和BatchNorm是才会有影响。因为训练时dropout和BN都开启,而一般而言测试时dropout被关闭,BN中的参数也是利用训练时保留的参数,所以测试时应进入评估模式。
(在训练时,?和?2是在整个mini-batch 上计算出来的包含了像是64 或28 或其它一定数量的样本,但在测试时,你可能需要逐一处理样本,方法是根据你的训练集估算?和?2,估算的方式有很多种,理论上你可以在最终的网络中运行整个训练集来得到?和?2,但在实际操作中,我们通常运用指数加权平均来追踪在训练过程中你看到的?和?2的值。还可以用指数加权平均,有时也叫做流动平均来粗略估算?和?2,然后在测试中使用?和?2的值来进行你所需要的隐藏单元?值的调整。在实践中,不管你用什么方式估算?和?2,这套过程都是比较稳健的,因此我不太会担心你具体的操作方式,而且如果你使用的是某种深度学习框架,通常会有默认的估算?和?2的方式,应该一样会起到比较好的效果) -- Deeplearning.ai
2. PyTorch权重初始化的几种方法
class discriminator(nn.Module): def __init__(self, dataset = 'mnist'): super(discriminator, self).__init__() 。... self.conv = nn.Sequential( nn.Conv2d(self.input_dim, 64, 4, 2, 1), nn.ReLU(), ) ... self.fc = nn.Sequential( nn.Linear(32, 64 * (self.input_height // 2) * (self.input_width // 2)), nn.BatchNorm1d(64 * (self.input_height // 2) * (self.input_width // 2)), nn.ReLU(), ) self.deconv = nn.Sequential( nn.ConvTranspose2d(64, self.output_dim, 4, 2, 1), #nn.Sigmoid(), # EBGAN does not work well when using Sigmoid(). ) utils.initialize_weights(self) def forward(self, input): ... def initialize_weights(net): for m in net.modules(): if isinstance(m, nn.Conv2d): m.weight.data.normal_(0, 0.02) m.bias.data.zero_() elif isinstance(m, nn.ConvTranspose2d): m.weight.data.normal_(0, 0.02) m.bias.data.zero_() elif isinstance(m, nn.Linear): m.weight.data.normal_(0, 0.02) m.bias.data.zero_()
def init_weights(m): print(m) if type(m) == nn.Linear: m.weight.data.fill_(1.0) print(m.weight) net = nn.Sequential(nn.Linear(2, 2), nn.Linear(2, 2)) net.apply(init_weights)
def weights_init(m): classname = m.__class__.__name__ if classname.find('Conv') != -1: m.weight.data.normal_(0.0, 0.02) elif classname.find('BatchNorm') != -1: m.weight.data.normal_(1.0, 0.02) m.bias.data.fill_(0) net.apply(weights_init)
class torch.nn.Module 是所有神经网络的基类。
modules()返回网络中所有模块的迭代器。
add_module(name, module) 将一个子模块添加到当前模块。 该模块可以使用给定的名称作为属性访问。
apply(fn) 适用fn递归到每个子模块(如返回.children(),以及自我。
3. PyTorch 中Variable的重要属性
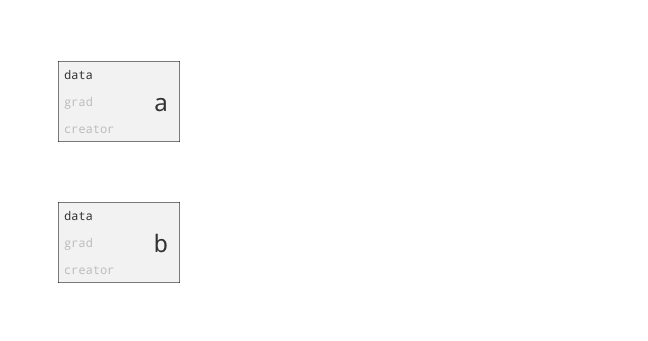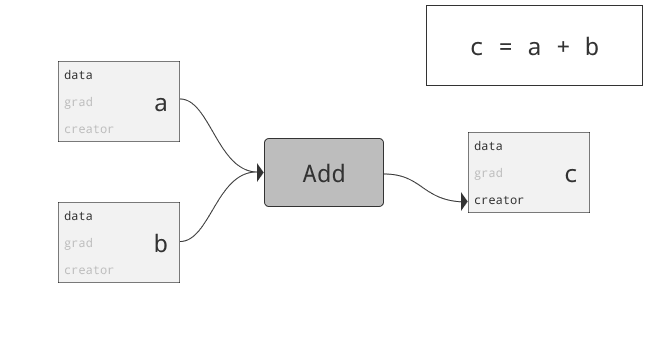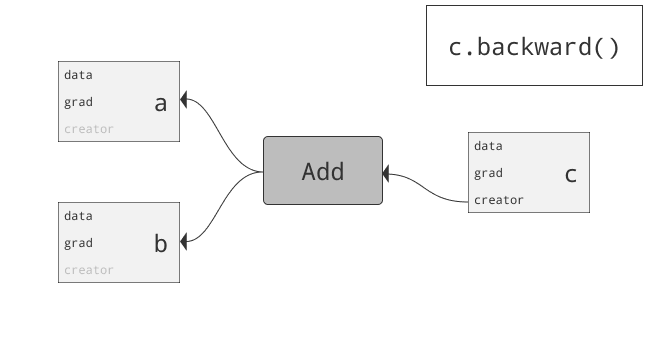
class torch.autograd.Variable
为什么要引入Variable?首先回答为什么引入Tensor。仅仅利用numpy也可以实现前向反向操作,但numpy不支持GPU运算。而Pytorch为Tensor提供多种操作运算,此外Tensor支持GPU。问题来了,两三层网络可以推公式写反向传播,当网络很复杂时需要自动化。autograd可以帮助我们,当利用autograd时,前向传播会定义一个计算图,图中的节点就是Tensor。图中的边就是函数。当我们将Tensor塞到Variable时,Variable就变为了节点。若x为一个Variable,那x.data即为Tensor,x.grad也为一个Variable。那x.grad.data就为梯度的值咯。总结:PyTorch Variables与PyTorch Tensors有着相同的API,Tensor上的所有操作几乎都可用在Variable上。两者不同之处在于利用Variable定义一个计算图,可以实现自动求导!
重要的属性如下:
requires_grad
指定要不要更新這個變數,對於不需要更新的變數可以把他設定成False,可以加快運算。
Variable默认是不需要求导的,即requires_grad属性默认为False,如果某一个节点requires_grad被设置为True,那么所有依赖它的节点requires_grad都为True。
在用户手动定义Variable时,参数requires_grad默认值是False。而在Module中的层在定义时,相关Variable的requires_grad参数默认是True。
在计算图中,如果有一个输入的requires_grad是True,那么输出的requires_grad也是True。只有在所有输入的requires_grad都为False时,输出的requires_grad才为False。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 15万+
15万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









